ADALINE
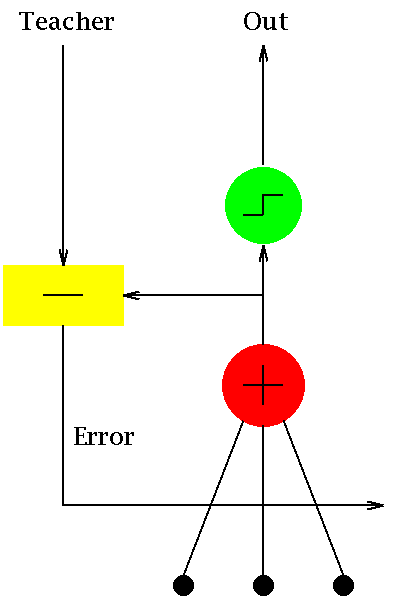

![단일 ADALINE 유닛의 회로도^1 ] ADALINE(** 적응 선형 뉴런**(Adaptive Linear Neuron) 또는 이후 적응 선형 요소(Adaptive Linear Element))은 초기 단일 계층 인공 신경망이자 이를 구현한 물리적 장치의 이름이다.[^6][^2][^1][^7][^8] 1960년 스탠퍼드 대학교의 버나드 위드로 교수와 그의 박사과정 학생 마르시안 호프가 개발하였다. 퍼셉트론을 기반으로 하며, 가중치, 편향, 합산 함수로 구성된다. 가중치와 편향은 가변저항기("손잡이 ADALINE"에서 볼 수 있음)로 구현되었으며, 이후에는 메미스터로 구현되었다. 적응 신호 처리, 특히 적응 잡음 필터링 분야에서 광범위하게 사용되었다.[^9]
{kind=link}
Adaline과 표준(로젠블랫) 퍼셉트론의 차이점은 학습 방식에 있다. Adaline 유닛의 가중치는 헤비사이드 함수를 적용하기 전에(그림 참조) 교사 신호에 맞추어 조정되지만, 표준 퍼셉트론 유닛의 가중치는 헤비사이드 함수를 적용한 후에 올바른 출력에 맞추어 조정된다.
ADALINE 유닛의 다계층 네트워크는 MADALINE이라고 한다.
정의
Adaline은 여러 노드를 가진 단일 계층 신경망으로, 각 노드는 여러 입력을 받아 하나의 출력을 생성한다. 다음 변수가 주어졌을 때:
- \boldsymbol{x}, 입력 벡터
- \boldsymbol{w}, 가중치 벡터
- N, 입력의 수
- b, 편향값
- o, 모델의 출력,
출력은 다음과 같다:
o=\sum_{n=1}^{N} x_n w_n + b
여기서 x_0=1이고 w_0=b라고 추가로 가정하면, 출력은 다음과 같이 더 간단해진다:
o=\sum_{n=0}^{N} x_n w_n
학습 규칙
ADALINE이 사용하는 학습 규칙은 경사 하강법의 특수한 경우인 LMS("최소 평균 제곱") 알고리즘이다.
다음이 주어졌을 때:
- \eta, 학습률
- o, 모델 출력
- y, 목표값
- E=(y - o)^2, 오차의 제곱,
LMS 알고리즘은 가중치를 다음과 같이 갱신한다:
\boldsymbol{w} \leftarrow \boldsymbol{w} + \eta(y - o)\boldsymbol{x}
이 갱신 규칙은 오차의 제곱인 E를 최소화하며,[^10] 사실상 선형 회귀에 대한 확률적 경사 하강법 갱신이다.[^11]
MADALINE
MADALINE(Many ADALINE[^3])은 분류를 위한 3층(입력, 은닉, 출력) 완전 연결 순방향 신경망 구조로, 은닉층과 출력층에 ADALINE 유닛을 사용한다. 즉, 활성화 함수는 부호 함수이다.[^12] 이 3층 네트워크는 메미스터를 사용한다. 부호 함수는 미분 불가능하므로, 역전파를 사용하여 MADALINE 네트워크를 훈련할 수 없다. 따라서 Rule I, Rule II, Rule III라 불리는 세 가지 훈련 알고리즘이 제안되었다.
여러 차례 시도에도 불구하고, MADALINE 모델에서 단일 가중치 층 이상을 훈련하는 데 성공하지 못했다. 이는 Widrow가 1985년 유타주 스노버드에서 열린 학회에서 역전파 알고리즘을 접하기 전까지 계속되었다.[^13]
MADALINE Rule 1 (MRI) - 이 중 첫 번째는 1962년으로 거슬러 올라간다.[^4] 이것은 두 개의 층으로 구성된다: 첫 번째 층은 ADALINE 유닛으로 이루어져 있으며(i번째 ADALINE 유닛의 출력을 o_i라 하자), 두 번째 층에는 두 개의 유닛이 있다. 하나는 모든 o_i를 입력받아, 양수가 음수보다 많으면 +1을, 그 반대이면 -1을 출력하는 다수결 유닛이다. 다른 하나는 "작업 할당기"로, 원하는 출력이 -1이고 다수결 출력과 다른 경우, 작업 할당기는 출력을 양수에서 음수로 바꿔야 하는 최소한의 ADALINE 유닛 수를 계산하고, 음수에 가장 가까운 ADALINE 유닛을 선택하여 ADALINE 학습 규칙에 따라 가중치를 갱신하게 한다. 이는 "최소 교란 원칙"의 한 형태로 간주되었다.[^5]
제작된 가장 큰 MADALINE 기계는 1,000개의 가중치를 가졌으며, 각각은 메미스터로 구현되었다. 이 기계는 1963년에 제작되었고 학습에 MRI를 사용하였다.[^5][^14]
일부 MADALINE 기계는 도립 진자 균형 잡기, 기상 예측, 음성 인식 등의 과제를 수행하는 것이 시연되었다.[^2]
MADALINE Rule 2 (MRII) - 1988년에 기술된 두 번째 훈련 알고리즘은 Rule I을 개선한 것이다.[^3] Rule II 훈련 알고리즘은 "최소 교란"이라는 원칙에 기반한다. 이 알고리즘은 훈련 예제를 반복하면서, 각 예제에 대해 다음을 수행한다:
- 예측에 대한 신뢰도가 가장 낮은 은닉층 유닛(ADALINE 분류기)을 찾는다.
- 해당 유닛의 부호를 시험적으로 뒤집는다.
- 네트워크의 오차가 감소하는지에 따라 변경을 수락하거나 거부한다.
- 오차가 0이 되면 중단한다.
MADALINE Rule 3 - 세 번째 "Rule"은 부호 함수 대신 시그모이드 활성화 함수를 사용하는 수정된 네트워크에 적용되었으며, 이후 역전파와 동등한 것으로 밝혀졌다.[^5]
또한, 단일 유닛의 부호를 뒤집는 것만으로 특정 예제의 오차가 0이 되지 않을 경우, 훈련 알고리즘은 유닛 쌍의 부호를 뒤집고, 이어서 세 유닛 조합 등으로 확장해 나간다.[^3]
같이 보기
-
다층 퍼셉트론
-
외부 링크
-
Widrow가 작동하는 노브형 ADALINE 기계와 메미스터 ADALINE 기계를 시연하는 영상.
-
*"메미스터 기반 다층 신경망의 온라인 경사 하강 훈련". 아날로그 컴퓨팅에서 메미스터를 이용한 ADALINE 알고리즘 구현.
참고 문헌
[^1]: [http://www-isl.stanford.edu/~widrow/papers/t1960anadaptive.pdf 1960: 화학적 "메미스터"를 사용한 적응형 "ADALINE" 뉴런]
[^2]: Youtube: [https://www.youtube.com/watch?v=IEFRtz68m-8 widrowlms: 과학의 현장]
[^3]: MADALINE 규칙 II: 신경망 훈련 알고리즘
[^4]: Widrow, Bernard. 아달라인 뉴런 네트워크에서의 일반화와 정보 저장
[^5]: Widrow, Bernard. 적응형 신경망의 30년: 퍼셉트론, 매달라인, 그리고 역전파
[^6]: Anderson, James A.. 말하는 네트워크: 신경망의 구술 역사. MIT Press
[^7]: Youtube: [https://www.youtube.com/watch?v=hc2Zj55j1zU widrowlms: LMS 알고리즘과 ADALINE. 제1부 - LMS 알고리즘]
[^8]: Youtube: [https://www.youtube.com/watch?v=skfNlwEbqck widrowlms: LMS 알고리즘과 ADALINE. 제2부 - ADALINE과 메미스터 ADALINE]
[^9]: Widrow, B.. 적응형 잡음 제거: 원리와 응용. (1975)
[^10]: Adaline (적응형 선형). 컴퓨터과학과, 텍사스 대학교 샌안토니오
[^11]: CS181 강의 5 — 퍼셉트론. 하버드 대학교. (2017년 6월)
[^12]: Youtube: [https://www.youtube.com/watch?v=IEFRtz68m-8 widrowlms: 과학의 현장] (Madaline은 영상 시작 부분과 8:46에 언급됨)
[^13]: 말하는 네트워크: 신경망의 구술 역사. The MIT Press. (2000)
[^14]: B. Widrow, "Adaline과 Madaline-1963, 기조 연설," Proc. 1st lEEE lntl. Conf. on Neural Networks, Vol. 1, pp. 145-158, San Diego, CA, June 23, 1987
관련 인사이트

로봇은 왜 볼트를 떨어뜨리는가 — Physical AI가 공장에 필요한 진짜 이유
AI가 데이터 패턴만 외우는 시대는 끝나고 있다. 물리 법칙을 이해하는 Physical AI가 제조 현장에 왜 필요한지, KAIST 교수와 자동차 부품 공장 팀장이 볼트 하나를 놓고 이야기한다.

디지털 트윈, 당신 공장엔 이미 있다 — 엑셀과 MES 사이 어딘가에
디지털 트윈은 10억짜리 3D 시뮬레이션이 아니다. 지금 쓰고 있는 엑셀에 좋은 질문 하나를 더하는 것 — 두 전문가가 중소 제조기업이 이미 가진 데이터로 예측하는 공장을 만드는 현실적 로드맵을 제시한다.

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.