컴퓨터 프로그램
![[소스 코드 JavaScript 언어로 작성된 컴퓨터 프로그램의 소스 코드. appendChild 메서드를 보여준다. 이 메서드는 기존 부모 노드에 새로운 자식 노드를 추가한다. HTML 문서의 구조를 동적으로 수정하는 데 흔히 사용된다.]]
{kind=link}
컴퓨터 프로그램은 컴퓨터가 실행할 수 있도록 프로그래밍 언어로 작성된 명령어의 순서 또는 집합이다. 이는 소프트웨어의 구성 요소 중 하나이며, 소프트웨어에는 문서 및 기타 무형의 구성 요소도 포함된다.
사람이 읽을 수 있는 형태의 컴퓨터 프로그램을 소스 코드라고 한다. 컴퓨터는 자체 기계어 명령만 실행할 수 있기 때문에, 소스 코드를 실행하려면 별도의 컴퓨터 프로그램이 필요하다. 따라서 소스 코드는 해당 언어용으로 작성된 컴파일러를 사용하여 기계어 명령으로 번역될 수 있다. (어셈블리어 프로그램은 어셈블러를 사용하여 번역된다.) 그 결과로 생성된 파일을 실행 파일이라고 한다. 또는 해당 언어용으로 작성된 인터프리터 내에서 소스 코드를 실행할 수도 있다.[^1]
실행 파일의 실행이 요청되면, 운영 체제가 이를 메모리에 적재하고[^2] 프로세스를 시작한다.[^3] 중앙 처리 장치는 곧 이 프로세스로 전환하여 각 기계어 명령을 인출, 해독, 실행한다.[^4]
소스 코드의 실행이 요청되면, 운영 체제가 해당 인터프리터를 메모리에 적재하고 프로세스를 시작한다. 그런 다음 인터프리터가 소스 코드를 메모리에 적재하여 각 문장을 번역하고 실행한다. 소스 코드를 실행하는 것은 실행 파일을 실행하는 것보다 느리다.[^5] 또한 컴퓨터에 인터프리터가 설치되어 있어야 한다.
컴퓨터 프로그램 예시
"Hello, World!" 프로그램은 프로그래밍 언어의 기본 구문을 설명하는 데 사용된다. BASIC(1964) 언어의 구문은 배우기 쉽도록 의도적으로 제한되었다.[^6] 예를 들어, 변수는 사용 전에 선언할 필요가 없다.[^7] 또한 변수는 자동으로 0으로 초기화된다.[^7] 다음은 숫자 목록의 평균을 구하는 Basic 컴퓨터 프로그램의 예시이다:[^8] 10 INPUT "How many numbers to average?", A 20 FOR I = 1 TO A 30 INPUT "Enter number:", B 40 LET C = C + B 50 NEXT I 60 LET D = C/A 70 PRINT "The average is", D 80 END
기본적인 컴퓨터 프로그래밍의 원리를 익히면, 대규모 컴퓨터 시스템을 구축하기 위한 더 정교하고 강력한 언어를 사용할 수 있게 된다.[^9]
역사
소프트웨어 개발의 발전은 컴퓨터 하드웨어의 발전에 따른 결과이다. 하드웨어 역사의 각 단계마다 컴퓨터 프로그래밍의 과제는 극적으로 변화하였다.
해석 기관

1837년, 자카르 직기에서 영감을 받은 찰스 배비지는 해석 기관의 제작을 시도하였다.[^10] 이 계산 장치의 구성 요소 명칭은 섬유 산업에서 차용하였다. 섬유 산업에서는 실을 창고에서 가져와 방직하였다. 이 장치에는 각각 50자리 십진수 1,000개를 저장할 수 있는 메모리로 구성된 스토어가 있었다.[^11] 스토어의 숫자는 처리를 위해 밀로 전송되었다. 이 기관은 두 세트의 천공 카드를 사용하여 프로그래밍되었다. 한 세트는 연산을 지시하고, 다른 세트는 변수를 입력하였다.[^10][^146] 그러나 수천 개의 톱니바퀴와 기어는 완전히 맞물려 작동하지 못하였다.[^12]
에이다 러브레이스는 찰스 배비지를 위해 해석 기관에 대한 기술서(1843)를 작성하였다.[^147] 이 기술서에는 해석 기관을 사용하여 베르누이 수를 계산하는 방법을 완전히 상세하게 기술한 노트 G가 포함되어 있었다. 이 노트는 일부 역사학자들에 의해 세계 최초의 컴퓨터 프로그램으로 인정받고 있다.[^12]
범용 튜링 기계

1936년, 앨런 튜링은 모든 계산을 모델링할 수 있는 이론적 장치인 범용 튜링 기계를 소개하였다.[^13] 이것은 무한히 긴 읽기/쓰기 테이프를 가진 유한 상태 기계이다. 이 기계는 알고리즘을 수행하면서 테이프를 앞뒤로 이동시키고 그 내용을 변경할 수 있다. 기계는 초기 상태에서 시작하여 일련의 단계를 거친 후 정지 상태에 도달하면 멈춘다.[^14] 현재의 모든 컴퓨터는 튜링 완전하다.[^15]
에니악

전자식 수치 적분기 및 컴퓨터(ENIAC)는 1943년 7월부터 1945년 가을 사이에 제작되었다. 이것은 17,468개의 진공관을 사용하여 회로를 구성한 튜링 완전한 범용 컴퓨터였다. 핵심적으로 이것은 일련의 파스칼린을 서로 연결한 것이었다.[^16] 40개의 유닛은 무게가 30톤이었고, 의 공간을 차지하였으며, 유휴 상태에서도 시간당 650달러(1940년대 화폐 기준)의 전력을 소비하였다.[^16] 10진법 누산기 20개를 갖추고 있었다. 에니악의 프로그래밍에는 최대 두 달이 소요되었다.[^16] 세 개의 함수 테이블은 바퀴 위에 놓여 있어 고정된 함수 패널까지 굴려서 이동해야 했다. 함수 테이블은 무거운 검은 케이블을 플러그보드에 꽂아 함수 패널에 연결하였다. 각 함수 테이블에는 728개의 회전 손잡이가 있었다. 에니악 프로그래밍에는 3,000개의 스위치 중 일부를 설정하는 작업도 포함되었다. 프로그램 디버깅에는 일주일이 걸렸다.[^17] 에니악은 1947년부터 1955년까지 애버딘 시험장에서 수소 폭탄의 매개변수 계산, 기상 패턴 예측, 포병 조준을 위한 사격표 생성 등의 작업을 수행하였다.[^18]
내장형 프로그램 컴퓨터
코드를 꽂고 스위치를 돌리는 대신, 내장형 프로그램 컴퓨터는 데이터를 메모리에 적재하는 것과 마찬가지로 명령어를 메모리에 적재한다.[^19] 그 결과, 컴퓨터를 빠르게 프로그래밍할 수 있었고 매우 빠른 속도로 계산을 수행할 수 있었다.[^20] 프레스퍼 에커트와 존 모클리는 에니악을 제작하였다. 두 엔지니어는 1944년 2월에 작성된 3쪽짜리 메모에서 내장형 프로그램 개념을 제시하였다.[^21] 이후 1944년 9월, 존 폰 노이만이 에니악 프로젝트에 참여하기 시작하였다. 1945년 6월 30일, 폰 노이만은 컴퓨터의 구조를 인간 두뇌의 구조와 동일시한 EDVAC에 관한 보고서 초안을 발표하였다.[^20] 이 설계는 폰 노이만 구조로 알려지게 되었다. 이 구조는 1949년 EDVAC과 EDSAC 컴퓨터의 제작에 동시에 적용되었다.[^22][^148]
IBM 시스템/360(1964)은 모두 동일한 명령어 집합 구조를 가진 컴퓨터 제품군이었다. 모델 20은 가장 작고 가장 저렴하였다. 고객은 동일한 응용 소프트웨어를 유지하면서 업그레이드할 수 있었다.[^23] 모델 195는 가장 고급 사양이었다. 각 시스템/360 모델은 다중 프로그래밍[^23] 기능을 갖추고 있었으며, 이는 메모리에 여러 프로세스를 동시에 보유하는 것이었다. 하나의 프로세스가 입출력을 기다리는 동안 다른 프로세스가 연산을 수행할 수 있었다.
IBM은 각 모델이 PL/I를 사용하여 프로그래밍되도록 계획하였다.[^24] COBOL, FORTRAN, ALGOL 프로그래머들로 구성된 위원회가 결성되었다. 그 목적은 포괄적이고 사용하기 쉬우며 확장 가능하고, COBOL과 FORTRAN을 대체할 수 있는 언어를 개발하는 것이었다.[^24] 그 결과물은 컴파일에 오랜 시간이 걸리는 크고 복잡한 언어였다.[^25]
![[데이터 제네럴 노바 3(1970년대 중반 제조)의 수동 입력용 스위치]] 1970년대까지 제조된 컴퓨터에는 수동 프로그래밍을 위한 전면 패널 스위치가 있었다.[^26] 컴퓨터 프로그램은 참조용으로 종이에 작성되었다. 명령어는 켜기/끄기 설정의 조합으로 표현되었다. 설정을 구성한 후 실행 버튼을 눌렀다. 이 과정을 반복하였다. 컴퓨터 프로그램은 종이 테이프, 천공 카드 또는 자기 테이프를 통해 자동으로 입력되기도 하였다. 매체를 적재한 후 스위치로 시작 주소를 설정하고 실행 버튼을 눌렀다.[^26]
{kind=link}
초대규모 집적 회로
 ]]
소프트웨어 개발의 주요 이정표는 초대규모 집적(VLSI) 회로의 발명(1964)이었다.
]]
소프트웨어 개발의 주요 이정표는 초대규모 집적(VLSI) 회로의 발명(1964)이었다.
페어차일드 반도체(1957)와 인텔(1968)의 공동 창립자인 로버트 노이스는 전계 효과 트랜지스터의 생산을 정밀화하는 기술적 개선을 달성하였다(1963).[^27] 그 목표는 반도체 접합부의 전기 저항률과 전도도를 변화시키는 것이다. 먼저, 자연에서 산출되는 규산염 광물을 지멘스 공정을 사용하여 다결정 실리콘 봉으로 변환한다.[^28] 그런 다음 초크랄스키 공정을 통해 봉을 단결정 실리콘 불 결정으로 변환한다.[^29] 결정을 얇게 절단하여 웨이퍼 기판을 형성한다. 그 후 포토리소그래피의 평면 공정이 웨이퍼 위에 단극성 트랜지스터, 커패시터, 다이오드, 저항기를 집적하여 금속-산화막-반도체(MOS) 트랜지스터의 행렬을 구축한다.[^30][^31] MOS 트랜지스터는 집적 회로 칩의 핵심 부품이다.[^27]
원래 집적 회로 칩은 제조 과정에서 기능이 설정되었다. 1960년대에는 전기 흐름의 제어가 읽기 전용 메모리(ROM) 행렬의 프로그래밍으로 전환되었다. 이 행렬은 퓨즈의 2차원 배열과 유사하였다. 행렬에 명령어를 내장하는 과정은 불필요한 연결을 태워 없애는 것이었다. 연결이 너무 많았기 때문에, 펌웨어 프로그래머들은 소거 작업을 감독하기 위해 다른 칩에 컴퓨터 프로그램을 작성하였다. 이 기술은 프로그래머블 ROM으로 알려지게 되었다. 1971년, 인텔은 컴퓨터 프로그램을 칩에 탑재하고 이를 인텔 4004 마이크로프로세서라고 명명하였다.[^32]

마이크로프로세서와 중앙 처리 장치(CPU)라는 용어는 현재 상호 교환적으로 사용된다. 그러나 CPU는 마이크로프로세서보다 먼저 등장하였다. 예를 들어, IBM 시스템/360(1964)은 세라믹 기판 위의 개별 부품이 포함된 회로 기판으로 만들어진 CPU를 갖추고 있었다.[^33]
x86 시리즈
![최초의 [IBM 개인용 컴퓨터 (1981)는 인텔 8088 마이크로프로세서를 사용하였다.]] 1978년, 인텔이 인텔 8080을 인텔 8086으로 업그레이드하면서 현대적 소프트웨어 개발 환경이 시작되었다. 인텔은 더 저렴한 인텔 8088을 제조하기 위해 인텔 8086을 단순화하였다.[^34] IBM은 개인용 컴퓨터 시장에 진출할 때(1981) 인텔 8088을 채택하였다. 개인용 컴퓨터에 대한 소비자 수요가 증가함에 따라 인텔의 마이크로프로세서 개발도 함께 발전하였다. 이 일련의 개발은 x86 시리즈로 알려져 있다. x86 어셈블리 언어는 하위 호환이 가능한 기계어 명령어 집합이다. 초기 마이크로프로세서에서 생성된 기계어 명령어는 마이크로프로세서 업그레이드 전반에 걸쳐 유지되었다. 이를 통해 소비자는 새로운 응용 소프트웨어를 구매하지 않고도 새 컴퓨터를 구입할 수 있었다. 주요 명령어 범주는 다음과 같다:
.png){kind=link}
- 랜덤 액세스 메모리에서 숫자와 문자열을 설정하고 접근하기 위한 메모리 명령어.
- 정수에 대한 기본 산술 연산을 수행하기 위한 정수 산술 논리 장치(ALU) 명령어.
- 실수에 대한 기본 산술 연산을 수행하기 위한 부동 소수점 ALU 명령어.
- 메모리를 할당하고 함수와 인터페이스하는 데 필요한 워드를 푸시하고 팝하기 위한 호출 스택 명령어.
- 여러 프로세서가 데이터 배열에 대해 동일한 알고리즘을 수행할 수 있을 때 속도를 높이기 위한 단일 명령어 다중 데이터(SIMD) 명령어.
프로그래밍 환경의 변화
![]() VT100(1978)은 널리 사용된 컴퓨터 단말기였다.]]
VLSI 회로는 프로그래밍 환경을 컴퓨터 단말기(1990년대까지)에서 그래픽 사용자 인터페이스(GUI) 컴퓨터로 발전시켰다. 컴퓨터 단말기는 프로그래머를 명령줄 환경에서 실행되는 단일 셸로 제한하였다. 1970년대에는 텍스트 기반 사용자 인터페이스를 통해 전체 화면 소스 코드 편집이 가능해졌다. 사용 가능한 기술에 관계없이, 목표는 프로그래밍 언어로 프로그래밍하는 것이다.
VT100(1978)은 널리 사용된 컴퓨터 단말기였다.]]
VLSI 회로는 프로그래밍 환경을 컴퓨터 단말기(1990년대까지)에서 그래픽 사용자 인터페이스(GUI) 컴퓨터로 발전시켰다. 컴퓨터 단말기는 프로그래머를 명령줄 환경에서 실행되는 단일 셸로 제한하였다. 1970년대에는 텍스트 기반 사용자 인터페이스를 통해 전체 화면 소스 코드 편집이 가능해졌다. 사용 가능한 기술에 관계없이, 목표는 프로그래밍 언어로 프로그래밍하는 것이다.
프로그래밍 패러다임과 언어
프로그래밍 언어의 기능은 프로그래밍 이상을 표현하기 위해 결합할 수 있는 구성 요소를 제공하기 위해 존재한다.[^35] 이상적으로, 프로그래밍 언어는 다음을 충족해야 한다:[^35]
- 코드에서 아이디어를 직접 표현한다.
- 독립적인 아이디어를 독립적으로 표현한다.
- 아이디어 간의 관계를 코드에서 직접 표현한다.
- 아이디어를 자유롭게 결합한다.
- 결합이 의미 있는 경우에만 아이디어를 결합한다.
- 단순한 아이디어를 단순하게 표현한다.
이러한 구성 요소를 제공하는 프로그래밍 언어의 프로그래밍 스타일은 프로그래밍 패러다임으로 분류할 수 있다.[^36] 예를 들어, 서로 다른 패러다임은 다음을 구분할 수 있다:[^36]
- 절차적 언어, 함수형 언어, 논리 언어.
- 서로 다른 수준의 데이터 추상화.
- 서로 다른 수준의 클래스 계층 구조.
- 컨테이너 타입과 제네릭 프로그래밍에서와 같이 서로 다른 수준의 입력 데이터 타입. 이러한 각 프로그래밍 스타일은 서로 다른 프로그래밍 언어의 합성에 기여해 왔다.[^36]
프로그래밍 언어는 프로그래머가 컴퓨터에 명령을 전달할 수 있도록 하는 키워드, 기호, 식별자, 규칙의 집합이다.[^37] 이들은 구문(syntax)이라 불리는 규칙 집합을 따른다.[^37]
- 키워드는 선언문과 문장을 형성하기 위한 예약어이다.
- 기호는 연산, 대입, 제어 흐름, 구분자를 형성하기 위한 문자이다.
- 식별자는 상수, 변수명, 구조체명, 함수명을 형성하기 위해 프로그래머가 만든 단어이다.
- 구문 규칙은 배커스-나우르 표기법으로 정의된다.
프로그래밍 언어는 형식 언어에 기반을 둔다.[^38] 형식 언어의 관점에서 해결책을 정의하는 목적은 근본적인 문제를 해결하기 위한 알고리즘을 생성하는 것이다.[^38] 알고리즘은 문제를 해결하는 간단한 명령의 순서이다.[^39]
프로그래밍 언어의 세대
![[Machine language monitor on a W65C816S microprocessor ]] 프로그래밍 언어의 진화는 EDSAC(1949)이 폰 노이만 아키텍처에서 최초의 내장형 컴퓨터 프로그램을 사용했을 때 시작되었다.[^40] EDSAC의 프로그래밍은 1세대 프로그래밍 언어에 해당했다.[^149]
{kind=link}
-
1세대 프로그래밍 언어는 기계어이다.[^41] 기계어는 프로그래머가 기계 코드라 불리는 명령 번호를 사용하여 명령을 입력해야 한다. 예를 들어, PDP-11에서 ADD 연산의 명령 번호는 24576이다.[^42]
-
2세대 프로그래밍 언어는 어셈블리어이다.[^41] 어셈블리어는 프로그래머가 명령 번호를 기억하는 대신 니모닉 명령어를 사용할 수 있게 해준다. 어셈블러는 각 어셈블리어 니모닉을 해당 기계어 번호로 변환한다. 예를 들어, PDP-11에서 연산 24576은 소스 코드에서 ADD R0,R0으로 참조할 수 있다.[^42] 네 가지 기본 산술 연산에는 ADD, SUB, MUL, DIV와 같은 어셈블리 명령어가 있다.[^42] 컴퓨터에는 메모리 셀을 예약하기 위한 DW(Define Word)와 같은 명령어도 있다. 그런 다음 MOV 명령어로 레지스터와 메모리 사이에서 정수를 복사할 수 있다.
- 어셈블리어 문장의 기본 구조는 레이블, 연산, 피연산자, 주석이다.[^43] :* 레이블은 프로그래머가 변수명으로 작업할 수 있게 해준다. 어셈블러는 나중에 레이블을 물리적 메모리 주소로 변환한다. :* 연산은 프로그래머가 니모닉으로 작업할 수 있게 해준다. 어셈블러는 나중에 니모닉을 명령 번호로 변환한다. :* 피연산자는 어셈블러에게 연산이 처리할 데이터를 알려준다. :* 주석은 명령어만으로는 모호하기 때문에 프로그래머가 서술을 표현할 수 있게 해준다. : 어셈블리어 프로그램의 핵심 특성은 대응하는 기계어 목표와 일대일 매핑을 형성한다는 것이다.[^44]
-
3세대 프로그래밍 언어는 컴파일러와 인터프리터를 사용하여 컴퓨터 프로그램을 실행한다. 3세대 언어의 구별되는 특징은 특정 하드웨어로부터의 독립성이다.[^45] 초기 언어에는 FORTRAN(1958), COBOL(1959), ALGOL(1960), BASIC(1964)이 포함된다.[^41] 1973년, C 프로그래밍 언어가 효율적인 기계어 명령을 생성하는 고급 언어로 등장했다.[^46] 3세대 언어가 역사적으로 각 문장에 대해 많은 기계 명령을 생성한 반면,[^47] C에는 단일 기계 명령을 생성할 수 있는 문장이 있다. 또한, 최적화 컴파일러는 프로그래머의 의도를 무시하고 문장보다 적은 수의 기계 명령을 생성할 수도 있다. 오늘날, 언어의 전체 패러다임이 명령형 3세대 스펙트럼을 채우고 있다.
-
4세대 프로그래밍 언어는 프로그래밍 문장이 어떻게 구성되어야 하는지보다 어떤 출력 결과가 원하는지를 강조한다.[^41] 선언형 언어는 부작용을 제한하고 프로그래머가 비교적 적은 오류로 코드를 작성할 수 있도록 시도한다.[^41] 널리 사용되는 4세대 언어 중 하나는 구조화 질의 언어(SQL)라 불린다.[^41] 데이터베이스 개발자는 더 이상 각 데이터베이스 레코드를 한 번에 하나씩 처리할 필요가 없다. 또한, 간단한 select 문으로 레코드가 어떻게 검색되는지 이해하지 않고도 출력 레코드를 생성할 수 있다.
명령형 언어

명령형 언어는 선언, 표현식, 문장을 사용하여 순차적 알고리즘을 명시한다:[^48]
- 선언은 컴퓨터 프로그램에 변수명을 도입하고 이를 데이터 타입에 할당한다[^49] – 예를 들어: var x: integer;
- 표현식은 값을 산출한다 – 예를 들어: 2 + 2는 4를 산출한다
- 문장은 표현식을 변수에 대입하거나 변수의 값을 사용하여 프로그램의 제어 흐름을 변경할 수 있다 – 예를 들어: x := 2 + 2; if x = 4 then do_something();
Fortran
FORTRAN(1958)은 "The IBM Mathematical FORmula TRANslating system"으로 공개되었다. 문자열 처리 기능 없이 과학 계산용으로 설계되었다. 선언, 표현식, 문장과 함께 다음을 지원했다:
- 배열.
- 서브루틴.
- "do" 루프.
성공한 이유는 다음과 같다:
- 프로그래밍 및 디버깅 비용이 컴퓨터 실행 비용보다 낮았다.
- IBM의 지원을 받았다.
- 당시 응용 분야가 과학이었다.[^50]
그러나 비IBM 공급업체들도 Fortran 컴파일러를 작성했지만, IBM의 컴파일러에서는 실패할 가능성이 높은 구문을 사용했다.[^50] 미국 국립 표준 협회(ANSI)는 1966년에 최초의 Fortran 표준을 개발했다. 1978년, Fortran 77이 1991년까지 표준이 되었다. Fortran 90은 다음을 지원한다:
- 레코드.
- 배열에 대한 포인터.
COBOL
COBOL(1959)은 "COmmon Business Oriented Language"의 약자이다. Fortran은 기호를 조작했다. 기호가 반드시 숫자일 필요가 없다는 것이 곧 인식되었고, 이에 따라 문자열이 도입되었다.[^51] 미국 국방부는 COBOL의 개발에 영향을 미쳤으며, Grace Hopper가 주요 기여자였다. 문장은 영어와 유사하고 장황했다. 목표는 관리자가 프로그램을 읽을 수 있는 언어를 설계하는 것이었다. 그러나 구조화된 문장의 부족이 이 목표를 방해했다.[^52]
COBOL의 개발은 엄격하게 통제되었기 때문에 ANSI 표준을 필요로 하는 방언이 등장하지 않았다. 그 결과, 1974년까지 15년간 변경되지 않았다. 1990년대 버전은 객체 지향 프로그래밍과 같은 중대한 변경을 도입했다.[^52]
Algol
ALGOL(1960)은 "ALGOrithmic Language"의 약자이다. 프로그래밍 언어 설계에 깊은 영향을 미쳤다.[^53] 유럽과 미국의 프로그래밍 언어 전문가 위원회에서 탄생하여, 표준 수학 표기법을 사용하고 읽기 쉬운 구조화된 설계를 가졌다. Algol은 배커스-나우르 표기법을 사용하여 구문을 정의한 최초의 언어였다.[^53] 이는 구문 지향 컴파일러로 이어졌다. 다음과 같은 기능을 추가했다:
- 변수가 해당 블록에 지역적인 블록 구조.
- 가변 범위의 배열.
- "for" 루프.
- 함수.
- 재귀.[^53]
Algol의 직계 후손으로는 한 갈래에서 Pascal, Modula-2, Ada, Delphi, Oberon이 있다. 다른 갈래에서는 C, C++, Java가 후손에 포함된다.[^53]
Basic
BASIC(1964)은 "Beginner's All-Purpose Symbolic Instruction Code"의 약자이다. 다트머스 대학에서 모든 학생이 배울 수 있도록 개발되었다.[^8] 학생이 더 강력한 언어로 진행하지 않더라도, Basic은 기억할 수 있었다.[^8] Basic 인터프리터는 1970년대 후반에 제조된 마이크로컴퓨터에 설치되었다. 마이크로컴퓨터 산업이 성장하면서 언어도 함께 성장했다.[^8]
Basic은 대화형 세션을 개척했다.[^8] 환경 내에서 운영 체제 명령을 제공했다:
- 'new' 명령은 빈 상태를 만들었다.
- 문장은 즉시 평가되었다.
- 문장 앞에 줄 번호를 붙여 프로그래밍할 수 있었다.
- 'list' 명령은 프로그램을 표시했다.
- 'run' 명령은 프로그램을 실행했다.
그러나 Basic 구문은 대형 프로그램에는 너무 단순했다.[^8] 최근의 방언들은 구조와 객체 지향 확장을 추가했다. Microsoft의 Visual Basic은 여전히 널리 사용되며 그래픽 사용자 인터페이스를 생성한다.[^7]
C
C 프로그래밍 언어(1973)는 BCPL 언어가 B로 대체되고, AT&T 벨 연구소가 다음 버전을 "C"라고 불렀기 때문에 그 이름을 얻었다. 그 목적은 UNIX 운영 체제를 작성하는 것이었다.[^46] C는 비교적 작은 언어로, 컴파일러를 작성하기 쉽게 만들었다. 1980년대의 하드웨어 성장과 함께 성장했다.[^46] 또한 어셈블리어의 기능을 갖추면서도 고급 구문을 사용하기 때문에 성장했다. 다음과 같은 고급 기능을 추가했다:
- 인라인 어셈블러
- 포인터에 대한 산술 연산
- 함수에 대한 포인터
- 비트 연산
- 복잡한 연산자의 자유로운 결합[^46]
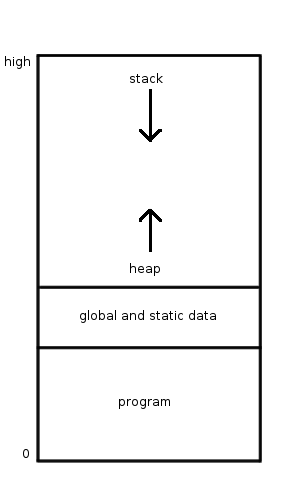
C는 프로그래머가 데이터를 저장할 메모리 영역을 제어할 수 있게 해준다. 전역 변수와 정적 변수는 저장하는 데 가장 적은 클록 사이클이 필요하다. 스택은 표준 변수 선언에 자동으로 사용된다. 힙 메모리는 malloc() 함수로부터 포인터 변수에 반환된다.
-
전역 및 정적 데이터 영역은 프로그램 영역 바로 위에 위치한다. (프로그램 영역은 기술적으로 텍스트 영역이라 불린다. 기계 명령이 저장되는 곳이다.)
-
전역 및 정적 데이터 영역은 기술적으로 두 영역이다.[^54] 하나는 초기화된 데이터 세그먼트라 불리며, 기본값으로 선언된 변수가 저장된다. 다른 하나는 블록 시작 세그먼트라 불리며, 기본값 없이 선언된 변수가 저장된다.
-
전역 및 정적 데이터 영역에 저장된 변수는 컴파일 시점에 주소가 설정된다. 프로세스의 수명 동안 값을 유지한다.
-
전역 및 정적 영역은 main() 함수 위에(외부에) 선언된 전역 변수를 저장한다.[^55] 전역 변수는 main()과 소스 코드의 다른 모든 함수에서 볼 수 있다.
반면에, main(), 다른 함수, 또는 { } 블록 구분자 내부의 변수 선언은 지역 변수이다. 지역 변수에는 형식 매개변수 변수도 포함된다. 매개변수 변수는 함수 정의의 괄호 안에 포함된다.[^56] 매개변수는 함수에 대한 인터페이스를 제공한다.
- static 접두사를 사용하여 선언된 지역 변수도 전역 및 정적 데이터 영역에 저장된다.[^54] 전역 변수와 달리, 정적 변수는 함수 또는 블록 내에서만 볼 수 있다. 정적 변수는 항상 값을 유지한다. 사용 예시로는 int increment_counter(){static int counter = 0; counter++; return counter;} 함수가 있다.
-
-
스택 영역은 최상위 메모리 주소 근처에 위치한 연속적인 메모리 블록이다.[^57] 스택에 배치되는 변수는 위에서 아래로 채워진다.[^57] 스택 포인터는 마지막으로 채워진 메모리 주소를 추적하는 특수 목적 레지스터이다.[^57] 변수는 어셈블리어 PUSH 명령을 통해 스택에 배치된다. 따라서 이러한 변수의 주소는 실행 시점에 설정된다. 스택 변수가 범위를 잃는 방법은 POP 명령을 통해서이다.
- static 접두사 없이 선언된 지역 변수, 형식 매개변수 변수를 포함하여,[^58] 자동 변수라 불리며[^55] 스택에 저장된다.[^54] 함수 또는 블록 내에서 볼 수 있으며 함수 또는 블록을 종료하면 범위를 잃는다.
-
힙 영역은 스택 아래에 위치한다.[^54] 아래에서 위로 채워진다. 운영 체제는 힙 포인터와 할당된 메모리 블록 목록을 사용하여 힙을 관리한다.[^59] 스택과 마찬가지로, 힙 변수의 주소는 실행 시점에 설정된다. 힙 포인터와 스택 포인터가 만나면 메모리 부족 오류가 발생한다.
- C는 힙 메모리를 할당하기 위해 malloc() 라이브러리 함수를 제공한다.[^60] 힙에 데이터를 채우는 것은 추가적인 복사 함수이다. 힙에 저장된 변수는 포인터를 사용하여 함수에 경제적으로 전달된다. 포인터 없이는 전체 데이터 블록이 스택을 통해 함수에 전달되어야 한다.
C++
1970년대에 소프트웨어 엔지니어들은 대규모 프로젝트를 모듈로 분해하기 위한 언어 지원이 필요했다.[^61] 분명한 기능 중 하나는 대규모 프로젝트를 물리적으로 별도의 파일로 분해하는 것이었다. 덜 명백한 기능은 대규모 프로젝트를 논리적으로 추상 데이터 타입으로 분해하는 것이었다.[^61] 당시 언어들은 정수, 부동소수점 수, 문자열과 같은 구체적(스칼라) 데이터 타입을 지원했다. 추상 데이터 타입은 구체적 데이터 타입의 구조로, 새로운 이름이 부여된다. 예를 들어, 정수 목록을 integer_list라 부를 수 있다.
객체 지향 용어에서 추상 데이터 타입은 클래스라 불린다. 그러나 클래스는 정의일 뿐이며, 메모리가 할당되지 않는다. 클래스에 메모리가 할당되고 식별자에 바인딩되면 이를 객체라 부른다.[^62]
객체 지향 명령형 언어는 클래스의 필요성과 안전한 함수형 프로그래밍의 필요성을 결합하여 개발되었다.[^63] 객체 지향 언어에서 함수는 클래스에 할당된다. 할당된 함수는 메서드, 멤버 함수, 또는 연산이라 불린다. 객체 지향 프로그래밍은 객체에 대해 연산을 실행하는 것이다.[^64]
객체 지향 언어는 부분집합/상위집합 관계를 모델링하는 구문을 지원한다. 집합론에서, 부분집합의 원소는 상위집합에 포함된 모든 속성을 상속한다. 예를 들어, 학생은 사람이다. 따라서 학생 집합은 사람 집합의 부분집합이다. 결과적으로 학생은 모든 사람에게 공통된 모든 속성을 상속한다. 추가로, 학생은 다른 사람들이 갖지 않는 고유한 속성을 가진다. 객체 지향 언어는 상속을 사용하여 부분집합/상위집합 관계를 모델링한다.[^65] 객체 지향 프로그래밍은 1990년대 후반까지 지배적인 언어 패러다임이 되었다.[^61]
C++(1985)는 원래 "클래스가 있는 C(C with Classes)"라 불렸다.[^66] Simula 언어의 객체 지향 기능을 추가하여 C의 능력을 확장하도록 설계되었다.[^67]
객체 지향 모듈은 두 개의 파일로 구성된다. 정의 파일은 헤더 파일이라 불린다. 다음은 간단한 학교 응용 프로그램에서 GRADE 클래스를 위한 C++ 헤더 파일이다:
// Used to allow multiple source files to include // this header file without duplication errors. // ---------------------------------------------- #ifndef GRADE_H #define GRADE_H
class GRADE { public: // This is the constructor operation. // ---------------------------------- GRADE ( const char letter );
// This is a class variable.
// -------------------------
char letter;
// This is a member operation.
// ---------------------------
int grade_numeric( const char letter );
// This is a class variable.
// -------------------------
int numeric;
}; #endif
생성자 연산은 클래스 이름과 동일한 이름을 가진 함수이다.[^68] 호출 연산이 new 문을 실행할 때 실행된다.
모듈의 다른 파일은 소스 파일이다. 다음은 간단한 학교 응용 프로그램에서 GRADE 클래스를 위한 C++ 소스 파일이다:
GRADE::GRADE( const char letter ) { // Reference the object using the keyword 'this'. // ---------------------------------------------- this->letter = letter;
// This is Temporal Cohesion
// -------------------------
this->numeric = grade_numeric( letter );
}
int GRADE::grade_numeric( const char letter ) { if ( ( letter == 'A' || letter == 'a' ) ) return 4; else if ( ( letter == 'B' || letter == 'b' ) ) return 3; else if ( ( letter == 'C' || letter == 'c' ) ) return 2; else if ( ( letter == 'D' || letter == 'd' ) ) return 1; else if ( ( letter == 'F' || letter == 'f' ) ) return 0; else return -1; }
다음은 간단한 학교 응용 프로그램에서 PERSON 클래스를 위한 C++ 헤더 파일이다:
class PERSON { public: PERSON ( const char *name ); const char *name; }; #endif
다음은 간단한 학교 응용 프로그램에서 PERSON 클래스를 위한 C++ 소스 파일이다:
PERSON::PERSON ( const char *name ) { this->name = name; }
다음은 간단한 학교 응용 프로그램에서 STUDENT 클래스를 위한 C++ 헤더 파일이다:
#include "person.h" #include "grade.h"
// A STUDENT is a subset of PERSON. // -------------------------------- class STUDENT : public PERSON{ public: STUDENT ( const char *name ); GRADE *grade; }; #endif
다음은 간단한 학교 응용 프로그램에서 STUDENT 클래스를 위한 C++ 소스 파일이다:
STUDENT::STUDENT ( const char *name ): // Execute the constructor of the PERSON superclass. // ------------------------------------------------- PERSON( name ) { // Nothing else to do. // ------------------- }
다음은 시연을 위한 드라이버 프로그램이다:
int main( void ) { STUDENT *student = new STUDENT( "The Student" ); student->grade = new GRADE( 'a' );
std::cout
// Notice student inherits PERSON's name
<< student->name
<< ": Numeric grade = "
<< student->grade->numeric
<< "\n";
return 0;
}
다음은 모든 것을 컴파일하기 위한 메이크파일이다:
clean: rm student_dvr *.o
student_dvr: student_dvr.cpp grade.o student.o person.o c++ student_dvr.cpp grade.o student.o person.o -o student_dvr
grade.o: grade.cpp grade.h c++ -c grade.cpp
student.o: student.cpp student.h c++ -c student.cpp
person.o: person.cpp person.h c++ -c person.cpp
선언형 언어
명령형 언어에는 한 가지 주요 비판이 있다: 표현식을 비지역 변수에 대입하면 의도하지 않은 부작용을 생성할 수 있다.[^69] 선언형 언어는 일반적으로 대입문과 제어 흐름을 생략한다. 이들은 계산이 무엇을 수행해야 하는지를 기술하며 어떻게 계산하는지는 기술하지 않는다. 선언형 언어의 두 가지 넓은 범주는 함수형 언어와 논리 언어이다.
함수형 언어의 원리는 잘 정의된 의미론을 위한 지침으로 람다 대수를 사용하는 것이다.[^70] 수학에서, 함수는 표현식의 원소를 값의 범위로 매핑하는 규칙이다. 다음 함수를 고려하자:
times_10(x) = 10 * x
표현식 10 * x는 함수 times_10()에 의해 값의 범위로 매핑된다. 하나의 값은 20이 된다. 이는 x가 2일 때 발생한다. 따라서 함수의 적용은 수학적으로 다음과 같이 작성된다:
times_10(2) = 20
함수형 언어 컴파일러는 이 값을 변수에 저장하지 않는다. 대신, 프로그램 카운터를 호출 함수로 되돌리기 전에 컴퓨터의 스택에 값을 푸시한다. 호출 함수는 그런 다음 스택에서 값을 팝한다.[^71]
명령형 언어도 함수를 지원한다. 따라서 프로그래머가 규율을 지키면 명령형 언어에서도 함수형 프로그래밍을 달성할 수 있다. 그러나 함수형 언어는 구문을 통해 프로그래머에게 이 규율을 강제한다. 함수형 언어는 무엇을 강조하도록 맞춤화된 구문을 가지고 있다.[^72]
함수형 프로그램은 기본 함수 집합과 하나의 드라이버 함수로 개발된다.[^69] 다음 코드 조각을 고려하자:
function max( a, b ){/* code omitted */}
function min( a, b ){/* code omitted */}
function range( a, b, c ) { return max( a, max( b, c ) ) - min( a, min( b, c ) ); }
기본 함수는 max()와 min()이다. 드라이버 함수는 range()이다. 다음을 실행하면:
put( range( 10, 4, 7) ); 6을 출력한다.
함수형 언어는 새로운 언어 기능을 탐구하기 위해 컴퓨터 과학 연구에서 사용된다.[^73] 또한, 부작용이 없기 때문에 병렬 프로그래밍과 동시 프로그래밍에서 인기를 얻었다.[^74] 그러나 응용 프로그램 개발자들은 명령형 언어의 객체 지향 기능을 선호한다.[^74]
Lisp
Lisp(1958)은 "LISt Processor"의 약자이다.[^75] 리스트를 처리하도록 맞춤화되었다. 데이터의 전체 구조는 리스트의 리스트를 구축하여 형성된다. 메모리에서 트리 데이터 구조가 구축된다. 내부적으로 트리 구조는 재귀 함수에 잘 적합하다.[^76] 트리를 구축하는 구문은 공백으로 구분된 요소를 괄호로 감싸는 것이다. 다음은 세 요소의 리스트이다. 처음 두 요소는 각각 두 요소의 리스트이다:
((A B) (HELLO WORLD) 94)
Lisp에는 요소를 추출하고 재구성하는 함수가 있다.[^77] head() 함수는 리스트의 첫 번째 요소를 포함하는 리스트를 반환한다. tail() 함수는 첫 번째 요소를 제외한 모든 것을 포함하는 리스트를 반환한다. cons() 함수는 다른 리스트의 연결인 리스트를 반환한다. 따라서 다음 표현식은 리스트 x를 반환한다:
cons(head(x), tail(x))
Lisp의 한 가지 단점은 많은 함수가 중첩될 때 괄호가 혼란스러워 보일 수 있다는 것이다.[^72] 최신 Lisp 환경은 괄호 일치를 보장하는 데 도움을 준다. 참고로, Lisp은 대입문과 goto 루프의 명령형 언어 연산을 지원한다.[^78] 또한, Lisp은 컴파일 시점에 요소의 데이터 타입에 관심을 두지 않는다.[^79] 대신, 실행 시점에 데이터 타입을 할당(및 재할당)한다. 실행 시점에 데이터 타입을 할당하는 것을 동적 바인딩이라 한다.[^80] 동적 바인딩은 언어의 유연성을 높이지만, 프로그래밍 오류가 소프트웨어 개발 과정의 후반까지 남아 있을 수 있다.[^80]
크고, 신뢰할 수 있고, 읽기 쉬운 Lisp 프로그램을 작성하려면 사전 계획이 필요하다. 적절히 계획되면, 프로그램은 동등한 명령형 언어 프로그램보다 훨씬 짧을 수 있다.[^72] Lisp은 인공지능에서 널리 사용된다. 그러나 명령형 언어 연산을 가지고 있기 때문에 수용되었으며, 이는 의도하지 않은 부작용을 가능하게 한다.[^74]
ML
ML(1973)[^81]은 "Meta Language"의 약자이다. ML은 동일한 타입의 데이터만 서로 비교되도록 검사한다.[^82] 예를 들어, 이 함수는 하나의 입력 매개변수(정수)를 가지며 정수를 반환한다:
ML은 Lisp처럼 괄호 중심이 아니다. 다음은 times_10()의 적용이다:
times_10 2
"20 : int"를 반환한다. (결과와 데이터 타입 모두 반환된다.)
Lisp과 마찬가지로, ML은 리스트를 처리하도록 맞춤화되었다. Lisp과 달리, 각 요소는 동일한 데이터 타입이다.[^83] 또한, ML은 컴파일 시점에 요소의 데이터 타입을 할당한다. 컴파일 시점에 데이터 타입을 할당하는 것을 정적 바인딩이라 한다. 정적 바인딩은 컴파일러가 변수가 사용되기 전에 컨텍스트를 검사하므로 신뢰성을 높인다.[^84]
Prolog
Prolog(1972)는 "PROgramming in LOGic"의 약자이다. 형식 논리에 기반한 논리 프로그래밍 언어이다. 이 언어는 프랑스 마르세유에서 Alain Colmerauer와 Philippe Roussel에 의해 개발되었다. 에든버러 대학의 Robert Kowalski 등이 개척한 선택적 선형 확정 절 해소의 구현이다.[^150]
Prolog 프로그램의 구성 요소는 사실과 규칙이다. 다음은 간단한 예제이다: cat(tom). % tom is a cat mouse(jerry). % jerry is a mouse
animal(X) :- cat(X). % each cat is an animal animal(X) :- mouse(X). % each mouse is an animal
big(X) :- cat(X). % each cat is big small(X) :- mouse(X). % each mouse is small
eat(X,Y) :- mouse(X), cheese(Y). % each mouse eats each cheese eat(X,Y) :- big(X), small(Y). % each big animal eats each small animal
모든 사실과 규칙을 입력한 후, 질문을 할 수 있다: Tom은 Jerry를 먹을까? ?- eat(tom,jerry). true
다음 예제는 Prolog가 문자 등급을 숫자 값으로 변환하는 방법을 보여준다: numeric_grade('A', 4). numeric_grade('B', 3). numeric_grade('C', 2). numeric_grade('D', 1). numeric_grade('F', 0). numeric_grade(X, -1) :- not X = 'A', not X = 'B', not X = 'C', not X = 'D', not X = 'F'. grade('The Student', 'A'). ?- grade('The Student', X), numeric_grade(X, Y). X = 'A', Y = 4
다음은 종합적인 예제이다:
- 모든 용은 불을 내뿜는다, 또는 동등하게, 어떤 것이 용이면 불을 내뿜는다:
billows_fire(X) :- is_a_dragon(X). 2) 생물은 부모 중 하나가 불을 내뿜으면 불을 내뿜는다: billows_fire(X) :- is_a_creature(X), is_a_parent_of(Y,X), billows_fire(Y). 3) X가 Y의 어머니이거나 X가 Y의 아버지이면 X는 Y의 부모이다: is_a_parent_of(X, Y):- is_the_mother_of(X, Y). is_a_parent_of(X, Y):- is_the_father_of(X, Y).
- 어떤 것이 용이면 그것은 생물이다:
is_a_creature(X) :- is_a_dragon(X).
- Norberta는 용이고, Puff는 생물이다. Norberta는 Puff의 어머니이다.
규칙 (2)는 재귀적(귀납적) 정의이다. 실행 방식을 이해할 필요 없이 선언적으로 이해할 수 있다.
규칙 (3)은 관계를 사용하여 함수를 표현하는 방법을 보여준다. 여기서 어머니와 아버지 함수는 모든 개체가 어머니와 아버지를 하나씩만 가지도록 보장한다.
Prolog는 타입이 없는 언어이다. 그럼에도 불구하고 술어를 사용하여 상속을 표현할 수 있다. 규칙 (4)는 생물이 용의 상위 클래스임을 주장한다.
질문은 역방향 추론을 사용하여 답변된다. 다음 질문이 주어지면:
?- billows_fire(X). Prolog는 두 가지 답을 생성한다: X = norberta X = puff
Prolog의 실용적 응용은 인공지능에서의 지식 표현과 문제 해결이다.
객체 지향 프로그래밍
객체 지향 프로그래밍은 객체에 대해 연산(함수)을 실행하는 프로그래밍 방법이다.[^85] 기본 아이디어는 현상의 특성을 객체 컨테이너에 그룹화하고 컨테이너에 이름을 부여하는 것이다. 현상에 대한 연산도 컨테이너에 그룹화된다.[^85] 객체 지향 프로그래밍은 컨테이너의 필요성과 안전한 함수형 프로그래밍의 필요성을 결합하여 개발되었다.[^86] 이 프로그래밍 방법은 객체 지향 언어에 국한될 필요가 없다.[^87] 객체 지향 언어에서 객체 컨테이너는 클래스라 불린다. 비객체 지향 언어에서 데이터 구조(레코드라고도 알려진)가 객체 컨테이너가 될 수 있다. 데이터 구조를 객체 컨테이너로 변환하려면, 해당 구조를 위한 연산을 구체적으로 작성해야 한다. 결과 구조를 추상 데이터 타입이라 한다.[^88] 그러나 상속은 누락된다. 그럼에도 불구하고, 이 단점은 극복할 수 있다.
다음은 간단한 학교 응용 프로그램에서 GRADE 추상 데이터 타입을 위한 C 프로그래밍 언어 헤더 파일이다:
/* Used to allow multiple source files to include / / this header file without duplication errors. / / ---------------------------------------------- */ #ifndef GRADE_H #define GRADE_H
typedef struct { char letter; } GRADE;
/* Constructor / / ----------- */ GRADE *grade_new( char letter );
int grade_numeric( char letter ); #endif
grade_new() 함수는 C++ 생성자 연산과 동일한 알고리즘을 수행한다.
다음은 간단한 학교 응용 프로그램에서 GRADE 추상 데이터 타입을 위한 C 프로그래밍 언어 소스 파일이다:
GRADE *grade_new( char letter ) { GRADE *grade;
/* Allocate heap memory */
/* -------------------- */
if ( ! ( grade = calloc( 1, sizeof ( GRADE ) ) ) )
{
fprintf(stderr,
"ERROR in %s/%s/%d: calloc() returned empty.\n",
,
,
);
exit( 1 );
}
grade->letter = letter;
return grade;
}
int grade_numeric( char letter ) { if ( ( letter == 'A' || letter == 'a' ) ) return 4; else if ( ( letter == 'B' || letter == 'b' ) ) return 3; else if ( ( letter == 'C' || letter == 'c' ) ) return 2; else if ( ( letter == 'D' || letter == 'd' ) ) return 1; else if ( ( letter == 'F' || letter == 'f' ) ) return 0; else return -1; }
생성자에서 각 메모리 셀이 0으로 설정되기 때문에 malloc() 대신 calloc() 함수가 사용된다.
다음은 간단한 학교 응용 프로그램에서 PERSON 추상 데이터 타입을 위한 C 프로그래밍 언어 헤더 파일이다:
typedef struct { char *name; } PERSON;
/* Constructor / / ----------- */ PERSON *person_new( char *name ); #endif
다음은 간단한 학교 응용 프로그램에서 PERSON 추상 데이터 타입을 위한 C 프로그래밍 언어 소스 파일이다:
PERSON *person_new( char *name ) { PERSON *person;
if ( ! ( person = calloc( 1, sizeof ( PERSON ) ) ) )
{
fprintf(stderr,
"ERROR in %s/%s/%d: calloc() returned empty.\n",
,
,
);
exit( 1 );
}
person->name = name;
return person;
}
다음은 간단한 학교 응용 프로그램에서 STUDENT 추상 데이터 타입을 위한 C 프로그래밍 언어 헤더 파일이다:
#include "person.h" #include "grade.h"
typedef struct { /* A STUDENT is a subset of PERSON. / / -------------------------------- */ PERSON *person;
GRADE *grade;
} STUDENT;
/* Constructor / / ----------- */ STUDENT *student_new( char *name ); #endif
다음은 간단한 학교 응용 프로그램에서 STUDENT 추상 데이터 타입을 위한 C 프로그래밍 언어 소스 파일이다:
STUDENT *student_new( char *name ) { STUDENT *student;
if ( ! ( student = calloc( 1, sizeof ( STUDENT ) ) ) )
{
fprintf(stderr,
"ERROR in %s/%s/%d: calloc() returned empty.\n",
,
,
);
exit( 1 );
}
/* Execute the constructor of the PERSON superclass. */
/* ------------------------------------------------- */
student->person = person_new( name );
return student;
}
다음은 시연을 위한 드라이버 프로그램이다:
int main( void ) { STUDENT *student = student_new( "The Student" ); student->grade = grade_new( 'a' );
printf( "%s: Numeric grade = %d\n",
/* Whereas a subset exists, inheritance does not. */
student->person->name,
/* Functional programming is executing functions just-in-time (JIT) */
grade_numeric( student->grade->letter ) );
return 0;
}
다음은 모든 것을 컴파일하기 위한 메이크파일이다:
clean: rm student_dvr *.o
student_dvr: student_dvr.c grade.o student.o person.o gcc student_dvr.c grade.o student.o person.o -o student_dvr
grade.o: grade.c grade.h gcc -c grade.c
student.o: student.c student.h gcc -c student.c
person.o: person.c person.h gcc -c person.c
객체 지향 객체를 구축하기 위한 공식적인 전략은 다음과 같다:[^89]
- 객체를 식별한다. 대부분 명사일 가능성이 높다.
- 각 객체의 속성을 식별한다. 객체를 설명하는 데 도움이 되는 것은 무엇인가?
- 각 객체의 행동을 식별한다. 대부분 동사일 가능성이 높다.
- 객체 간의 관계를 식별한다. 대부분 동사일 가능성이 높다.
예를 들어:
- 사람은 이름으로 식별되는 인간이다.
- 성적은 문자로 식별되는 성취이다.
- 학생은 성적을 받는 사람이다.
구문과 의미론

컴퓨터 프로그램의 구문은 문법을 형성하는 생성 규칙의 목록이다.[^90] 프로그래밍 언어의 문법은 선언, 표현식, 문장을 올바르게 배치한다.[^91] 언어의 구문을 보완하는 것은 의미론이다. 의미론은 다양한 구문 구조에 부여된 의미를 기술한다.[^92] 생성 규칙이 잘못된 해석을 가질 수 있기 때문에 구문 구조에 의미론적 설명이 필요할 수 있다.[^93] 또한, 서로 다른 언어가 동일한 구문을 가질 수 있지만, 동작은 다를 수 있다.
언어의 구문은 생성 규칙을 나열하여 공식적으로 기술된다. 자연 언어의 구문은 극도로 복잡하지만, 영어의 부분집합은 다음과 같은 생성 규칙 목록을 가질 수 있다:[^94]
- 문장은 명사구 다음에 동사구로 구성된다;
- 명사구는 관사 다음에 형용사 다음에 명사로 구성된다;
- 동사구는 동사 다음에 명사구로 구성된다;
- 관사는 'the'이다;
- 형용사는 'big'이거나
- 형용사는 'small'이다;
- 명사는 'cat'이거나
- 명사는 'mouse'이다;
- 동사는 'eats'이다; 굵은 글씨의 단어는 비단말 기호로 알려져 있다. '작은따옴표' 안의 단어는 단말 기호로 알려져 있다.[^95]
이 생성 규칙 목록에서 일련의 대체를 사용하여 완전한 문장을 형성할 수 있다.[^96] 과정은 비단말 기호를 유효한 비단말 기호 또는 유효한 단말 기호로 대체하는 것이다. 대체 과정은 단말 기호만 남을 때까지 반복된다. 하나의 유효한 문장은:
- 문장
- 명사구 동사구
- 관사 형용사 명사 동사구
- the 형용사 명사 동사구
- the big 명사 동사구
- the big cat 동사구
- the big cat 동사 명사구
- the big cat eats 명사구
- the big cat eats 관사 형용사 명사
- the big cat eats the 형용사 명사
- the big cat eats the small 명사
- the big cat eats the small mouse
그러나 다른 조합은 잘못된 문장을 만든다:
- the small mouse eats the big cat 따라서, eat 활동의 의미를 올바르게 기술하기 위해 의미론이 필요하다.
하나의 생성 규칙 목록 방법은 배커스-나우르 표기법(BNF)이라 불린다.[^97] BNF는 언어의 구문을 기술하며 그 자체도 구문을 가진다. 이 재귀적 정의는 메타언어의 예이다.[^92] BNF의 구문은 다음을 포함한다:
- ::=는 오른쪽에 비단말 기호가 있을 때 ~으로 구성된다로 번역된다. 오른쪽에 단말 기호가 있을 때 ~이다로 번역된다.
- |는 또는으로 번역된다.
- <와 >는 비단말 기호를 감싼다.
BNF를 사용하면, 영어의 부분집합은 다음과 같은 생성 규칙 목록을 가질 수 있다: ::= ::= ::=
BNF를 사용하면, 부호 있는 정수는 다음과 같은 생성 규칙 목록을 가진다:[^98] ::= ::= + | - ::= | ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
재귀적 생성 규칙에 주목하자: ::= | 이는 무한한 수의 가능성을 허용한다. 따라서 자릿수의 제한을 기술하기 위해 의미론이 필요하다.
생성 규칙에서 선행 0의 가능성에 주목하자: ::= | ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 따라서 선행 0을 무시해야 한다는 것을 기술하기 위해 의미론이 필요하다.
의미론을 기술하기 위한 두 가지 형식적 방법이 있다. 이들은 표시적 의미론과 공리적 의미론이다.[^99]
소프트웨어 공학과 컴퓨터 프로그래밍
.jpg) and Fran Bilas programmed the ENIAC by moving cables and setting switches.]]
and Fran Bilas programmed the ENIAC by moving cables and setting switches.]]
소프트웨어 공학은 품질 높은 컴퓨터 프로그램을 생산하기 위한 다양한 기법이다.[^100] 컴퓨터 프로그래밍은 소스 코드를 작성하거나 편집하는 과정이다. 공식적인 환경에서 시스템 분석가는 자동화할 조직의 모든 프로세스에 대한 정보를 관리자로부터 수집한다. 이 전문가는 그런 다음 새로운 시스템 또는 수정된 시스템에 대한 상세 계획을 준비한다.[^101] 이 계획은 건축가의 청사진에 비유할 수 있다.[^101]
성능 목표
시스템 분석가의 목표는 적절한 정보를 적절한 사람에게 적절한 시간에 전달하는 것이다.[^102] 이 목표를 달성하기 위한 핵심 요소는 다음과 같다:[^102]
- 출력의 품질. 출력이 의사 결정에 유용한가?
- 출력의 정확성. 실제 상황을 반영하는가?
- 출력의 형식. 출력이 쉽게 이해되는가?
- 출력의 속도. 시간에 민감한 정보는 고객과 실시간으로 소통할 때 중요하다.
비용 목표
성능 목표의 달성은 다음을 포함한 모든 비용과 균형을 이루어야 한다:[^103]
- 개발 비용.
- 고유성 비용. 재사용 가능한 시스템은 비용이 많이 들 수 있다. 그러나 제한적 사용 시스템보다 선호될 수 있다.
- 하드웨어 비용.
- 운영 비용.
시스템 개발 프로세스를 적용하면 다음과 같은 공리를 완화할 수 있다: 프로세스에서 오류가 늦게 발견될수록 수정 비용이 더 많이 든다.[^104]
폭포수 모델
폭포수 모델은 시스템 개발 프로세스의 구현이다.[^105] 폭포수라는 명칭이 암시하듯이, 기본 단계들은 서로 중첩된다:[^106]
- 조사 단계는 근본적인 문제를 이해하기 위한 것이다.
- 분석 단계는 가능한 해결책을 이해하기 위한 것이다.
- 설계 단계는 최적의 해결책을 계획하기 위한 것이다.
- 구현 단계는 최적의 해결책을 프로그래밍하기 위한 것이다.
- 유지보수 단계는 시스템의 수명 전체에 걸쳐 지속된다. 시스템이 배포된 후에도 변경이 필요할 수 있다.[^107] 명세 결함, 설계 결함 또는 코딩 결함을 포함한 결함이 존재할 수 있다. 개선이 필요할 수 있다. 변화하는 환경에 대응하기 위한 적응이 필요할 수 있다.
컴퓨터 프로그래머
컴퓨터 프로그래머는 상세 계획을 구현하기 위해 소스 코드를 작성하거나 수정하는 것을 담당하는 전문가이다.[^101] 대부분의 시스템은 한 명의 프로그래머가 완성하기에는 너무 크기 때문에 프로그래밍 팀이 필요할 가능성이 높다.[^108] 그러나 프로젝트에 프로그래머를 추가한다고 해서 완료 시간이 단축되지 않을 수 있다. 오히려 시스템의 품질이 저하될 수 있다.[^108] 효과적이려면 프로그램 모듈을 정의하고 팀원들에게 분배해야 한다.[^108] 또한 팀원들은 의미 있고 효과적인 방식으로 서로 상호작용해야 한다.[^108]
컴퓨터 프로그래머는 소규모 프로그래밍을 수행할 수 있다: 단일 모듈 내에서의 프로그래밍이다.[^109] 모듈이 다른 소스 코드 파일에 위치한 모듈을 실행할 가능성이 있다. 따라서 컴퓨터 프로그래머는 대규모 프로그래밍을 수행할 수 있다: 모듈들이 서로 효과적으로 결합되도록 프로그래밍하는 것이다.[^109] 대규모 프로그래밍에는 응용 프로그래밍 인터페이스(API)에 기여하는 것이 포함된다.
프로그램 모듈
모듈러 프로그래밍은 명령형 언어 프로그램을 정제하는 기법이다. 정제된 프로그램은 소프트웨어 크기를 줄이고, 책임을 분리하여 소프트웨어 노화를 완화할 수 있다. 프로그램 모듈은 블록 내에 한정되고 이름으로 식별되는 일련의 문장이다.[^110] 모듈에는 기능, 맥락, 논리가 있다:[^111]
- 모듈의 기능은 모듈이 수행하는 것이다.
- 모듈의 맥락은 수행 대상이 되는 요소들이다.
- 모듈의 논리는 기능을 수행하는 방법이다.
모듈의 이름은 먼저 기능에서, 그다음으로 맥락에서 도출되어야 한다. 논리는 이름의 일부가 되어서는 안 된다.[^111] 예를 들어, function compute_square_root( x ) 또는 function compute_square_root_integer( i : integer )는 적절한 모듈 이름이다. 그러나 function compute_square_root_by_division( x )는 적절하지 않다.
모듈 내부에서의 상호작용 정도는 응집도 수준이다.[^111] 응집도는 모듈의 이름과 기능 사이의 관계에 대한 판단이다. 모듈 간의 상호작용 정도는 결합도 수준이다.[^112] 결합도는 모듈의 맥락과 수행 대상이 되는 요소들 사이의 관계에 대한 판단이다.
응집도
응집도의 수준은 최악에서 최선 순으로 다음과 같다:[^113]
- 우연적 응집도: 모듈이 여러 기능을 수행하고 그 기능들이 완전히 무관한 경우 우연적 응집도를 갖는다. 예를 들어, function read_sales_record_print_next_line_convert_to_float(). 우연적 응집도는 관리부서가 어리석은 규칙을 강제할 때 실제로 발생한다. 예를 들어, "모든 모듈은 35개에서 50개 사이의 실행 가능한 문장을 가져야 한다."[^113]
- 논리적 응집도: 모듈이 일련의 기능을 사용할 수 있지만 그중 하나만 실행되는 경우 논리적 응집도를 갖는다. 예를 들어, function perform_arithmetic( perform_addition, a, b ).
- 시간적 응집도: 모듈이 시간과 관련된 기능을 수행하는 경우 시간적 응집도를 갖는다. 한 가지 예로, function initialize_variables_and_open_files(). 또 다른 예로, stage_one(), stage_two(), ...
- 절차적 응집도: 모듈이 느슨하게 관련된 여러 기능을 수행하는 경우 절차적 응집도를 갖는다. 예를 들어, function read_part_number_update_employee_record().
- 통신적 응집도: 모듈이 밀접하게 관련된 여러 기능을 수행하는 경우 통신적 응집도를 갖는다. 예를 들어, function read_part_number_update_sales_record().
- 정보적 응집도: 모듈이 여러 기능을 수행하지만 각 기능이 자체적인 진입점과 종료점을 갖는 경우 정보적 응집도를 갖는다. 또한 기능들은 동일한 데이터 구조를 공유한다. 객체 지향 클래스는 이 수준에서 작동한다.
- 기능적 응집도: 모듈이 지역 변수만을 사용하여 단일 목표를 달성하는 경우 기능적 응집도를 갖는다. 또한 다른 맥락에서 재사용할 수 있다.
결합도
결합도의 수준은 최악에서 최선 순으로 다음과 같다:[^112]
- 내용 결합도: 모듈이 다른 함수의 지역 변수를 수정하는 경우 내용 결합도를 갖는다. COBOL은 alter 동사로 이를 수행했었다.
- 공통 결합도: 모듈이 전역 변수를 수정하는 경우 공통 결합도를 갖는다.
- 제어 결합도: 다른 모듈이 해당 모듈의 제어 흐름을 수정할 수 있는 경우 제어 결합도를 갖는다. 예를 들어, perform_arithmetic( perform_addition, a, b ). 대신, 제어는 반환되는 객체의 구성에 기반해야 한다.
- 스탬프 결합도: 매개변수로 전달된 데이터 구조의 요소가 수정되는 경우 스탬프 결합도를 갖는다. 객체 지향 클래스는 이 수준에서 작동한다.
- 데이터 결합도: 모든 입력 매개변수가 필요하고 그 어느 것도 수정되지 않는 경우 데이터 결합도를 갖는다. 또한 함수의 결과는 단일 객체로 반환된다.
데이터 흐름 분석
데이터 흐름 분석은 기능적 응집도와 데이터 결합도를 갖는 모듈을 달성하기 위해 사용되는 설계 방법이다.[^114] 이 방법의 입력은 데이터 흐름 다이어그램이다. 데이터 흐름 다이어그램은 모듈을 나타내는 타원의 집합이다. 각 모듈의 이름은 타원 내부에 표시된다. 모듈은 실행 수준 또는 함수 수준일 수 있다.
다이어그램에는 모듈을 서로 연결하는 화살표도 있다. 모듈로 향하는 화살표는 입력의 집합을 나타낸다. 각 모듈은 단일 출력 객체를 나타내기 위해 하나의 화살표만 나가야 한다. (선택적으로 추가 예외 화살표가 나갈 수 있다.) 타원의 데이지 체인은 전체 알고리즘을 전달한다. 입력 모듈이 다이어그램을 시작해야 한다. 입력 모듈은 변환 모듈에 연결되어야 한다. 변환 모듈은 출력 모듈에 연결되어야 한다.[^115]
기능별 분류
.svg) interacts with the application software. The application software interacts with the operating system, which interacts with the hardware.]]
interacts with the application software. The application software interacts with the operating system, which interacts with the hardware.]]
컴퓨터 프로그램은 기능별로 분류할 수 있다. 주요 기능 분류는 응용 소프트웨어와 시스템 소프트웨어이다. 시스템 소프트웨어는 컴퓨터 하드웨어와 응용 소프트웨어를 연결하는 운영 체제를 포함한다.[^116] 운영 체제의 목적은 응용 소프트웨어가 편리하고 효율적으로 실행될 수 있는 환경을 제공하는 것이다.[^116] 응용 소프트웨어와 시스템 소프트웨어 모두 유틸리티 프로그램을 실행한다. 하드웨어 수준에서는 마이크로코드 프로그램이 중앙 처리 장치 전체의 회로를 제어한다.
응용 소프트웨어
응용 소프트웨어는 컴퓨터 시스템의 잠재력을 발휘하는 핵심 열쇠이다.[^117] 기업용 응용 소프트웨어는 회계, 인사, 고객 및 공급업체 애플리케이션을 하나로 묶는다. 예로는 전사적 자원 관리, 고객 관계 관리, 공급망 관리 소프트웨어가 있다.
기업용 애플리케이션은 독자적인 자체 소프트웨어로 사내에서 개발될 수 있다.[^118] 또는 기성 소프트웨어로 구매할 수도 있다. 구매한 소프트웨어는 맞춤형 소프트웨어를 제공하도록 수정될 수 있다. 애플리케이션을 맞춤화하는 경우, 회사의 자원을 사용하거나 외부에 위탁한다. 외주 소프트웨어 개발은 원래 소프트웨어 공급업체 또는 제3자 개발업체를 통해 이루어질 수 있다.[^119]
자체 소프트웨어의 잠재적 장점은 기능과 보고서를 정확히 사양에 맞게 개발할 수 있다는 것이다.[^120] 또한 경영진이 개발 과정에 참여하여 일정 수준의 통제력을 행사할 수 있다.[^121] 경영진은 경쟁사의 새로운 전략에 대응하거나 고객 또는 공급업체의 요구사항을 구현하기로 결정할 수 있다.[^122] 합병이나 인수로 인해 기업 소프트웨어 변경이 필요할 수도 있다. 자체 소프트웨어의 잠재적 단점은 시간과 자원 비용이 막대할 수 있다는 것이다.[^118] 또한 기능과 성능에 관한 위험이 도사리고 있을 수 있다.
기성 소프트웨어의 잠재적 장점은 초기 비용을 명확히 파악할 수 있고, 기본적인 요구사항이 충족되어야 하며, 성능과 신뢰성에 대한 실적이 있다는 것이다.[^118] 기성 소프트웨어의 잠재적 단점은 최종 사용자를 혼란스럽게 하는 불필요한 기능이 있을 수 있고, 기업에 필요한 기능이 부족할 수 있으며, 데이터 흐름이 기업의 업무 프로세스와 맞지 않을 수 있다는 것이다.[^118]
애플리케이션 서비스 제공업체
맞춤형 기업용 애플리케이션을 경제적으로 확보하는 한 가지 방법은 애플리케이션 서비스 제공업체를 이용하는 것이다.[^123] 전문 업체들이 하드웨어, 맞춤형 소프트웨어, 최종 사용자 지원을 제공한다. 이들은 숙련된 정보 시스템 인력을 보유하고 있어 새로운 애플리케이션의 개발을 가속화할 수 있다. 가장 큰 장점은 복잡한 컴퓨터 프로젝트의 인력 배치와 관리로부터 사내 자원을 해방시킨다는 것이다.[^123] 많은 애플리케이션 서비스 제공업체들은 정보 시스템 자원이 제한된 소규모의 빠르게 성장하는 기업을 대상으로 한다.[^123] 반면에 대규모 시스템을 갖춘 대기업은 이미 기술 인프라를 갖추고 있을 가능성이 높다. 한 가지 위험은 민감한 정보를 외부 조직에 맡겨야 한다는 것이다. 또 다른 위험은 제공업체의 인프라 신뢰성을 믿어야 한다는 것이다.[^123]
운영 체제
 vs. Thread Scheduling, Preemption, Context Switching|upright=1.8]]
운영 체제는 프로세스 스케줄링 및 주변 장치 제어와 같은 컴퓨터의 기본 기능을 지원하는 저수준 소프트웨어이다.[^116]
vs. Thread Scheduling, Preemption, Context Switching|upright=1.8]]
운영 체제는 프로세스 스케줄링 및 주변 장치 제어와 같은 컴퓨터의 기본 기능을 지원하는 저수준 소프트웨어이다.[^116]
1950년대에는 운영자이기도 했던 프로그래머가 프로그램을 작성하고 실행했다. 프로그램 실행이 끝나면 출력이 인쇄되거나, 나중에 처리하기 위해 종이 테이프나 카드에 천공되었다.[^26] 대부분의 경우 프로그램은 제대로 작동하지 않았다. 그러면 프로그래머는 콘솔 표시등을 살펴보고 콘솔 스위치를 조작했다. 운이 좋지 않으면 추가 분석을 위해 메모리 출력물을 만들었다. 1960년대에 프로그래머들은 운영자의 작업을 자동화하여 낭비되는 시간을 줄였다. 운영 체제라 불리는 프로그램이 항상 컴퓨터에 상주하게 되었다.[^124]
운영 체제라는 용어는 두 가지 수준의 소프트웨어를 가리킬 수 있다.[^125] 운영 체제는 프로세스, 메모리, 장치를 관리하는 커널 프로그램을 가리킬 수 있다. 더 넓은 의미에서, 운영 체제는 핵심 소프트웨어의 전체 패키지를 가리킬 수 있다. 이 패키지에는 커널 프로그램, 명령줄 인터프리터, 그래픽 사용자 인터페이스, 유틸리티 프로그램, 편집기가 포함된다.[^125]
커널 프로그램

커널의 주요 목적은 컴퓨터의 제한된 자원을 관리하는 것이다:
- 커널 프로그램은 프로세스 스케줄링을 수행해야 하며,[^126] 이는 문맥 전환이라고도 한다. 커널은 컴퓨터 프로그램이 실행을 위해 선택되면 프로세스 제어 블록을 생성한다. 그러나 실행 중인 프로그램은 시간 조각 동안만 중앙 처리 장치에 대한 독점적 접근 권한을 갖는다. 각 사용자에게 연속적인 접근의 인상을 제공하기 위해, 커널은 각 프로세스 제어 블록을 신속하게 선점하여 다른 것을 실행한다. 시스템 개발자의 목표는 디스패치 지연 시간을 최소화하는 것이다.

- 커널 프로그램은 메모리 관리를 수행해야 한다.
- 커널이 처음 실행 파일을 메모리에 적재할 때, 주소 공간을 논리적으로 영역으로 나눈다.[^127] 커널은 마스터 영역 테이블과 다수의 프로세스별 영역(pregion) 테이블—실행 중인 각 프로세스당 하나—을 유지한다.[^127] 이 테이블들이 가상 주소 공간을 구성한다. 마스터 영역 테이블은 그 내용이 물리 메모리 내 어디에 위치하는지 결정하는 데 사용된다. pregion 테이블은 각 프로세스가 고유한 프로그램(텍스트) pregion, 데이터 pregion, 스택 pregion을 가질 수 있게 한다. *프로그램 pregion은 기계 명령어를 저장한다. 기계 명령어는 변경되지 않으므로, 프로그램 pregion은 동일한 실행 파일의 여러 프로세스가 공유할 수 있다.[^127]
- 시간과 메모리를 절약하기 위해, 커널은 전체 실행 파일을 완전히 적재하지 않고 디스크 드라이브에서 실행 명령어 블록만 적재할 수 있다.[^126] *커널은 가상 주소를 물리 주소로 변환하는 역할을 한다. 커널이 메모리 컨트롤러에 데이터를 요청했으나 대신 페이지 폴트를 받을 수 있다.[^128] 이 경우, 커널은 메모리 관리 장치에 접근하여 물리 데이터 영역을 채우고 주소를 변환한다.[^129]
- 커널은 프로세스의 요청에 따라 힙에서 메모리를 할당한다.[^60] 프로세스가 메모리 사용을 마치면, 해제를 요청할 수 있다. 프로세스가 할당된 모든 메모리의 해제를 요청하지 않고 종료하면, 커널이 가비지 컬렉션을 수행하여 메모리를 해제한다.
- 커널은 또한 프로세스가 커널이나 다른 프로세스의 메모리가 아닌 자기 자신의 메모리에만 접근하도록 보장한다.[^126]
- 커널 프로그램은 파일 시스템 관리를 수행해야 한다.[^126] 커널은 파일을 생성, 검색, 갱신, 삭제하는 명령어를 가지고 있다.
- 커널 프로그램은 장치 관리를 수행해야 한다.[^126] 커널은 마우스, 키보드, 디스크 드라이브, 프린터 및 기타 장치에 대한 인터페이스를 표준화하고 단순화하는 프로그램을 제공한다. 또한 두 프로세스가 동시에 장치를 요청하면 커널이 접근을 중재해야 한다.
- 커널 프로그램은 네트워크 관리를 수행해야 한다.[^130] 커널은 프로세스를 대신하여 패킷을 송수신한다. 핵심 서비스 중 하나는 대상 시스템으로의 효율적인 경로를 찾는 것이다.
- 커널 프로그램은 프로그래머가 사용할 수 있는 시스템 수준 함수를 제공해야 한다.[^131] ** 프로그래머는 비교적 단순한 인터페이스를 통해 파일에 접근하며, 이 인터페이스는 비교적 복잡한 저수준 입출력 인터페이스를 실행한다. 저수준 인터페이스에는 파일 생성, 파일 디스크립터, 파일 탐색, 물리적 읽기, 물리적 쓰기가 포함된다. ** 프로그래머는 비교적 단순한 인터페이스를 통해 프로세스를 생성하며, 이 인터페이스는 비교적 복잡한 저수준 인터페이스를 실행한다. ** 프로그래머는 비교적 단순한 인터페이스를 통해 날짜/시간 산술을 수행하며, 이 인터페이스는 비교적 복잡한 저수준 시간 인터페이스를 실행한다.[^132]
- 커널 프로그램은 실행 중인 프로세스 간의 통신 채널을 제공해야 한다.[^133] 대규모 소프트웨어 시스템의 경우, 시스템을 더 작은 프로세스로 설계하는 것이 바람직할 수 있다. 프로세스는 신호를 보내고 받음으로써 서로 통신할 수 있다.
원래 운영 체제는 어셈블리어로 프로그래밍되었으나, 현대의 운영 체제는 일반적으로 C, Objective-C, Swift와 같은 고급 언어로 작성된다.
유틸리티 프로그램
유틸리티는 시스템 관리와 소프트웨어 실행을 지원하는 프로그램이다. 운영 체제는 일반적으로 저장 장치, 메모리, 스피커, 프린터 등의 하드웨어를 점검하는 유틸리티를 제공한다.[^134] 유틸리티는 저장 장치의 성능을 최적화할 수 있다. 시스템 유틸리티는 하드웨어와 네트워크 성능을 모니터링하며 지표가 정상 범위를 벗어나면 경고를 발생시킬 수 있다.[^135] 유틸리티는 파일을 압축하여 저장 공간과 네트워크 전송 시간을 줄일 수 있다.[^134] 유틸리티는 데이터 세트를 정렬하고 병합하거나[^135] 컴퓨터 바이러스를 탐지할 수 있다.[^135]
마이크로코드 프로그램





마이크로코드 프로그램은 소프트웨어 구동 컴퓨터의 데이터 경로를 제어하는 최하위 수준의 인터프리터이다.[^137] (하드웨어의 발전으로 이러한 연산들은 하드웨어 실행 회로로 이전되었다.)[^137] 마이크로코드 명령어는 프로그래머가 디지털 논리 수준[^138]—컴퓨터의 실제 하드웨어—을 더 쉽게 구현할 수 있게 해준다. 디지털 논리 수준은 컴퓨터 과학과 컴퓨터 공학 사이의 경계이다.[^139]
논리 게이트는 켜짐 또는 꺼짐의 두 가지 신호 중 하나를 반환할 수 있는 작은 트랜지스터이다.[^140]
- 트랜지스터 하나로 NOT 게이트를 구성한다.
- 두 개의 트랜지스터를 직렬로 연결하면 NAND 게이트를 구성한다.
- 두 개의 트랜지스터를 병렬로 연결하면 NOR 게이트를 구성한다.
- NOT 게이트를 NAND 게이트에 연결하면 AND 게이트를 구성한다.
- NOT 게이트를 NOR 게이트에 연결하면 OR 게이트를 구성한다.
이 다섯 가지 게이트는 이진 대수—컴퓨터의 디지털 논리 함수—의 기본 구성 요소를 이룬다.
마이크로코드 명령어는 프로그래머가 이진 대수로 구성하는 대신 디지털 논리 함수를 실행하기 위해 사용할 수 있는 니모닉이다. 이들은 중앙 처리 장치(CPU)의 제어 저장소에 저장된다.[^141] 이러한 하드웨어 수준의 명령어는 데이터 경로를 통해 데이터를 이동시킨다.
마이크로 명령어 주기는 마이크로시퀀서가 마이크로프로그램 카운터를 사용하여 랜덤 액세스 메모리에서 다음 기계 명령어를 인출하는 것으로 시작된다.[^142] 다음 단계는 하드웨어 모듈로의 적절한 출력 라인을 선택하여 기계 명령어를 해독하는 것이다.[^143] 마지막 단계는 하드웨어 모듈의 게이트 집합을 사용하여 명령어를 실행하는 것이다.

산술을 수행하는 명령어는 산술 논리 장치(ALU)를 통해 전달된다.[^144] ALU는 정수의 덧셈, 시프트, 비교를 위한 기본 연산을 수행하는 회로를 갖추고 있다. ALU를 통해 기본 연산을 조합하고 반복함으로써, CPU는 복잡한 산술 연산을 수행한다.
마이크로코드 명령어는 CPU와 메모리 컨트롤러 사이에서 데이터를 이동시킨다. 메모리 컨트롤러 마이크로코드 명령어는 두 개의 레지스터를 조작한다. 메모리 주소 레지스터는 각 메모리 셀의 주소에 접근하는 데 사용된다. 메모리 데이터 레지스터는 각 셀의 내용을 설정하고 읽는 데 사용된다.[^145]
주석
참고 문헌
[^1]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 7 quote = An alternative to
[^2]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^3]: cite book last = Silberschatz first = Abraham title = Operating System Concepts, Fourth Edition publisher = Addison-Wesley year = 1994 page = 98 quote = Informally, a proce
[^4]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^5]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 7 isbn = 0-201-71012-9
[^6]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 30 isbn = 0-201-71012-9
[^7]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 31 isbn = 0-201-71012-9
[^8]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 30 isbn = 0-201-71012-9
[^9]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 30 isbn = 0-201-71012-9
[^10]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^11]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^12]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^13]: cite book last = Rosen first = Kenneth H. title = Discrete Mathematics and Its Applications publisher = McGraw-Hill, Inc. year = 1991 page = [https://archive.org/details/discre
[^14]: cite book last = Linz first = Peter title = An Introduction to Formal Languages and Automata publisher = D. C. Heath and Company year = 1990 page = 234 isbn = 978-0-669-173
[^15]: cite book last = Linz first = Peter title = An Introduction to Formal Languages and Automata publisher = D. C. Heath and Company year = 1990 page = 243 isbn = 978-0-669-173
[^16]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^17]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^18]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^19]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^20]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^21]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^22]: cite book last = McCartney first = Scott title = ENIAC – The Triumphs and Tragedies of the World's First Computer publisher = Walker and Company year = 1999 page = [https://arc
[^23]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^24]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 27 isbn = 0-201-71012-9
[^25]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 29 isbn = 0-201-71012-9
[^26]: cite book last = Silberschatz first = Abraham title = Operating System Concepts, Fourth Edition publisher = Addison-Wesley year = 1994 page = 6 isbn = 978-0-201-50480-4
[^27]: cite book url=https://books.google.com/books?id=UUbB3d2UnaAC&pg=PA46 title=To the Digital Age: Research Labs, Start-up Companies, and the Rise of MOS publisher=Johns Hopkins University Press
[^28]: cite web url=https://www.osti.gov/servlets/purl/1497235 title=Manufacturing of Silicon Materials for Microelectronics and Solar PV publisher=Sandia National Laboratories year=2017 acces
[^29]: cite web url=https://www.britannica.com/technology/integrated-circuit/Fabricating-ICs#ref837156 title=Fabricating ICs Making a base wafer publisher=Britannica access-date=February 8, 2022
[^30]: cite web author1=Anysilicon url=https://anysilicon.com/introduction-to-nmos-and-pmos-transistors/ title=Introduction to NMOS and PMOS Transistors work=AnySilicon date=4 November 2021
[^31]: cite web url=https://www.britannica.com/technology/microprocessor#ref36149 title=microprocessor definition publisher=Britannica access-date=April 1, 2022 archive-date=April 1, 2022 a
[^32]: cite web url=https://spectrum.ieee.org/chip-hall-of-fame-intel-4004-microprocessor title=Chip Hall of Fame: Intel 4004 Microprocessor publisher=Institute of Electrical and Electronics Enginee
[^33]: cite web url=https://www.computer-museum.ru/books/archiv/ibm36040.pdf archive-url=https://ghostarchive.org/archive/20221010/https://www.computer-museum.ru/books/archiv/ibm36040.pdf archive-date=2
[^34]: cite web url=https://books.google.com/books?id=VDAEAAAAMBAJ&pg=PA22 title=Bill Gates, Microsoft and the IBM Personal Computer publisher=InfoWorld date=August 23, 1982 access-date=1 Febr
[^35]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 10 isbn = 978-0-321-56384-2
[^36]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 11 isbn = 978-0-321-56384-2
[^37]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 159 isbn = 0-619-06489-7
[^38]: cite book last = Linz first = Peter title = An Introduction to Formal Languages and Automata publisher = D. C. Heath and Company year = 1990 page = 2 isbn = 978-0-669-17342
[^39]: cite book last = Weiss first = Mark Allen title = Data Structures and Algorithm Analysis in C++ publisher = Benjamin/Cummings Publishing Company, Inc. year = 1994 page = 29
[^40]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^41]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 160 isbn = 0-619-06489-7
[^42]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^43]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^44]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Third Edition publisher = Prentice Hall year = 1990 page = [https://archive.org/details/s
[^45]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 26 isbn = 0-201-71012-9
[^46]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 37 isbn = 0-201-71012-9
[^47]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 160 isbn = 0-619-06489-7 quote =
[^48]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Second Edition publisher = Addison-Wesley year = 1993 page = 75 isbn = 978-0-201-56885-
[^49]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 40 isbn = 978-0-321-56384-2
[^50]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 16 isbn = 0-201-71012-9
[^51]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 24 isbn = 0-201-71012-9
[^52]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 25 isbn = 0-201-71012-9
[^53]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 19 isbn = 0-201-71012-9
[^54]: cite web url = https://www.geeksforgeeks.org/memory-layout-of-c-program/ title = Memory Layout of C Programs date = 12 September 2011 access-date = 6 November 2021 archive-date = 6 November
[^55]: Kernighan, Brian W.. The C Programming Language Second Edition. Prentice Hall
[^56]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 128 isbn = 0-201-71012-9
[^57]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^58]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^59]: Kernighan, Brian W.. The C Programming Language Second Edition. Prentice Hall
[^60]: Kernighan, Brian W.. The C Programming Language Second Edition. Prentice Hall
[^61]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 38 isbn = 0-201-71012-9
[^62]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 193 isbn = 0-201-71012-9
[^63]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 39 isbn = 0-201-71012-9
[^64]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 35 isbn = 0-201-71012-9
[^65]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 192 isbn = 0-201-71012-9
[^66]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 22 isbn = 978-0-321-56384-2
[^67]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 21 isbn = 978-0-321-56384-2
[^68]: cite book last = Stroustrup first = Bjarne title = The C++ Programming Language, Fourth Edition publisher = Addison-Wesley year = 2013 page = 49 isbn = 978-0-321-56384-2
[^69]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 218 isbn = 0-201-71012-9
[^70]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 217 isbn = 0-201-71012-9
[^71]: cite book last = Weiss first = Mark Allen title = Data Structures and Algorithm Analysis in C++ publisher = Benjamin/Cummings Publishing Company, Inc. year = 1994 page = 103
[^72]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 230 isbn = 0-201-71012-9
[^73]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 240 isbn = 0-201-71012-9
[^74]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 241 isbn = 0-201-71012-9
[^75]: cite book last1=Jones first1=Robin last2=Maynard first2=Clive last3=Stewart first3=Ian title=The Art of Lisp Programming date=December 6, 2012 publisher=Springer Science & B
[^76]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 220 isbn = 0-201-71012-9
[^77]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 221 isbn = 0-201-71012-9
[^78]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 229 isbn = 0-201-71012-9
[^79]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 227 isbn = 0-201-71012-9
[^80]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 222 isbn = 0-201-71012-9
[^81]: cite web last = Gordon first = Michael J. C. author-link = Michael J. C. Gordon year = 1996 title = From LCF to HOL: a short history url = http://www.cl.cam.ac.uk/~mjcg/papers/HolHis
[^82]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 233 isbn = 0-201-71012-9
[^83]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 235 isbn = 0-201-71012-9
[^84]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 55 isbn = 0-201-71012-9
[^85]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 35 isbn = 0-201-71012-9
[^86]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 39 isbn = 0-201-71012-9
[^87]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 284 isbn = 0-256-08515-3
[^88]: cite book last = Weiss first = Mark Allen title = Data Structures and Algorithm Analysis in C++ publisher = Benjamin/Cummings Publishing Company, Inc. year = 1994 page = 57
[^89]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 285 isbn = 0-256-08515-3
[^90]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 290 quote = The syntax (or
[^91]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 78 isbn = 0-201-71012-9
[^92]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 290 isbn = 0-201-71012-9
[^93]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 294 isbn = 0-201-71012-9
[^94]: cite book last = Rosen first = Kenneth H. title = Discrete Mathematics and Its Applications publisher = McGraw-Hill, Inc. year = 1991 page = [https://archive.org/details/discre
[^95]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 291 isbn = 0-201-71012-9
[^96]: cite book last = Rosen first = Kenneth H. title = Discrete Mathematics and Its Applications publisher = McGraw-Hill, Inc. year = 1991 page = [https://archive.org/details/discre
[^97]: cite book last = Rosen first = Kenneth H. title = Discrete Mathematics and Its Applications publisher = McGraw-Hill, Inc. year = 1991 page = [https://archive.org/details/discre
[^98]: cite book last = Rosen first = Kenneth H. title = Discrete Mathematics and Its Applications publisher = McGraw-Hill, Inc. year = 1991 page = [https://archive.org/details/discre
[^99]: cite book last = Wilson first = Leslie B. title = Comparative Programming Languages, Third Edition publisher = Addison-Wesley year = 2001 page = 297 isbn = 0-201-71012-9
[^100]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = Preface isbn = 0-256-08515-3
[^101]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 507 isbn = 0-619-06489-7
[^102]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 513 isbn = 0-619-06489-7
[^103]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 514 isbn = 0-619-06489-7
[^104]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 516 isbn = 0-619-06489-7
[^105]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 8 isbn = 0-256-08515-3
[^106]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 517 isbn = 0-619-06489-7
[^107]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 345 isbn = 0-256-08515-3
[^108]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 319 isbn = 0-256-08515-3
[^109]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 331 isbn = 0-256-08515-3
[^110]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 216 isbn = 0-256-08515-3
[^111]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 219 isbn = 0-256-08515-3
[^112]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 226 isbn = 0-256-08515-3
[^113]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 220 isbn = 0-256-08515-3
[^114]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 258 isbn = 0-256-08515-3
[^115]: cite book last = Schach first = Stephen R. title = Software Engineering publisher = Aksen Associates Incorporated Publishers year = 1990 page = 259 isbn = 0-256-08515-3
[^116]: cite book last = Silberschatz first = Abraham title = Operating System Concepts, Fourth Edition publisher = Addison-Wesley year = 1994 page = 1 isbn = 978-0-201-50480-4
[^117]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 147 isbn = 0-619-06489-7 quote =
[^118]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 147 isbn = 0-619-06489-7
[^119]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 147 isbn = 0-619-06489-7 quote =
[^120]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 148 isbn = 0-619-06489-7 quote =
[^121]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 148 isbn = 0-619-06489-7 quote =
[^122]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 147 isbn = 0-619-06489-7 quote =
[^123]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 149 isbn = 0-619-06489-7
[^124]: Tanenbaum, Andrew S.. Structured Computer Organization, Third Edition. Prentice Hall
[^125]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^126]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^127]: cite book last = Bach first = Maurice J. title = The Design of the UNIX Operating System publisher = Prentice-Hall, Inc. year = 1986 page = 152 isbn = 0-13-201799-7
[^128]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 443 isbn = 978-0-13-291652-3
[^129]: cite book last = Lacamera first = Daniele title = Embedded Systems Architecture publisher = Packt year = 2018 page = 8 isbn = 978-1-78883-250-2
[^130]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^131]: Kernighan, Brian W.. The Unix Programming Environment. Prentice Hall
[^132]: Kerrisk, Michael. The Linux Programming Interface. No Starch Press
[^133]: Haviland, Keith. Unix System Programming. Addison-Wesley Publishing Company
[^134]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 145 isbn = 0-619-06489-7
[^135]: cite book last = Stair first = Ralph M. title = Principles of Information Systems, Sixth Edition publisher = Thomson year = 2003 page = 146 isbn = 0-619-06489-7
[^136]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 5 isbn = 978-0-13-291652-3
[^137]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 6 isbn = 978-0-13-291652-3
[^138]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 243 isbn = 978-0-13-291652-3
[^139]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 147 isbn = 978-0-13-291652-3
[^140]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 148 isbn = 978-0-13-291652-3
[^141]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 253 isbn = 978-0-13-291652-3
[^142]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 255 isbn = 978-0-13-291652-3
[^143]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 161 isbn = 978-0-13-291652-3
[^144]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 166 isbn = 978-0-13-291652-3
[^145]: cite book last = Tanenbaum first = Andrew S. title = Structured Computer Organization, Sixth Edition publisher = Pearson year = 2013 page = 249 isbn = 978-0-13-291652-3
[^146]: cite journal first = Allan G. last = Bromley author-link = Allan G. Bromley year = 1998 url = https://profs.scienze.univr.it/~manca/storia-informatica/babbage.pdf title = Charl
[^147]: (October–December 2003)
[^148]: Huskey, Harry D.. EDVAC. John Wiley and Sons Ltd.. (2003-01-01)
[^149]: Wilkes, M. V.. The EDSAC. Springer. (1982)
[^150]: Cite journal publisher = Association for Computing Machinery doi = 10.1145/155360.155362 first1 = A. last1 = Colmerauer first2 = P. last2 = Roussel title = The birth of Prolog
관련 인사이트

디지털 트윈, 당신 공장엔 이미 있다 — 엑셀과 MES 사이 어딘가에
디지털 트윈은 10억짜리 3D 시뮬레이션이 아니다. 지금 쓰고 있는 엑셀에 좋은 질문 하나를 더하는 것 — 두 전문가가 중소 제조기업이 이미 가진 데이터로 예측하는 공장을 만드는 현실적 로드맵을 제시한다.

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.

그 30분을 18년 동안 매일 반복했습니다 — 품질팀장이 본 AI Agent
18년차 품질팀장이 매일 아침 30분씩 반복하던 데이터 분석을 AI Agent가 3분 만에 해냈습니다. 챗봇과는 완전히 다른 물건 — 직접 시스템에 접근해서 데이터를 꺼내고 분석하는 AI의 현장 도입기.