딥러닝
Let me produce the Korean translation directly.
![딥러닝에서 여러 추상화 계층으로 이미지를 표현하는 방식^162 ]
{kind=link}
기계 학습에서 딥러닝(DL)은 분류, 회귀, 표현 학습 등의 작업을 수행하기 위해 다층 신경망을 활용하는 데 초점을 맞춘다. 이 분야는 생물학적 신경과학에서 영감을 얻었으며, 인공 뉴런을 여러 층으로 쌓아 올리고 데이터를 처리하도록 "훈련"시키는 것을 중심으로 한다. "딥(깊은)"이라는 수식어는 네트워크에서 여러 층(3개에서 수백 또는 수천 개에 이르는)을 사용하는 것을 의미한다. 사용되는 방법은 지도 학습, 준지도 학습 또는 비지도 학습일 수 있다.[^1]
일반적인 딥러닝 네트워크 아키텍처로는 완전 연결 네트워크, 심층 신뢰 네트워크, 순환 신경망, 합성곱 신경망, 생성적 적대 신경망, 트랜스포머, 신경 방사 필드 등이 있다. 이러한 아키텍처는 컴퓨터 비전, 음성 인식, 자연어 처리, 기계 번역, 생물정보학, 약물 설계, 의료 영상 분석, 기후 과학, 재료 검사, 보드 게임 프로그램 등의 분야에 적용되어 왔으며, 인간 전문가의 성능에 필적하거나 경우에 따라서는 이를 능가하는 결과를 산출해 왔다.[^2][^3][^163]
초기 형태의 신경망은 생물학적 시스템, 특히 인간의 뇌에서의 정보 처리 및 분산 통신 노드에서 영감을 받았다. 그러나 현재의 신경망은 생물체의 뇌 기능을 모델링하려는 것이 아니며, 일반적으로 그러한 목적에는 낮은 품질의 모델로 간주된다.[^164]
개요
대부분의 현대 딥러닝 모델은 합성곱 신경망과 트랜스포머 같은 다층 신경망에 기반하고 있지만, 심층 신뢰 신경망과 심층 볼츠만 머신의 노드처럼 심층 생성 모델에서 층별로 구성된 명제 공식이나 잠재 변수를 포함할 수도 있다.[^4]
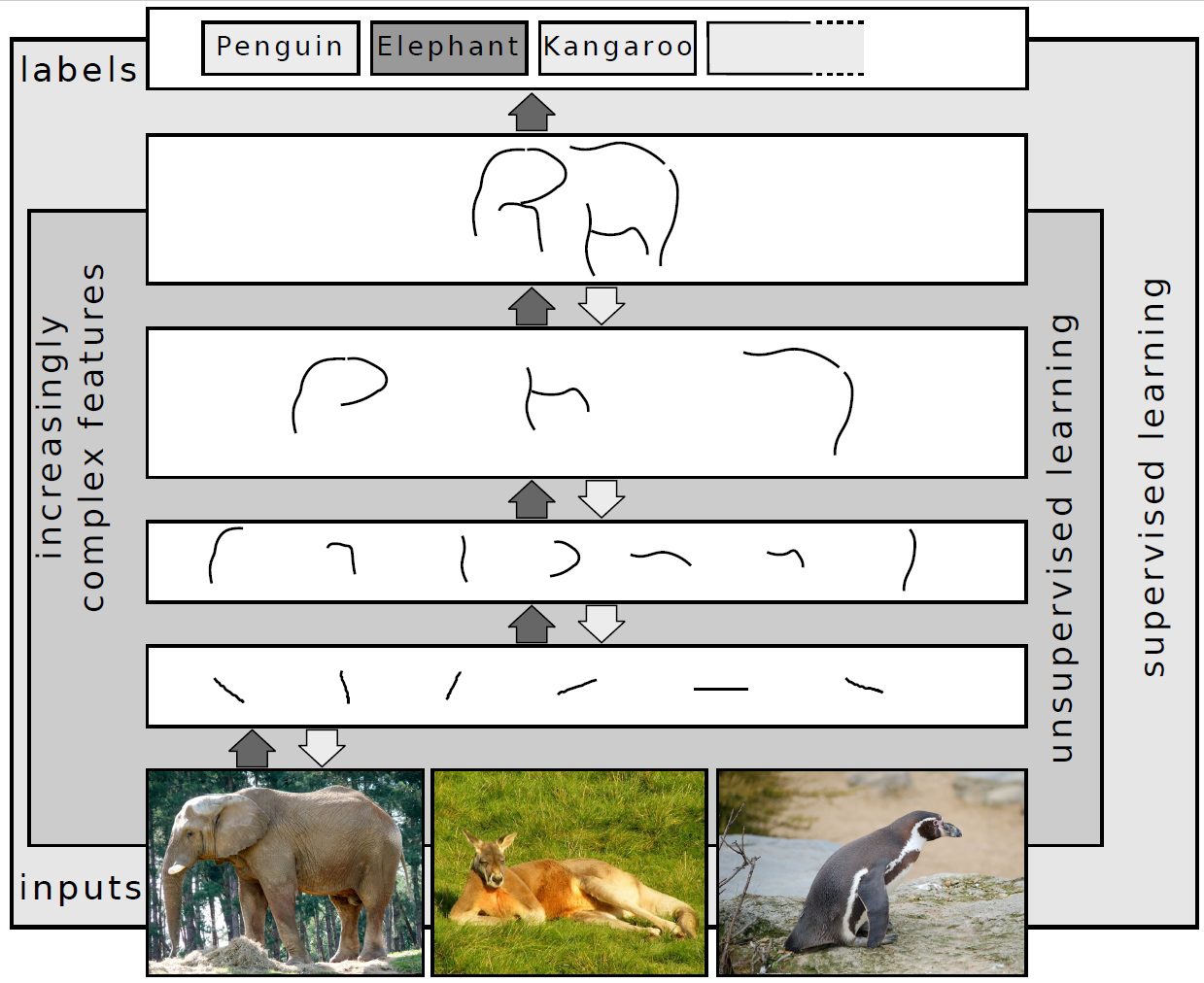
근본적으로 딥러닝은 입력 데이터를 점진적으로 더 추상적이고 복합적인 표현으로 변환하기 위해 계층 구조의 층을 사용하는 기계 학습 알고리즘의 한 부류를 말한다. 예를 들어, 이미지 인식 모델에서 원시 입력은 이미지(픽셀의 텐서로 표현됨)일 수 있다. 첫 번째 표현 층은 선과 원 같은 기본 도형을 식별하려 할 수 있고, 두 번째 층은 가장자리의 배열을 구성하고 부호화할 수 있으며, 세 번째 층은 코와 눈을 부호화할 수 있고, 네 번째 층은 이미지에 얼굴이 포함되어 있음을 인식할 수 있다.
중요한 점은 딥러닝 과정이 어떤 특징을 어떤 수준에 최적으로 배치할지를 스스로 학습할 수 있다는 것이다. 딥러닝 이전에는 기계 학습 기법에서 분류 알고리즘이 작동하기에 더 적합한 표현으로 데이터를 변환하기 위해 수작업 특징 공학을 사용하는 경우가 많았다. 딥러닝 접근법에서는 특징이 수작업으로 설계되지 않으며, 모델이 데이터로부터 유용한 특징 표현을 자동으로 발견한다. 이것이 수동 조정의 필요성을 완전히 없애는 것은 아니다. 예를 들어, 다양한 층의 수와 층 크기는 서로 다른 수준의 추상화를 제공할 수 있다.[^5][^1]
"딥러닝"에서 "딥(심층)"이라는 단어는 데이터가 변환되는 층의 수를 가리킨다. 더 정확히 말하면, 딥러닝 시스템은 상당한 기여 할당 경로(CAP) 깊이를 가진다. CAP는 입력에서 출력까지의 변환 사슬이다. CAP는 입력과 출력 사이의 잠재적 인과 관계를 기술한다. 순방향 신경망의 경우 CAP의 깊이는 네트워크의 깊이이며 은닉층의 수에 1을 더한 값이다(출력층도 매개변수화되기 때문이다). 순환 신경망의 경우 신호가 하나의 층을 한 번 이상 통과할 수 있으므로 CAP 깊이는 잠재적으로 무한하다.[^14] 얕은 학습과 딥러닝을 구분하는 보편적으로 합의된 깊이의 임계값은 없지만, 대부분의 연구자들은 딥러닝이 2보다 큰 CAP 깊이를 포함한다는 데 동의한다. 깊이 2의 CAP는 어떤 함수든 모방할 수 있다는 의미에서 보편 근사기임이 증명되었다.[^165] 그 이상으로 층을 추가해도 네트워크의 함수 근사 능력이 향상되지는 않는다. 심층 모델(CAP > 2)은 얕은 모델보다 더 나은 특징을 추출할 수 있으며, 따라서 추가 층이 특징을 효과적으로 학습하는 데 도움이 된다.
딥러닝 아키텍처는 탐욕적 층별 방법으로 구축할 수 있다.[^6] 딥러닝은 이러한 추상화를 풀어내고 성능을 향상시키는 특징을 선별하는 데 도움이 된다.[^5]
딥러닝 알고리즘은 비지도 학습 과제에 적용할 수 있다. 레이블이 없는 데이터가 레이블이 있는 데이터보다 더 풍부하기 때문에 이것은 중요한 이점이다. 비지도 방식으로 훈련할 수 있는 심층 구조의 예로는 심층 신뢰 신경망이 있다.[^5][^7]
딥러닝이라는 용어는 1986년 리나 데흐터에 의해 기계 학습 커뮤니티에 도입되었고,^8 2000년에 이고르 아이젠버그와 동료들에 의해 부울 임계값 뉴런의 맥락에서 인공 신경망 분야에 도입되었다.[^9][^166] 다만 이 용어의 등장 역사는 분명히 더 복잡한 것으로 보인다.[^167]
해석
심층 신경망은 일반적으로 보편 근사 정리[^10]^11 또는 확률적 추론의 관점에서 해석된다.[^168][^13][^5][^14][^15]
고전적인 보편 근사 정리는 유한한 크기의 단일 은닉층을 가진 순방향 신경망이 연속 함수를 근사하는 능력에 관한 것이다.[^10][^11] 1989년, 조지 사이벤코(George Cybenko)가 시그모이드 활성화 함수에 대한 최초의 증명을 발표하였고[^10], 1991년 쿠르트 호르닉(Kurt Hornik)이 이를 순방향 다층 구조로 일반화하였다.[^11] 최근 연구에서는 후쿠시마 구니히코(Kunihiko Fukushima)의 정류 선형 유닛과 같은 비유계 활성화 함수에 대해서도 보편 근사가 성립함을 보였다.[^16][^17]
심층 신경망에 대한 보편 근사 정리는 너비가 제한되어 있지만 깊이는 증가할 수 있는 네트워크의 능력에 관한 것이다. 루(Lu) 등은[^18]
역사
1980년 이전
인공 신경망(ANN)에는 두 가지 유형이 있다: 순방향 신경망(FNN) 또는 다층 퍼셉트론(MLP)과 순환 신경망(RNN)이다. RNN은 연결 구조에 순환이 있지만, FNN에는 없다. 1920년대에 빌헬름 렌츠와 에른스트 이징은 본질적으로 뉴런과 유사한 임계값 요소로 구성된 비학습 RNN 구조인 이징 모델을 만들었다.[^19][^20] 1972년에 아마리 슌이치는 이 구조를 적응형으로 만들었다.[^21][^32] 그의 학습 RNN은 1982년에 존 홉필드에 의해 재발표되었다.[^22] 다른 초기 순환 신경망은 1971년에 나카노 카오루에 의해 발표되었다.[^23][^24] 이미 1948년에 앨런 튜링은 생전에 출판되지 않은 "지능형 기계"에 관한 연구를 수행했으며,[^25] 여기에는 "인공 진화 및 학습 RNN과 관련된 아이디어"가 포함되어 있었다.[^32]
프랭크 로젠블랫(1958)[^169]은 입력층, 학습하지 않는 무작위 가중치를 가진 은닉층, 출력층의 3개 층으로 구성된 MLP인 퍼셉트론을 제안했다. 그는 이후 1962년에 변형과 컴퓨터 실험을 소개하는 책을 출판했는데, 여기에는 마지막 두 층이 학습된 가중치를 가진 "적응형 전단말 네트워크를 가진" 4층 퍼셉트론 버전도 포함되어 있었다(여기서 그는 H. D. Block과 B. W. Knight의 공로를 인정한다).[^26] 이 책은 R. D. Joseph(1960)의 이전 네트워크를 인용하며,[^27] 이 4층 시스템의 "변형과 기능적으로 동등한" 것이라고 설명한다(이 책에서 Joseph은 30회 이상 언급된다). 따라서 Joseph을 학습 은닉 유닛을 가진 적절한 적응형 다층 퍼셉트론의 창시자로 간주해야 하는가? 불행히도, 그 학습 알고리즘은 기능적인 것이 아니었으며 망각 속으로 사라졌다.
최초의 작동하는 심층 학습 알고리즘은 임의의 깊이의 신경망을 훈련하는 방법인 데이터 처리 그룹 방법으로, 1965년에 알렉세이 이바흐넨코와 라파가 발표했다. 그들은 이를 다항 회귀의 한 형태,[^28] 또는 더 복잡하고 비선형적이며 계층적인 관계를 처리하기 위한 로젠블랫 퍼셉트론의 일반화로 간주했다.[^170] 1971년 논문에서는 이 방법으로 훈련된 8개 층의 심층 네트워크를 설명했는데,[^29] 이는 회귀 분석을 통한 층별 훈련에 기반한다. 불필요한 은닉 유닛은 별도의 검증 세트를 사용하여 가지치기된다. 노드의 활성화 함수가 콜모고로프-가보르 다항식이므로, 이것은 곱셈 유닛 또는 "게이트"를 가진 최초의 심층 네트워크이기도 했다.[^32]
확률적 경사 하강법[^30]으로 훈련된 최초의 심층 학습 다층 퍼셉트론은 1967년에 아마리 슌이치에 의해 발표되었다.[^31] 아마리의 학생 사이토가 수행한 컴퓨터 실험에서, 두 개의 수정 가능한 층을 가진 5층 MLP는 비선형 분리 가능한 패턴 클래스를 분류하기 위한 내부 표현을 학습했다.[^32] 이후의 하드웨어 발전과 하이퍼파라미터 조정은 종단간 확률적 경사 하강법을 현재 지배적인 훈련 기법으로 만들었다.
1969년에 후쿠시마 구니히코는 ReLU(정류 선형 유닛) 활성화 함수를 도입했다.[^16][^32] 정류기는 심층 학습에서 가장 인기 있는 활성화 함수가 되었다.[^171]
합성곱 층과 다운샘플링 층을 가진 합성곱 신경망(CNN)을 위한 심층 학습 구조는 1979년에 후쿠시마 구니히코가 도입한 네오코그니트론에서 시작되었으나, 역전파로 훈련되지는 않았다.[^33][^34]
역전파는 1673년에 고트프리트 빌헬름 라이프니츠가 유도한 연쇄 법칙을[^35] 미분 가능한 노드의 네트워크에 효율적으로 적용한 것이다. "오류 역전파"라는 용어는 실제로 1962년에 로젠블랫이 도입했지만,[^26] 그는 이를 구현하는 방법을 알지 못했다. 다만 헨리 J. 켈리는 1960년에 제어 이론의 맥락에서 역전파의 연속적인 선행 형태를 제시한 바 있다.[^36] 역전파의 현대적 형태는 셉포 린나인마의 석사 논문(1970)에서 처음 발표되었다.[^37][^38][^32] G.M. 오스트로프스키 등은 1971년에 이를 재발표했다.[^39][^42] 폴 워보스는 1982년에 역전파를 신경망에 적용했다[^40](1994년 책에 재수록된 그의 1974년 박사 논문에는[^41] 아직 이 알고리즘이 기술되어 있지 않았다[^42]). 1986년에 데이비드 E. 루멜하트 등은 역전파를 대중화했지만 원래의 연구를 인용하지 않았다.^172
1980년대-2000년대
시간 지연 신경망(TDNN)은 1987년에 알렉스 와이벨이 CNN을 음소 인식에 적용하기 위해 도입했다. 이는 합성곱, 가중치 공유, 역전파를 사용했다.[^44][^45] 1988년에 웨이 장은 역전파로 훈련된 CNN을 알파벳 인식에 적용했다.[^46] 1989년에 얀 르쿤 등은 우편물의 손으로 쓴 우편번호를 인식하기 위한 LeNet이라는 CNN을 만들었다. 훈련에는 3일이 소요되었다.[^47] 1990년에 웨이 장은 광학 컴퓨팅 하드웨어에 CNN을 구현했다.[^48] 1991년에 CNN은 의료 영상 객체 분할[^173]과 유방촬영술에서의 유방암 검출에 적용되었다.[^174] LeNet-5(1998)는 얀 르쿤 등이 만든 7단계 CNN으로, 숫자를 분류하며 여러 은행에서 32x32 픽셀 이미지로 디지털화된 수표의 손으로 쓴 숫자를 인식하는 데 적용되었다.[^49]
순환 신경망(RNN)[^19][^21]은 1980년대에 더욱 발전했다. 순환은 시퀀스 처리에 사용되며, 순환 네트워크가 전개되면 수학적으로 심층 순방향 층과 유사하다. 따라서 유사한 특성과 문제를 가지며, 그 발전은 상호 영향을 주었다. RNN에서 두 가지 초기 영향력 있는 연구는 조던 네트워크(1986)[^175]와 엘만 네트워크(1990)로,[^176] 인지 심리학의 문제를 연구하기 위해 RNN을 적용했다.
1980년대에 역전파는 긴 공로 할당 경로를 가진 심층 학습에 잘 작동하지 않았다. 이 문제를 극복하기 위해 1991년에 위르겐 슈미트후버는 자기 지도 학습을 통해 한 단계씩 사전 훈련되는 RNN의 계층 구조를 제안했는데, 여기서 각 RNN은 자신의 다음 입력(즉, 아래 RNN의 다음 예상치 못한 입력)을 예측하려고 한다.[^50][^51] 이 "신경 이력 압축기"는 예측 코딩을 사용하여 여러 자기 조직화 시간 척도에서 내부 표현을 학습한다. 이는 하류의 심층 학습을 상당히 촉진할 수 있다. RNN 계층 구조는 상위 수준의 청커 네트워크를 하위 수준의 자동화기 네트워크로 증류하여 단일 RNN으로 축소될 수 있다.[^50][^51][^52] ChatGPT의 "P"는 이러한 사전 훈련을 의미한다.
셉 호흐라이터의 졸업 논문(1991)^53은 신경 이력 압축기를 구현했으며,[^50] 기울기 소실 문제를 식별하고 분석했다.[^53][^54] 호흐라이터는 기울기 소실 문제를 해결하기 위한 순환 잔차 연결을 제안했다. 이는 1995년에 발표된 장단기 메모리(LSTM)로 이어졌다.[^177] LSTM은 수천 개의 이산 시간 단계 이전에 발생한 사건의 기억을 요구하는 긴 공로 할당 경로를 가진 "매우 깊은 학습" 과제를 학습할 수 있다.[^14] 그 당시의 LSTM은 아직 현대적인 구조가 아니었으며, 1999년에 도입된 "망각 게이트"가 필요했고,[^55] 이것이 표준 RNN 구조가 되었다.
1991년에 위르겐 슈미트후버는 또한 제로섬 게임의 형태로 서로 경쟁하는 적대적 신경망을 발표했는데, 한 네트워크의 이득은 다른 네트워크의 손실이 된다.[^56][^57] 첫 번째 네트워크는 출력 패턴에 대한 확률 분포를 모델링하는 생성 모델이다. 두 번째 네트워크는 경사 하강법으로 이러한 패턴에 대한 환경의 반응을 예측하는 법을 학습한다. 이것은 "인공 호기심"이라 불렸다. 2014년에 이 원리는 생성적 적대 신경망(GAN)에 사용되었다.[^58]
1985년에서 1995년 사이에 통계 역학에서 영감을 받아 테리 세즈노프스키, 피터 데이언, 제프리 힌턴 등이 볼츠만 머신,[^178] 제한 볼츠만 머신,[^179] 헬름홀츠 머신,[^59] 그리고 깨우기-수면 알고리즘[^60]을 포함한 여러 구조와 방법을 개발했다. 이들은 심층 생성 모델의 비지도 학습을 위해 설계되었다. 그러나 이들은 역전파에 비해 계산 비용이 더 많이 들었다. 1985년에 발표된 볼츠만 머신 학습 알고리즘은 1986년에 역전파 알고리즘에 가려지기 전까지 잠시 인기를 얻었다. (p. 112 [^180]). 1988년의 네트워크는 단백질 구조 예측에서 최고 수준을 달성했으며, 이는 생물정보학에 대한 심층 학습의 초기 응용이었다.[^181]
음성 인식을 위한 ANN의 얕은 학습과 심층 학습(예: 순환 네트워크) 모두 오랫동안 연구되어 왔다.[^182][^61][^183] 이러한 방법들은 판별적으로 훈련된 음성의 생성 모델에 기반한 비균일 내부 수작업 가우시안 혼합 모델/은닉 마르코프 모델(GMM-HMM) 기술을 능가하지 못했다.[^62] 기울기 감소^53와 신경 예측 모델에서의 약한 시간적 상관 구조[^63][^64]를 포함한 주요 어려움이 분석되었다. 추가적인 어려움은 훈련 데이터의 부족과 제한된 컴퓨팅 파워였다.
대부분의 음성 인식 연구자들은 신경망에서 벗어나 생성 모델링을 추구했다. 예외는 1990년대 후반의 SRI International이었다. 미국 정부의 NSA와 DARPA의 자금 지원을 받아, SRI는 음성 및 화자 인식을 연구했다. 래리 헥이 이끄는 화자 인식 팀은 1998년 NIST 화자 인식 벤치마크에서 음성 처리에 심층 신경망을 적용하여 상당한 성공을 보고했다.[^65][^66] 이는 Nuance Verifier에 배포되어 심층 학습의 최초의 주요 산업 응용을 나타냈다.[^184]
수작업 최적화 대신 "원시" 특징을 향상시키는 원리는 1990년대 후반에 "원시" 스펙트로그램 또는 선형 필터 뱅크 특징에 대한 심층 오토인코더의 구조에서 처음으로 성공적으로 탐구되었으며,[^66] 이는 스펙트로그램에서 고정된 변환 단계를 포함하는 멜-켑스트럴 특징에 대한 우월성을 보여주었다. 음성의 원시 특징인 파형은 이후 우수한 대규모 결과를 산출했다.[^185]
2000년대
신경망은 침체기에 접어들었고, 가보르 필터와 서포트 벡터 머신(SVM) 같은 과제별 수작업 특징을 사용하는 더 단순한 모델이 1990년대와 2000년대에 선호되는 선택이 되었는데, 이는 인공 신경망의 계산 비용과 뇌가 생물학적 네트워크를 어떻게 연결하는지에 대한 이해 부족 때문이었다.
2003년에 LSTM은 특정 과제에서 전통적인 음성 인식기와 경쟁력을 갖추게 되었다.[^67] 2006년에 알렉스 그레이브스, 산티아고 페르난데스, 파우스티노 고메즈, 그리고 슈미트후버는 이를 LSTM 스택에서 연결주의 시간 분류(CTC)[^68]와 결합했다.^69 2009년에 이는 연결 필기 인식에서 패턴 인식 대회를 우승한 최초의 RNN이 되었다.[^186][^14]
2006년에 제프 힌턴, 루슬란 살라흐디노프, 오신데로와 테에 의한 발표[^187][^70]에서 심층 신뢰 네트워크가 생성 모델링을 위해 개발되었다. 이들은 하나의 제한 볼츠만 머신을 훈련하고, 이를 동결한 다음 그 위에 또 다른 것을 훈련하는 방식으로 훈련되며, 선택적으로 지도 역전파를 사용하여 미세 조정된다.^71 이들은 MNIST 이미지의 분포와 같은 고차원 확률 분포를 모델링할 수 있었지만, 수렴이 느렸다.[^188][^189][^190]
산업에서의 심층 학습의 영향은 2000년대 초에 시작되었는데, 얀 르쿤에 따르면 CNN이 이미 미국에서 작성된 모든 수표의 약 10%에서 20%를 처리하고 있었다.^72 대규모 음성 인식에 대한 심층 학습의 산업적 응용은 2010년경에 시작되었다.
2009년 음성 인식을 위한 심층 학습에 관한 NIPS 워크숍은 음성의 심층 생성 모델의 한계와, 더 강력한 하드웨어와 대규모 데이터셋이 주어진다면 심층 신경망이 실용적이 될 수 있다는 가능성에 의해 동기 부여되었다. 심층 신뢰 네트워크(DBN)의 생성 모델을 사용한 DNN 사전 훈련이 신경망의 주요 어려움을 극복할 것으로 믿어졌다. 그러나 크고 맥락 의존적인 출력 층을 가진 DNN을 사용할 때 사전 훈련을 대량의 훈련 데이터를 이용한 직접적인 역전파로 대체하면 당시 최첨단이었던 가우시안 혼합 모델(GMM)/은닉 마르코프 모델(HMM)보다, 그리고 더 진보된 생성 모델 기반 시스템보다 극적으로 낮은 오류율을 생성한다는 것이 발견되었다.[^73] 두 유형의 시스템이 생성하는 인식 오류의 특성은 특징적으로 달랐으며,[^75] 이는 심층 학습을 모든 주요 음성 인식 시스템이 배포하는 기존의 매우 효율적인 런타임 음성 디코딩 시스템에 통합하는 방법에 대한 기술적 통찰을 제공했다.[^13][^74][^191] 2009년에서 2010년경의 GMM(및 기타 생성적 음성 모델) 대 DNN 모델 비교 분석은 음성 인식을 위한 심층 학습에 대한 초기 산업 투자를 자극했다.[^75] 그 분석은 판별적 DNN과 생성 모델 사이의 비슷한 성능(오류율 1.5% 미만)으로 수행되었다.[^73][^75][^76] 2010년에 연구자들은 결정 트리로 구성된 맥락 의존적 HMM 상태에 기반한 DNN의 대규모 출력 층을 채택하여 심층 학습을 TIMIT에서 대규모 어휘 음성 인식으로 확장했다.[^77][^192][^193][^74]
심층 학습 혁명

심층 학습 혁명은 CNN 및 GPU 기반 컴퓨터 비전을 중심으로 시작되었다.
역전파로 훈련된 CNN은 수십 년간 존재해왔고 NN의 GPU 구현도 수년간 있었지만,[^78] CNN을 포함하여,[^79] 컴퓨터 비전의 진전을 위해서는 GPU에서의 더 빠른 CNN 구현이 필요했다. 이후 심층 학습이 널리 퍼짐에 따라 심층 학습을 위한 전문 하드웨어와 알고리즘 최적화가 개발되었다.[^80]
심층 학습 혁명의 핵심 진전은 하드웨어의 발전, 특히 GPU였다. 일부 초기 연구는 2004년으로 거슬러 올라간다.[^78][^79] 2009년에 라이나, 마다반, 그리고 앤드류 응은 30개의 Nvidia GeForce GTX 280 GPU에서 훈련된 1억 개의 심층 신뢰 네트워크를 보고했으며, 이는 GPU 기반 심층 학습의 초기 시연이었다. 그들은 최대 70배 더 빠른 훈련을 보고했다.[^194]
2011년에 댄 치레산, 우엘리 마이어, 조나단 마시, 루카 마리아 감바르델라, 그리고 위르겐 슈미트후버가 만든 DanNet[^81][^82]이라는 CNN이 시각 패턴 인식 대회에서 처음으로 초인간적 성능을 달성하여 전통적인 방법을 3배 차이로 능가했다.[^14] 이후 더 많은 대회에서 우승했다.[^83][^84] 그들은 또한 GPU에서의 최대 풀링 CNN이 성능을 크게 향상시키는 방법을 보여주었다.[^2]
2012년에 앤드류 응과 제프 딘은 YouTube 비디오에서 가져온 레이블이 없는 이미지를 보는 것만으로 고양이와 같은 고수준 개념을 인식하는 법을 학습한 FNN을 만들었다.[^85]
2012년 10월에 알렉스 크리제프스키, 일리야 수츠케버, 제프리 힌턴의 AlexNet[^3]이 얕은 기계 학습 방법에 비해 상당한 차이로 대규모 ImageNet 대회에서 우승했다. 추가적인 점진적 개선에는 카렌 시모니안과 앤드류 지서만의 VGG-16 네트워크[^86]와 구글의 Inceptionv3가 포함된다.[^87]
이미지 분류에서의 성공은 이후 이미지에 대한 설명(캡션)을 생성하는 더 어려운 과제로 확장되었으며, 종종 CNN과 LSTM의 조합으로 이루어졌다.[^88][^89][^90]
2014년에 최첨단 기술은 20개에서 30개 층의 "매우 깊은 신경망"을 훈련하는 것이었다.[^195] 너무 많은 층을 쌓으면 훈련 정확도가 급격히 감소하는데,[^91] 이를 "열화" 문제라 한다.[^92] 2015년에 매우 깊은 네트워크를 훈련하기 위한 두 가지 기법이 개발되었다: 고속도로 네트워크가 2015년 5월에 발표되었고, 잔차 신경망(ResNet)[^93]이 2015년 12월에 발표되었다. ResNet은 열린 게이트의 고속도로 네트워크처럼 동작한다.
비슷한 시기에 심층 학습은 예술 분야에도 영향을 미치기 시작했다. 초기 사례로는 구글 딥드림(2015)과 신경 스타일 전이(2015)가 있으며,[^196] 이 둘 모두 VGG-19와 같은 사전 훈련된 이미지 분류 신경망에 기반했다.
생성적 적대 신경망(GAN)(이안 굿펠로우 등, 2014)[^94](위르겐 슈미트후버의 인공 호기심 원리에 기반[^56][^58])은 2014년에서 2018년 기간 동안 생성 모델링에서 최첨단이 되었다. Nvidia의 StyleGAN(2018)[^95]은 테로 카라스 등의 프로그레시브 GAN에 기반하여[^96] 우수한 이미지 품질을 달성했다. 여기서 GAN 생성기는 피라미드 방식으로 소규모에서 대규모로 성장한다. GAN에 의한 이미지 생성은 대중적 성공을 거두었으며, 딥페이크에 관한 논의를 촉발했다.[^197] 확산 모델(2015)[^198]은 이후 DALL·E 2(2022)와 스테이블 디퓨전(2022) 같은 시스템으로 생성 모델링에서 GAN을 능가했다.
2015년에 구글의 음성 인식은 LSTM 기반 모델에 의해 49% 향상되었으며, 이를 스마트폰의 구글 음성 검색을 통해 이용 가능하게 했다.[^97][^98]
심층 학습은 다양한 분야, 특히 컴퓨터 비전과 자동 음성 인식(ASR)에서 최첨단 시스템의 일부이다. TIMIT(ASR)과 MNIST(이미지 분류) 같은 일반적으로 사용되는 평가 세트와 다양한 대규모 어휘 음성 인식 과제에 대한 결과가 꾸준히 향상되어 왔다.[^73][^199] 합성곱 신경망은 ASR에서 LSTM에 의해 대체되었지만,[^98][^99][^100][^101] 컴퓨터 비전에서는 더 성공적이다.
요슈아 벤지오, 제프리 힌턴, 얀 르쿤은 "심층 신경망을 컴퓨팅의 핵심 구성 요소로 만든 개념적 및 공학적 돌파구"로 2018년 튜링상을 수상했다.[^200]
신경망
인공 신경망(ANN)은 또는 연결주의 시스템은 동물의 뇌를 구성하는 생물학적 신경망에서 영감을 받은 컴퓨팅 시스템이다. 이러한 시스템은 일반적으로 특정 작업에 맞춘 프로그래밍 없이 예제를 고려하여 작업 수행 능력을 점진적으로 향상시키며 학습한다. 예를 들어, 이미지 인식에서 "고양이" 또는 "고양이 아님"으로 수동 라벨링된 예제 이미지를 분석하여 고양이가 포함된 이미지를 식별하는 방법을 학습하고, 그 분석 결과를 활용하여 다른 이미지에서 고양이를 식별할 수 있다. 인공 신경망은 규칙 기반 프로그래밍을 사용하는 전통적인 컴퓨터 알고리즘으로 표현하기 어려운 응용 분야에서 가장 많이 활용되고 있다.
인공 신경망은 인공 뉴런이라 불리는 연결된 단위들의 집합에 기반한다(생물학적 뇌의 생물학적 뉴런에 유사함). 뉴런 간의 각 연결(시냅스)은 다른 뉴런에 신호를 전달할 수 있다. 수신(시냅스 후) 뉴런은 신호를 처리한 후 연결된 하류 뉴런에 신호를 보낼 수 있다. 뉴런은 일반적으로 0과 1 사이의 실수로 표현되는 상태를 가질 수 있다. 뉴런과 시냅스는 또한 학습이 진행됨에 따라 변화하는 가중치를 가질 수 있으며, 이는 하류로 전송하는 신호의 강도를 증가시키거나 감소시킬 수 있다.
일반적으로 뉴런은 층(레이어)으로 구성된다. 서로 다른 층은 입력에 대해 서로 다른 종류의 변환을 수행할 수 있다. 신호는 첫 번째(입력) 층에서 마지막(출력) 층으로 이동하며, 경우에 따라 여러 층을 여러 번 거친 후 전달된다.
신경망 접근 방식의 원래 목표는 인간의 뇌와 같은 방식으로 문제를 해결하는 것이었다. 시간이 지남에 따라 특정 정신 능력을 모방하는 데 초점이 맞춰지면서, 역전파(정보를 역방향으로 전달하고 해당 정보를 반영하도록 네트워크를 조정하는 것)와 같이 생물학에서 벗어난 방식이 등장하였다.
신경망은 컴퓨터 비전, 음성 인식, 기계 번역, 소셜 네트워크 필터링, 보드 및 비디오 게임 플레이, 의료 진단 등 다양한 작업에 활용되어 왔다.
2017년 기준으로 신경망은 일반적으로 수천에서 수백만 개의 유닛과 수백만 개의 연결을 가지고 있다. 이 수치가 인간 뇌의 뉴런 수보다 수 자릿수 적음에도 불구하고, 이러한 네트워크는 많은 작업에서 인간을 능가하는 수준으로 수행할 수 있다(예: 얼굴 인식 또는 "바둑" 플레이[^202]).
심층 신경망
심층 신경망(DNN)은 입력 층과 출력 층 사이에 여러 개의 층을 가진 인공 신경망이다.[^4][^14] 신경망에는 다양한 유형이 있지만, 항상 동일한 구성 요소로 이루어진다: 뉴런, 시냅스, 가중치, 편향, 그리고 함수이다.[^102] 이러한 구성 요소들은 전체적으로 인간 뇌의 기능을 모방하는 방식으로 작동하며, 다른 머신러닝 알고리즘처럼 훈련될 수 있다.
예를 들어, 개 품종을 인식하도록 훈련된 DNN은 주어진 이미지를 검토하고 이미지 속 개가 특정 품종일 확률을 계산한다. 사용자는 결과를 검토하여 네트워크가 표시할 확률(특정 임계값 이상 등)을 선택하고 제안된 라벨을 반환받을 수 있다. 이러한 각각의 수학적 조작은 하나의 층으로 간주되며,[^103] 복잡한 DNN은 많은 층을 가지고 있어 "심층" 네트워크라는 이름이 붙었다.
DNN은 복잡한 비선형 관계를 모델링할 수 있다. DNN 아키텍처는 객체가 기본 요소의 계층적 합성으로 표현되는 합성 모델을 생성한다.[^203] 추가 층은 하위 층의 특징 합성을 가능하게 하여, 유사한 성능을 가진 얕은 네트워크보다 적은 유닛으로 복잡한 데이터를 모델링할 수 있게 한다.[^4] 예를 들어, 희소 다변량 다항식은 얕은 네트워크보다 DNN으로 근사하는 것이 기하급수적으로 더 쉽다는 것이 증명되었다.[^104]
심층 아키텍처에는 몇 가지 기본 접근 방식의 다양한 변형이 포함된다. 각 아키텍처는 특정 도메인에서 성공을 거두었다. 동일한 데이터 세트에서 평가되지 않은 한 여러 아키텍처의 성능을 비교하는 것이 항상 가능한 것은 아니다.[^103]
DNN은 일반적으로 데이터가 입력 층에서 출력 층으로 흐르며 되돌아가지 않는 순방향 네트워크이다. 먼저 DNN은 가상 뉴런의 맵을 생성하고 뉴런 간의 연결에 임의의 수치 값, 즉 "가중치"를 할당한다. 가중치와 입력이 곱해져 0과 1 사이의 출력을 반환한다. 네트워크가 특정 패턴을 정확하게 인식하지 못하면 알고리즘이 가중치를 조정한다.[^204] 이러한 방식으로 알고리즘은 데이터를 완전히 처리할 수 있는 올바른 수학적 조작을 결정할 때까지 특정 매개변수의 영향력을 높일 수 있다.
데이터가 어떤 방향으로든 흐를 수 있는 순환 신경망은 언어 모델링과 같은 응용 분야에 사용된다.[^105][^134][^106][^107][^108] 장단기 기억(LSTM)은 이러한 용도에 특히 효과적이다.[^109][^110]
합성곱 신경망(CNN)은 컴퓨터 비전에 사용된다.[^111] CNN은 또한 자동 음성 인식(ASR)을 위한 음향 모델링에도 적용되어 왔다.[^112]
과제
인공 신경망과 마찬가지로, 단순하게 훈련된 DNN에서도 많은 문제가 발생할 수 있다. 두 가지 일반적인 문제는 과적합과 계산 시간이다.
DNN은 추가된 추상화 층으로 인해 과적합에 취약하며, 이러한 층은 훈련 데이터에서 희귀한 의존성을 모델링할 수 있게 한다. 이바흐넨코의 유닛 가지치기[^29]나 가중치 감쇠( \ell_2 -정규화) 또는 희소성( \ell_1 -정규화)과 같은 정규화 방법을 훈련 중에 적용하여 과적합에 대응할 수 있다.[^205] 대안으로, 드롭아웃 정규화는 훈련 중에 은닉 층의 유닛을 무작위로 제거한다. 이는 희귀한 의존성을 배제하는 데 도움이 된다.[^113] 또 다른 흥미로운 최근 개발은 모델링되는 작업의 내재적 복잡성 추정을 통해 적절한 수준의 복잡성을 가진 모델에 대한 연구이다. 이 접근 방식은 교통 예측과 같은 다변량 시계열 예측 작업에 성공적으로 적용되었다.[^114] 마지막으로, 자르기 및 회전과 같은 방법을 통해 데이터를 증강하여 작은 훈련 세트의 크기를 늘림으로써 과적합의 가능성을 줄일 수 있다.[^206]
DNN은 크기(층의 수와 층당 유닛 수), 학습률, 초기 가중치 등 많은 훈련 매개변수를 고려해야 한다. 최적의 매개변수를 찾기 위해 매개변수 공간을 탐색하는 것은 시간과 계산 자원의 비용으로 인해 실현 가능하지 않을 수 있다. 배치 처리(개별 예제가 아닌 여러 훈련 예제에 대해 한꺼번에 기울기를 계산하는 것)[^115]와 같은 다양한 기법이 계산을 가속화한다. 다중 코어 아키텍처(GPU 또는 Intel Xeon Phi 등)의 강력한 처리 능력은 이러한 처리 아키텍처가 행렬 및 벡터 연산에 적합하기 때문에 훈련에서 상당한 속도 향상을 가져왔다.[^207][^208]
대안으로, 엔지니어들은 더 단순하고 수렴이 보장되는 훈련 알고리즘을 가진 다른 유형의 신경망을 탐색할 수 있다. CMAC(소뇌 모델 관절 제어기)는 그러한 종류의 신경망 중 하나이다. 학습률이나 무작위 초기 가중치가 필요하지 않다. 훈련 과정은 새로운 데이터 배치로 한 단계 만에 수렴이 보장되며, 훈련 알고리즘의 계산 복잡도는 관련된 뉴런 수에 대해 선형이다.^116
하드웨어
2010년대 이후, 기계 학습 알고리즘과 컴퓨터 하드웨어 양쪽의 발전으로 많은 비선형 은닉층과 매우 큰 출력층을 포함하는 심층 신경망을 훈련하는 더 효율적인 방법이 등장했다.[^209] 2019년까지 AI 전용 기능이 추가된 그래픽 처리 장치(GPU)가 대규모 상업용 클라우드 AI 훈련의 주요 방식으로서 CPU를 대체했다.[^210] OpenAI는 알렉스넷(AlexNet, 2012)에서 알파제로(AlphaZero, 2017)까지 가장 대규모 딥러닝 프로젝트에 사용된 하드웨어 연산량을 추정한 결과, 필요한 연산량이 300,000배 증가했으며, 배증 시간 추세선은 3.4개월이었다.[^211][^212]
딥러닝 알고리즘의 속도를 높이기 위해 딥러닝 프로세서라 불리는 특수 전자 회로가 설계되었다. 딥러닝 프로세서에는 화웨이 휴대전화의 신경 처리 장치(NPU)[^213]와 구글 클라우드 플랫폼의 텐서 처리 장치(TPU) 같은 클라우드 컴퓨팅 서버가 포함된다.[^214] 세레브라스 시스템즈(Cerebras Systems)는 업계 최대 규모의 프로세서인 2세대 웨이퍼 스케일 엔진(WSE-2)을 기반으로 대규모 딥러닝 모델을 처리하기 위한 전용 시스템 CS-2를 구축하기도 했다.[^215][^216]
원자 수준 두께의 반도체는 동일한 기본 소자 구조를 논리 연산과 데이터 저장 모두에 사용하는 에너지 효율적인 딥러닝 하드웨어로서 유망하게 여겨지고 있다. 2020년, 마레가(Marega) 등은 부유 게이트 전계 효과 트랜지스터(FGFET) 기반의 로직 인 메모리 소자 및 회로 개발을 위한 대면적 활성 채널 재료 실험 결과를 발표했다.[^118]
2021년, J. 펠트만(J. Feldmann) 등은 병렬 합성곱 처리를 위한 집적 광학 하드웨어 가속기를 제안했다.[^119] 저자들은 전자 방식 대비 집적 광학의 두 가지 핵심 이점을 제시했다: (1) 주파수 빗과 결합된 파장 분할 다중화를 통한 대규모 병렬 데이터 전송, (2) 극도로 높은 데이터 변조 속도.[^119] 이들의 시스템은 초당 수조 건의 곱셈-누산 연산을 수행할 수 있으며, 이는 데이터 집약적 AI 응용 분야에서 집적 광학의 잠재력을 보여준다.[^119]
응용 분야
자동 음성 인식
대규모 자동 음성 인식은 딥러닝의 첫 번째이자 가장 설득력 있는 성공 사례이다. LSTM RNN은 약 10ms에 해당하는 하나의 시간 단계로 구분되는 수천 개의 이산 시간 단계에 걸쳐 음성 이벤트가 포함된 수 초 간격의 "매우 깊은 학습" 과제를 학습할 수 있다.[^14] 망각 게이트가 있는 LSTM[^110]은 특정 과제에서 전통적인 음성 인식기와 대등한 성능을 보인다.[^67]
음성 인식의 초기 성공은 TIMIT 기반의 소규모 인식 과제에 기반하였다. 이 데이터 세트에는 미국 영어의 8개 주요 방언을 사용하는 630명의 화자가 포함되어 있으며, 각 화자가 10개의 문장을 읽는다.[^120] 소규모이기 때문에 다양한 구성을 시도할 수 있다. 더 중요한 것은 TIMIT 과제가 음소 시퀀스 인식에 관한 것으로, 단어 시퀀스 인식과 달리 약한 음소 바이그램 언어 모델을 사용할 수 있다는 점이다. 이를 통해 음성 인식의 음향 모델링 측면의 강점을 더 쉽게 분석할 수 있다. 아래에 나열된 오류율은 1991년 이후 요약된 것으로, 이러한 초기 결과를 포함하며 음소 오류율(PER) 백분율로 측정되었다.
{| class="wikitable" |- ! 방법 !! 음소 오류율 (PER) (%) |- | 무작위 초기화 RNN[^217]|| 26.1 |- | 베이지안 트라이폰 GMM-HMM || 25.6 |- | 은닉 궤적 (생성) 모델|| 24.8 |- | 모노폰 무작위 초기화 DNN|| 23.4 |- | 모노폰 DBN-DNN|| 22.4 |- | BMMI 훈련을 적용한 트라이폰 GMM-HMM|| 21.7 |- | fbank 기반 모노폰 DBN-DNN || 20.7 |- | 합성곱 DNN[^121]|| 20.0 |- | 이종 풀링을 적용한 합성곱 DNN|| 18.7 |- | 앙상블 DNN/CNN/RNN[^122]|| 18.3 |- | 양방향 LSTM|| 17.8 |- | 계층적 합성곱 딥 맥스아웃 네트워크[^123] || 16.5 |}
1990년대 후반 화자 인식, 2009-2011년경 음성 인식에 DNN이 도입되고, 2003-2007년경 LSTM이 등장하면서 8개 주요 분야에서 발전이 가속화되었다:[^13][^76][^74]
- DNN 훈련 및 디코딩의 규모 확대/확장 및 가속화
- 시퀀스 판별 훈련
- 기저 메커니즘에 대한 확실한 이해를 바탕으로 한 심층 모델의 특징 처리
- DNN 및 관련 심층 모델의 적응
- DNN 및 관련 심층 모델에 의한 다중 과제 및 전이 학습
- CNN 및 음성의 도메인 지식을 최대한 활용하기 위한 설계 방법
- RNN 및 그 다양한 LSTM 변형
- 텐서 기반 모델 및 통합 심층 생성/판별 모델을 포함한 기타 유형의 심층 모델
최근의 음성 인식 모델은 트랜스포머 또는 시간적 합성곱 네트워크를 사용하여 상당한 성공과 광범위한 응용을 달성하고 있다.[^218][^219][^220] 모든 주요 상용 음성 인식 시스템(예: Microsoft Cortana, Xbox, Skype Translator, Amazon Alexa, Google Now, Apple Siri, Baidu 및 iFlyTek 음성 검색, 그리고 다양한 Nuance 음성 제품 등)은 딥러닝을 기반으로 한다.[^13][^221][^124]
이미지 인식
홍합 양식에서의 활용.]]
이미지 분류의 일반적인 평가 세트는 MNIST 데이터베이스 데이터 세트이다. MNIST는 손으로 쓴 숫자로 구성되어 있으며 60,000개의 훈련 예제와 10,000개의 테스트 예제를 포함한다. TIMIT와 마찬가지로 소규모이기 때문에 사용자가 다양한 구성을 테스트할 수 있다. 이 데이터 세트에 대한 포괄적인 결과 목록이 제공되고 있다.[^125]
딥러닝 기반 이미지 인식은 인간 참가자보다 더 정확한 결과를 산출하며 "초인적" 수준에 도달했다. 이는 2011년 교통 표지판 인식에서 처음 발생했으며, 2014년에는 인간 얼굴 인식에서도 달성되었다.[^126][^127]
딥러닝으로 훈련된 차량은 이제 360° 카메라 영상을 해석한다.[^222] 또 다른 예로는 대규모 유전 증후군 데이터베이스와 연결된 인간 기형 사례를 분석하는 데 사용되는 안면 이형태학 신규 분석(FDNA)이 있다.
시각 예술 처리
![Visual art processing of Jimmy Wales in France, with the style of Munch's "[The Scream " 신경 스타일 전이를 적용]] 이미지 인식에서 이루어진 발전과 밀접하게 관련된 것은 다양한 시각 예술 과제에 딥러닝 기술이 점점 더 많이 적용되고 있다는 점이다. DNN은 예를 들어 다음과 같은 능력을 입증하였다: *주어진 그림의 양식 시대를 식별하는 것[^128][^129]
{kind=link}
자연어 처리
신경망은 2000년대 초반부터 언어 모델을 구현하는 데 사용되어 왔다.[^105] LSTM은 기계 번역과 언어 모델링을 개선하는 데 기여하였다.[^134][^106][^107]
이 분야의 다른 핵심 기술로는 네거티브 샘플링[^130]과 단어 임베딩이 있다. word2vec과 같은 단어 임베딩은 원자적 단어를 데이터 세트 내 다른 단어들과의 상대적 위치 표현으로 변환하는 딥러닝 아키텍처의 표현 계층으로 생각할 수 있으며, 이 위치는 벡터 공간의 한 점으로 표현된다. 단어 임베딩을 RNN 입력 계층으로 사용하면 네트워크가 효과적인 합성 벡터 문법을 사용하여 문장과 구를 구문 분석할 수 있다. 합성 벡터 문법은 RNN으로 구현된 확률적 문맥 자유 문법(PCFG)으로 생각할 수 있다.[^131] 단어 임베딩 위에 구축된 재귀적 오토인코더는 문장 유사성을 평가하고 의역을 감지할 수 있다.[^131] 심층 신경 아키텍처는 구성 구문 분석,[^223] 감성 분석,[^132] 정보 검색,[^224][^225] 음성 언어 이해,[^133] 기계 번역,[^134][^135] 문맥적 개체 연결,[^135] 문체 인식,[^136] 개체명 인식(토큰 분류),[^226] 텍스트 분류[^227] 등에서 최고의 결과를 제공한다.
최근의 발전은 단어 임베딩을 문장 임베딩으로 일반화하고 있다.
Google 번역(GT)은 대규모 종단 간 장단기 기억(LSTM) 네트워크를 사용한다.[^137][^138][^139][^140] Google 신경 기계 번역(GNMT)은 시스템이 "수백만 개의 예제에서 학습하는" 예제 기반 기계 번역 방법을 사용한다.[^138] 이는 "조각이 아닌 전체 문장을 한 번에" 번역한다. Google 번역은 100개 이상의 언어를 지원한다.[^138] 이 네트워크는 "단순히 구문 대 구문 번역을 암기하는 것이 아니라 문장의 의미론을 인코딩한다".[^138][^141] GT는 대부분의 언어 쌍 사이에서 영어를 중간 언어로 사용한다.[^141]
신약 개발 및 독성학
후보 약물의 상당 비율이 규제 승인을 받지 못한다. 이러한 실패는 불충분한 효능(표적 효과), 원치 않는 상호작용(비표적 효과), 또는 예상치 못한 독성 효과로 인해 발생한다.[^142][^143] 연구에서는 딥러닝을 사용하여 영양소, 가정용 제품 및 약물에 포함된 환경 화학물질의 생체분자 표적,[^144][^145] 비표적, 독성 효과를 예측하는 방법이 탐구되었다.[^146][^147][^148]
AtomNet은 구조 기반 합리적 약물 설계를 위한 딥러닝 시스템이다.[^228] AtomNet은 에볼라 바이러스[^149] 및 다발성 경화증[^229][^149]과 같은 질병 표적에 대한 새로운 후보 생체분자를 예측하는 데 사용되었다.
2017년에는 그래프 신경망이 대규모 독성학 데이터 세트에서 분자의 다양한 특성을 예측하는 데 처음으로 사용되었다.[^230] 2019년에는 생성적 신경망이 실험적으로 검증된 분자를 생산하는 데 사용되었으며, 마우스 실험까지 완료되었다.[^231][^232]
추천 시스템
추천 시스템은 딥러닝을 사용하여 콘텐츠 기반 음악 및 학술지 추천을 위한 잠재 요인 모델의 의미 있는 특징을 추출하였다.[^233][^234] 다중 관점 딥러닝은 여러 도메인에서 사용자 선호도를 학습하는 데 적용되었다.[^235] 이 모델은 하이브리드 협업 필터링 및 콘텐츠 기반 접근 방식을 사용하며 여러 과제에서 추천을 향상시킨다.
생물정보학
오토인코더 ANN은 생물정보학에서 유전자 온톨로지 주석 및 유전자-기능 관계를 예측하는 데 사용되었다.[^236]
의료 정보학에서는 딥러닝이 웨어러블 기기의 데이터를 기반으로 수면 품질을 예측하고[^237] 전자 건강 기록 데이터에서 건강 합병증을 예측하는 데 사용되었다.[^238]
심층 신경망은 아미노산 서열에 기반한 단백질 구조 예측에서 비할 데 없는 성능을 보여주었다. 2020년에 딥러닝 기반 시스템인 AlphaFold는 이전의 모든 계산 방법보다 현저히 높은 정확도를 달성하였다.[^239][^240]
심층 신경망 추정
심층 신경망은 신경 결합 엔트로피 추정기(NJEE)라는 구조를 통해 확률 과정의 엔트로피를 추정하는 데 사용될 수 있다.[^150] 이러한 추정은 입력 확률 변수가 독립 확률 변수에 미치는 영향에 대한 통찰을 제공한다. 실제로 DNN은 입력 벡터 또는 행렬 X를 주어진 입력 X에 대한 확률 변수 Y의 가능한 클래스에 대한 출력 확률 분포로 매핑하는 분류기로 훈련된다. 예를 들어, 이미지 분류 과제에서 NJEE는 픽셀의 색상 값 벡터를 가능한 이미지 클래스에 대한 확률로 매핑한다. 실제로 Y의 확률 분포는 Y의 알파벳 크기와 같은 수의 노드를 가진 소프트맥스 계층에 의해 얻어진다. NJEE는 연속적으로 미분 가능한 활성화 함수를 사용하여 보편 근사 정리의 조건이 충족된다. 이 방법이 강한 일관성을 가진 추정량을 제공하며 큰 알파벳 크기의 경우 다른 방법보다 우수한 성능을 보이는 것이 입증되었다.[^150]
의료 영상 분석
딥러닝은 암세포 분류, 병변 감지, 장기 분할 및 영상 향상과 같은 의료 응용 분야에서 경쟁력 있는 결과를 산출하는 것으로 나타났다.[^241][^242] 현대 딥러닝 도구는 다양한 질병을 감지하는 높은 정확도와 전문가가 진단 효율성을 향상시키는 데 이를 활용하는 유용성을 보여준다.[^243][^244]
모바일 광고
모바일 광고에 적합한 모바일 대상 고객을 찾는 것은 항상 어려운 과제인데, 이는 광고 서버가 대상 세그먼트를 생성하고 광고 제공에 사용하기 전에 많은 데이터 포인트를 고려하고 분석해야 하기 때문이다.[^245] 딥러닝은 대규모 다차원 광고 데이터 세트를 해석하는 데 사용되어 왔다. 요청/제공/클릭의 인터넷 광고 주기에서 많은 데이터 포인트가 수집된다. 이 정보는 광고 선택을 개선하기 위한 기계 학습의 기초를 형성할 수 있다.
이미지 복원
딥러닝은 잡음 제거, 초해상도, 인페인팅 및 필름 컬러화와 같은 역문제에 성공적으로 적용되었다.[^246] 이러한 응용에는 이미지 데이터 세트에서 훈련하는 "효과적인 이미지 복원을 위한 축소 필드"[^247]와 복원이 필요한 이미지 자체에서 훈련하는 Deep Image Prior 등의 학습 방법이 포함된다.
금융 사기 탐지
딥러닝은 금융 사기 탐지, 탈세 감지,[^248] 자금세탁 방지에[^249] 성공적으로 적용되고 있다.
재료 과학
2023년 11월, Google DeepMind와 로렌스 버클리 국립 연구소의 연구자들은 GNoME로 알려진 AI 시스템을 개발했다고 발표하였다. 이 시스템은 비교적 짧은 기간 내에 200만 개 이상의 새로운 재료를 발견하여 재료 과학에 기여하였다. GNoME는 딥러닝 기술을 사용하여 잠재적 재료 구조를 효율적으로 탐색하며, 안정적인 무기 결정 구조의 식별에서 상당한 증가를 달성하였다. 이 시스템의 예측은 자율 로봇 실험을 통해 검증되었으며, 71%의 주목할 만한 성공률을 보여주었다. 새로 발견된 재료의 데이터는 Materials Project 데이터베이스를 통해 공개되어 있으며, 연구자들에게 다양한 응용을 위한 원하는 특성을 가진 재료를 식별할 기회를 제공한다. 이 발전은 과학적 발견의 미래와 재료 과학 연구에서의 AI 통합에 시사점을 가지며, 잠재적으로 재료 혁신을 가속화하고 제품 개발 비용을 절감할 수 있다. AI와 딥러닝의 사용은 수동 실험실 실험을 최소화하거나 없앨 수 있으며 과학자들이 독특한 화합물의 설계와 분석에 더 집중할 수 있게 하는 가능성을 시사한다.[^250][^251][^252]
군사
미국 국방부는 딥러닝을 적용하여 로봇이 관찰을 통해 새로운 과제를 학습하도록 훈련하였다.[^151]
편미분 방정식
물리 정보 신경망은 데이터 기반 방식으로 순방향 및 역방향 문제 모두에서 편미분 방정식을 푸는 데 사용되어 왔다.[^253] 한 예로 나비에-스토크스 방정식에 의해 지배되는 유체 흐름의 재구성이 있다. 물리 정보 신경망을 사용하면 기존 CFD 방법이 의존하는 비용이 많이 드는 메시 생성이 필요하지 않다.[^254][^255] 기하학적 및 물리적 제약 조건이 신경 PDE 대리 모델에 시너지 효과를 가져 안정적이고 초장기 롤아웃 예측의 효능을 향상시키는 것이 분명하다.[^256]
심층 후향 확률 미분 방정식 방법
심층 후향 확률 미분 방정식 방법은 딥러닝과 후향 확률 미분 방정식(BSDE)을 결합한 수치적 방법이다. 이 방법은 금융 수학의 고차원 문제를 푸는 데 특히 유용하다. 심층 신경망의 강력한 함수 근사 능력을 활용함으로써, 심층 BSDE는 고차원 환경에서 전통적인 수치적 방법이 직면하는 계산적 과제를 해결한다. 구체적으로, 유한 차분법이나 몬테카를로 시뮬레이션과 같은 전통적인 방법은 차원의 수가 증가함에 따라 계산 비용이 기하급수적으로 증가하는 차원의 저주 문제에 자주 직면한다. 그러나 심층 BSDE 방법은 심층 신경망을 사용하여 고차원 편미분 방정식(PDE)의 해를 근사함으로써 계산 부담을 효과적으로 줄인다.[^152]
또한, 심층 BSDE 프레임워크에 물리 정보 신경망(PINN)을 통합하면 기저 물리 법칙을 신경망 아키텍처에 직접 내장함으로써 그 능력이 향상된다. 이를 통해 해가 데이터에 적합할 뿐만 아니라 지배하는 확률 미분 방정식을 준수하도록 보장한다. PINN은 물리 모델이 부과하는 제약을 존중하면서 딥러닝의 힘을 활용하여 금융 수학 문제에 대해 더 정확하고 신뢰할 수 있는 해를 제공한다.
이미지 재구성
이미지 재구성은 이미지 관련 측정값으로부터 기저 이미지를 복원하는 것이다. 여러 연구에서 분광 영상[^257] 및 초음파 영상[^258] 등 다양한 응용 분야에서 분석적 방법 대비 딥러닝 방법의 우수한 성능이 입증되었다.
기상 예측
전통적인 기상 예측 시스템은 매우 복잡한 편미분 방정식 시스템을 풀어야 한다. GraphCast는 딥러닝 기반 모델로, 오랜 기상 데이터 기록을 바탕으로 훈련되어 기상 패턴이 시간에 따라 어떻게 변화하는지를 예측한다. 이 모델은 전 세계적으로 최대 10일간의 기상 조건을 매우 상세한 수준에서 1분 이내에 예측할 수 있으며, 최신 시스템과 유사한 정밀도를 보인다.[^259][^260]
후성유전학적 시계
후성유전학적 시계는 나이를 측정하는 데 사용할 수 있는 생화학적 검사이다. Galkin 등은 6,000개 이상의 혈액 샘플을 사용하여 전례 없는 정확도의 후성유전학적 노화 시계를 심층 신경망으로 훈련하였다.[^261] 이 시계는 1,000개의 CpG 부위의 정보를 사용하며, 염증성 장질환, 전두측두엽 치매, 난소암, 비만 등 특정 질환을 가진 사람들이 건강한 대조군보다 더 늙은 것으로 예측한다. 이 노화 시계는 Insilico Medicine의 분사 회사인 Deep Longevity에 의해 2021년에 공개 사용을 위해 출시될 예정이었다.
인간의 인지 및 뇌 발달과의 관계
딥러닝은 1990년대 초 인지신경과학자들이 제안한 뇌 발달(구체적으로는 신피질 발달) 이론의 한 부류와 밀접하게 관련되어 있다.[^153][^154][^155][^156] 이러한 발달 이론들은 계산 모델로 구현되어 딥러닝 시스템의 선구자가 되었다. 이 발달 모델들은 뇌에서 제안된 다양한 학습 역학(예: 신경 성장 인자의 파동)이 딥러닝 모델에서 활용되는 신경망과 다소 유사한 자기 조직화를 지원한다는 특성을 공유한다. 신피질과 마찬가지로, 신경망은 각 계층이 이전 계층(또는 운영 환경)의 정보를 고려한 후, 그 출력(및 경우에 따라 원래 입력)을 다른 계층으로 전달하는 계층화된 필터의 위계 구조를 사용한다. 이 과정은 운영 환경에 잘 맞춰진 자기 조직화된 변환기 스택을 생성한다. 1995년의 한 서술에 따르면, "...영아의 뇌는 소위 영양 인자라 불리는 파동의 영향 아래 스스로 조직화되는 것으로 보이며 ... 뇌의 서로 다른 영역이 순차적으로 연결되고, 한 조직층이 다른 층보다 먼저 성숙하는 식으로 전체 뇌가 성숙할 때까지 계속된다".[^157]
신경생물학적 관점에서 딥러닝 모델의 타당성을 조사하기 위해 다양한 접근법이 사용되어 왔다. 한편으로는, 처리의 현실성을 높이기 위해 역전파 알고리즘의 여러 변형이 제안되었다.[^262][^263] 다른 연구자들은 계층적 생성 모델과 심층 신뢰 네트워크에 기반한 것과 같은 비지도 형태의 딥러닝이 생물학적 현실에 더 가까울 수 있다고 주장했다.[^264][^265] 이와 관련하여, 생성적 신경망 모델은 대뇌 피질에서의 표본 기반 처리에 대한 신경생물학적 증거와 연결되었다.[^266]
인간 뇌의 조직과 심층 네트워크의 신경 부호화 사이의 체계적인 비교는 아직 확립되지 않았지만, 여러 유사점이 보고되었다. 예를 들어, 딥러닝 유닛이 수행하는 계산은 실제 뉴런[^267] 및 신경 집단[^268]의 계산과 유사할 수 있다. 마찬가지로, 딥러닝 모델이 발전시킨 표상은 영장류 시각 체계에서 측정된 것과 유사하며,[^269] 이는 단일 유닛[^270] 수준과 집단[^271] 수준 모두에서 그러하다.
상업적 활동
페이스북의 AI 연구소는 업로드된 사진에 해당 인물의 이름을 자동으로 태그하는 등의 작업을 수행한다.[^158]
구글의 딥마인드 테크놀로지스는 픽셀만을 데이터 입력으로 사용하여 아타리 비디오 게임을 플레이하는 방법을 학습할 수 있는 시스템을 개발했다. 2015년에 그들은 프로 바둑 기사를 이길 수 있을 만큼 바둑을 충분히 학습한 알파고 시스템을 시연했다.[^272][^273][^274] 구글 번역은 100개 이상의 언어 간 번역을 위해 신경망을 사용한다.
2017년에는 공장에 딥러닝을 통합하는 데 주력하는 Covariant.ai가 설립되었다.[^275]
2008년 기준으로,[^276] 텍사스 대학교 오스틴 캠퍼스(UT)의 연구자들은 평가적 강화를 통한 에이전트 수동 훈련(Training an Agent Manually via Evaluative Reinforcement), 즉 TAMER라 불리는 기계 학습 프레임워크를 개발했으며, 이는 로봇이나 컴퓨터 프로그램이 인간 교관과 상호작용하여 과제 수행 방법을 학습하는 새로운 방법을 제안했다.[^151] 처음에 TAMER로 개발된 후, 2018년 미 육군 연구소(ARL)와 UT 연구자들의 협력 과정에서 딥 TAMER라는 새로운 알고리즘이 도입되었다. 딥 TAMER는 딥러닝을 활용하여 로봇에게 관찰을 통해 새로운 과제를 학습하는 능력을 제공했다.[^151] 딥 TAMER를 사용하여, 로봇은 비디오 스트림을 시청하거나 인간이 직접 과제를 수행하는 것을 관찰하면서 인간 훈련사와 함께 과제를 학습했다. 이후 로봇은 "잘했어"와 "못했어" 같은 피드백을 제공하는 훈련사의 코칭을 받으며 과제를 연습했다.[^277]
비판과 논평
딥러닝은 비판과 논평을 모두 받아왔으며, 일부는 컴퓨터 과학 분야 외부에서 제기되었다.
이론
주요 비판은 일부 방법론을 둘러싼 이론의 부재에 관한 것이다.[^278] 가장 일반적인 심층 아키텍처에서의 학습은 잘 알려진 경사 하강법을 사용하여 구현된다. 그러나 대조적 발산과 같은 다른 알고리즘을 둘러싼 이론은 덜 명확하다. (예: 수렴하는가? 수렴한다면, 얼마나 빠른가? 무엇을 근사하는가?) 딥러닝 방법론은 흔히 블랙박스로 간주되며, 대부분의 검증이 이론적이기보다는 경험적으로 이루어진다.
예술적 감수성이 인지 계층의 비교적 낮은 수준에 내재할 수 있다는 개념과 관련하여, 본질적으로 무작위한 데이터 속에서 훈련된 이미지를 식별하려는 심층(20-30층) 신경망의 내부 상태를 그래픽으로 표현한 일련의 출판물[^279]은 시각적 매력을 보여준다: 원래의 연구 공지는 1,000개 이상의 댓글을 받았으며, 한때 가디언[^280] 웹사이트에서 가장 많이 조회된 기사의 주제가 되었다.
혁신 확산 이론(IDT)의 지원을 받아, 한 연구는 구글 트렌드 데이터를 사용하여 BRICS 및 OECD 국가에서의 딥러닝 확산[^281]을 분석하였다.
오류
일부 딥러닝 아키텍처는 문제적 행동을 보이는데,[^159] 인식할 수 없는 이미지를 일반적인 이미지의 친숙한 범주에 속하는 것으로 확신을 가지고 분류하거나(2014)[^282] 올바르게 분류된 이미지의 극히 미세한 변형을 오분류하는 것(2013)[^283] 등이 있다. 괴르첼은 이러한 행동이 내부 표현의 한계에 기인하며, 이러한 한계가 이질적인 다중 구성요소 범용 인공지능(AGI) 아키텍처로의 통합을 저해할 것이라고 가설을 세웠다.[^159] 이러한 문제는 관찰된 개체와 사건의 이미지 문법[^284] 분해와 상동적인 상태를 내부적으로 형성하는 딥러닝 아키텍처에 의해 해결될 수 있을 것이다.[^159] 훈련 데이터에서 문법(시각적 또는 언어적)을 학습하는 것은 문법적 생성 규칙의 관점에서 개념에 대해 작동하는 상식적 추론으로 시스템을 제한하는 것과 동등하며, 이는 인간 언어 습득[^285]과 인공지능(AI)[^286] 모두의 기본적인 목표이다.
사이버 위협
딥러닝이 연구실에서 현실 세계로 이동함에 따라, 연구와 경험은 인공 신경망이 해킹과 기만에 취약하다는 것을 보여준다.[^287] 이러한 시스템이 기능하는 데 사용하는 패턴을 식별함으로써, 공격자는 인간 관찰자가 인식하지 못할 일치를 ANN이 찾도록 ANN에 대한 입력을 수정할 수 있다. 예를 들어, 공격자는 이미지가 인간의 눈에는 검색 대상과 전혀 닮지 않았음에도 ANN이 일치를 찾도록 이미지에 미묘한 변경을 가할 수 있다. 이러한 조작을 "적대적 공격"이라 한다.[^288]
2016년 연구자들은 하나의 ANN을 사용하여 시행착오 방식으로 이미지를 조작하고, 다른 ANN의 초점을 식별하여, 이를 속이는 이미지를 생성했다. 수정된 이미지는 인간의 눈에는 다르게 보이지 않았다. 또 다른 그룹은 조작된 이미지의 인쇄물을 사진으로 촬영하여 이미지 분류 시스템을 성공적으로 속일 수 있음을 보여주었다.[^160] 하나의 방어 수단은 역이미지 검색으로, 가짜일 수 있는 이미지를 TinEye와 같은 사이트에 제출하면 해당 이미지의 다른 인스턴스를 찾을 수 있다. 이를 정교화한 방법은 이미지의 일부만을 사용하여 검색함으로써 해당 부분이 가져온 원본 이미지를 식별하는 것이다**.**[^289]
또 다른 그룹은 특정 환각적 안경이 안면 인식 시스템을 속여 일반인을 유명인으로 인식하게 만들 수 있으며, 이를 통해 한 사람이 다른 사람을 사칭할 수 있음을 보여주었다. 2017년 연구자들은 정지 표지판에 스티커를 붙여 ANN이 이를 오분류하도록 만들었다.[^160]
그러나 ANN은 기만 시도를 탐지하도록 추가 훈련될 수 있으며, 이는 잠재적으로 공격자와 방어자를 이미 악성 소프트웨어 방어 산업을 특징짓는 것과 유사한 군비 경쟁으로 이끌 수 있다. ANN은 유전 알고리즘에 의해 지속적으로 변형된 악성 소프트웨어로 방어를 반복적으로 공격하여 대상을 손상시키는 능력을 유지하면서 안티멀웨어를 속일 때까지 ANN 기반 안티멀웨어 소프트웨어를 무력화하도록 훈련되었다.[^160]
2016년, 또 다른 그룹은 특정 소리가 구글 나우 음성 명령 시스템으로 하여금 특정 웹 주소를 열게 만들 수 있음을 시연하고, 이것이 "추가 공격의 발판이 될 수 있다(예: 드라이브 바이 악성 소프트웨어를 호스팅하는 웹 페이지 열기)"라고 가설을 세웠다.[^160]
"데이터 오염"에서는 허위 데이터가 기계 학습 시스템의 훈련 세트에 지속적으로 밀반입되어 시스템이 숙달에 도달하는 것을 방해한다.[^160]
데이터 수집 윤리
지도 학습을 사용하여 훈련되는 딥러닝 시스템은 종종 인간이 생성하거나 주석을 달거나, 또는 둘 다 수행한 데이터에 의존한다.[^290] 이러한 목적을 위해 저임금 클릭워크(예: 아마존 메커니컬 터크)만이 정기적으로 활용되는 것이 아니라, 종종 그렇게 인식되지 않는 암묵적 형태의 인간 마이크로워크도 활용된다는 주장이 제기되었다.[^161] 철학자 라이너 뮐호프는 훈련 데이터를 생성하기 위한 인간 마이크로워크의 "기계적 포획" 다섯 가지 유형을 구분한다: (1) 게임화(게임의 흐름 속에 주석 또는 계산 작업을 내장하는 것), (2) "트래핑과 추적"(예: 이미지 인식을 위한 CAPTCHA 또는 구글 검색 결과 페이지에서의 클릭 추적), (3) 사회적 동기의 이용(예: 라벨링된 얼굴 이미지를 얻기 위해 페이스북에서 얼굴에 태그하기), (4) 정보 채굴(예: 활동 추적기와 같은 자기 정량화 기기를 활용), 그리고 (5) 클릭워크.[^161]
같이 보기
- 인공지능의 응용
- 딥러닝 소프트웨어 비교
- 압축 센싱
- 미분 가능 프로그래밍
- 에코 상태 네트워크
- 인공지능 프로젝트 목록
- 리퀴드 상태 머신
- 기계학습 연구를 위한 데이터셋 목록
- 저수지 컴퓨팅
- 스케일 공간과 딥러닝
- 희소 코딩
- 확률적 앵무새
- 위상적 딥러닝
더 읽을거리
Please be cautious about adding more external links.
Wikipedia is not a collection of links and should not be used for advertising.
Excessive or inappropriate links will be removed.
See Wikipedia:External links and Wikipedia:Spam for details.
If there are already suitable links, propose additions or replacements on the article's talk page, or submit your link to the relevant category at DMOZ (dmoz.org) and link there using .
-->
참고 문헌
[^1]: LeCun, Yann. 딥 러닝
[^2]: Ciresan, D.. 2012 IEEE 컴퓨터 비전 및 패턴 인식 컨퍼런스
[^3]: Krizhevsky, Alex. 심층 합성곱 신경망을 이용한 ImageNet 분류. (2012)
[^4]: Bengio, Yoshua. AI를 위한 심층 아키텍처 학습
[^5]: Bengio, Y.. 표현 학습: 리뷰 및 새로운 관점
[^6]: cite conference first1=Yoshua last1=Bengio first2=Pascal last2=Lamblin first3=Dan last3=Popovici first4=Hugo last4=Larochelle title=심층 네트워크의 탐욕적 계층별 훈련 year
[^7]: cite journal last1 = Hinton first1 = G.E. year = 2009 title = 심층 신뢰 네트워크 journal = Scholarpedia volume = 4 issue = 5 page = 5947 doi=10.4249/scholarpedia.5947 bibcode = 2009
[^9]: 다치 및 범용 이진 뉴런. Science & Business Media. (2000)
[^10]: cite journal last1 = Cybenko year = 1989 title = 시그모이드 함수의 중첩에 의한 근사 url = http://deeplearning.cs.cmu.edu/pdfs/Cybenko.pdf journal = [[Mathematics of Cont
[^11]: cite journal last1 = Hornik first1 = Kurt year = 1991 title = 다층 순방향 네트워크의 근사 능력 journal = Neural Networks volume = 4 issue = 2 pages = 251–25
[^13]: Deng, L.. 딥 러닝: 방법과 응용
[^14]: Schmidhuber, J.. 신경망에서의 딥 러닝: 개요
[^15]: Murphy, Kevin P.. 머신 러닝: 확률적 관점. MIT Press. (2012년 8월 24일)
[^16]: Fukushima, K.. 아날로그 임계 소자의 다층 네트워크에 의한 시각 특징 추출. (1969)
[^17]: cite journal last1 = Sonoda first1 = Sho last2=Murata first2=Noboru s2cid = 12149203 year = 2017 title = 무한 활성화 함수를 가진 신경망은 범용 근사기이다 jo
[^18]: 패턴 인식과 머신 러닝. Springer
[^19]: bibliotheca Augustana
[^20]: Brush, Stephen G.. 렌츠-이징 모형의 역사
[^21]: Amari, Shun-Ichi. 임계 소자의 자기 조직화 네트워크에 의한 패턴 및 패턴 시퀀스 학습. (1972)
[^22]: Hopfield, J. J.. 창발적 집단 계산 능력을 가진 신경망과 물리 시스템. (1982)
[^23]: Nakano, Kaoru. 패턴 인식과 머신 러닝. (1971)
[^24]: Nakano, Kaoru. 어소시에이트론 - 연상 기억 모델. (1972)
[^25]: Turing, Alan. AM 튜링 전집: 기계적 지능. Elsevier Science Publishers
[^26]: Rosenblatt, Frank. 신경역학의 원리. Spartan, New York
[^27]: Joseph, R. D.. 퍼셉트론 이론에 대한 기여, 코넬 항공 연구소 보고서 번호 VG-11 96--G-7, 버팔로
[^28]: Ivakhnenko, A. G.. 사이버네틱스와 예측 기법. American Elsevier Publishing Co.
[^29]: Ivakhnenko, Alexey. 복잡 시스템의 다항식 이론. (1971)
[^30]: Cite journal last1 = Robbins first1 = H. author-link = Herbert Robbins last2 = Monro first2 = S. doi = 10.1214/aoms/1177729586 title = 확률적 근사 방법 journal = The An
[^31]: Amari, Shun'ichi. 적응적 패턴 분류기 이론. (1967)
[^32]: Schmidhuber, Jürgen. 현대 AI와 딥 러닝의 주석 달린 역사. (2022)
[^33]: Fukushima, K.. 위치 이동에 영향받지 않는 패턴 인식 메커니즘을 위한 신경망 모델 — 네오코그니트론
[^34]: Fukushima, K.. 네오코그니트론: 위치 이동에 영향받지 않는 패턴 인식 메커니즘을 위한 자기 조직화 신경망 모델
[^35]: Leibniz, Gottfried Wilhelm Freiherr von. 라이프니츠의 초기 수학 원고: 카를 이마누엘 게르하르트가 출판한 라틴어 텍스트의 번역본, 비판적 및 역사적 주석 포함 (라이프니츠는 1676년 논문에서 연쇄 법칙을 발표했다). Open court publishing Company. (1920)
[^36]: Kelley, Henry J.. 최적 비행 경로의 기울기 이론
[^37]: Linnainmaa, Seppo. 알고리즘의 누적 반올림 오차를 국소 반올림 오차의 테일러 전개로 표현. 헬싱키 대학교
[^38]: Linnainmaa, Seppo. 누적 반올림 오차의 테일러 전개
[^39]: Ostrovski, G.M., Volin, Y.M., and Boris, W.W. (1971). 도함수의 계산에 관하여. Wiss. Z. Tech. Hochschule for Chemistry, 13:382–384.
[^40]: Werbos, Paul. 시스템 모델링과 최적화. Springer
[^41]: Werbos, Paul J.. 역전파의 뿌리: 순서 미분에서 신경망과 정치 예측까지. John Wiley & Sons
[^42]: cite web last = Schmidhuber first = Juergen title = 역전파를 발명한 사람은 누구인가? author-link=Juergen Schmidhuber publisher = IDSIA, Switzerland url = https://people.idsia.ch/~juergen/who-
[^44]: Waibel, Alex. 시간 지연 신경망을 이용한 음소 인식. (1987년 12월)
[^45]: [[Alex Waibel Alexander Waibel]] et al., ''[http://www.inf.ufrgs.br/~engel/data/media/file/cmp121/waibel89_TDNN.pdf 시간 지연 신경망을 이용한 음소 인식]'' IEEE Transactions on Acousti
[^46]: Zhang, Wei. 이동 불변 패턴 인식 신경망과 그 광학 아키텍처. (1988)
[^47]: LeCun ''et al.'', "필기 우편번호 인식에 적용된 역전파", ''Neural Computation'', 1, pp. 541–551, 1989.
[^48]: Zhang, Wei. 국소 공간 불변 연결을 가진 병렬 분산 처리 모델과 그 광학 아키텍처. (1990)
[^49]: LeCun, Yann. 문서 인식에 적용된 기울기 기반 학습
[^50]: Schmidhuber, Jürgen. 신경 시퀀스 청커. (1991년 4월)
[^51]: Schmidhuber, Jürgen. 이력 압축 원리를 이용한 복잡하고 확장된 시퀀스 학습 (TR FKI-148, 1991 기반)
[^52]: Schmidhuber, Jürgen. 교수 자격 논문: 시스템 모델링과 최적화
[^54]: Hochreiter, S.. 동적 순환 네트워크 실전 가이드. John Wiley & Sons. (2001년 1월 15일)
[^55]: Cite book doi = 10.1049/cp:19991218 chapter = 망각 학습: LSTM을 이용한 연속 예측 title = 제9회 국제 인공 신경망 컨퍼런스: ICANN '99 volume = 1999 pages = 85
[^56]: cite conference title = 모델 구축 신경 제어기에서 호기심과 지루함을 구현하는 가능성 last1 = Schmidhuber first1 = Jürgen author-link = Jürgen Schmidhuber date = 1
[^57]: Schmidhuber, Jürgen. 창의성, 재미, 내적 동기의 형식 이론 (1990-2010)
[^58]: Schmidhuber, Jürgen. 생성적 적대 신경망은 인공 호기심(1990)의 특수 사례이며 예측 가능성 최소화(1991)와도 밀접하게 관련된다. (2020)
[^59]: Peter, Dayan. 헬름홀츠 기계.. (1995)
[^60]: Hinton, Geoffrey E.. 비지도 신경망을 위한 각성-수면 알고리즘. (1995-05-26)
[^61]: Robinson, T.. 실시간 순환 오차 전파 네트워크 단어 인식 시스템. (1992)
[^62]: cite journal last1 = Baker first1 = J. last2 = Deng first2 = Li last3 = Glass first3 = Jim last4 = Khudanpur first4 = S. last5 = Lee first5 = C.-H. last6 = Morgan first6 = N.
[^63]: Bengio, Y.. 인공 신경망과 음성/시퀀스 인식에 대한 적용. 맥길 대학교 박사 학위 논문. (1991)
[^64]: cite journal last1 = Deng first1 = L. last2 = Hassanein first2 = K. last3 = Elmasry first3 = M. year = 1994 title = 신경 예측 모델에 대한 상관 구조 분석
[^65]: cite journal last1 = Doddington first1 = G. last2 = Przybocki first2 = M. last3 = Martin first3 = A. last4 = Reynolds first4 = D. year = 2000 title = NIST 화자 인식
[^66]: Heck, L.. 판별적 특징 설계를 통한 화자 인식에서의 전화 핸드셋 왜곡에 대한 강건성
[^67]: Graves, Alex. LSTM 신경망을 이용한 생물학적으로 타당한 음성 인식. (2003)
[^68]: Graves, Alex. 연결주의적 시간 분류: 순환 신경망을 이용한 분할되지 않은 시퀀스 데이터의 레이블링. (2006)
[^70]: Hinton, G. E.. 심층 신뢰 네트워크를 위한 빠른 학습 알고리즘
[^73]: cite journal last1 = Hinton first1 = G. last2 = Deng first2 = L. last3 = Yu first3 = D. last4 = Dahl first4 = G. last5 = Mohamed first5 = A. last6 = Jaitly first6 = N. last7
[^74]: Yu, D.. 자동 음성 인식: 딥 러닝 접근법 (출판사: Springer). Springer. (2014)
[^75]: cite web last1=Deng first1=L. last2=Hinton first2=G. last3=Kingsbury first3=B. date=2013년 5월 title=음성 인식 및 관련 응용을 위한 새로운 유형의 심층 신경망 학습: An
[^76]: Li, Deng. 기조 연설: '딥 러닝의 성과와 도전 - 음성 분석 및 인식에서 언어 및 다중 모달 처리까지'. (2014년 9월)
[^77]: Yu, D.. 실세계 음성 인식에서 문맥 의존 DBN-HMM의 사전 훈련과 미세 조정의 역할. (2010)
[^78]: Oh, K.-S.. 신경망의 GPU 구현
[^79]: Chellapilla, Kumar. 문서 처리를 위한 고성능 합성곱 신경망. (2006)
[^80]: Sze, Vivienne. 심층 신경망의 효율적 처리: 튜토리얼 및 서베이
[^81]: Cireşan, Dan Claudiu. 필기 숫자 인식을 위한 심층, 대규모, 단순 신경망. (2010년 9월 21일)
[^82]: Ciresan, D. C.. 이미지 분류를 위한 유연한 고성능 합성곱 신경망. (2011)
[^83]: Ciresan, Dan. 신경 정보 처리 시스템의 진보 25. Curran Associates, Inc.. (2012)
[^84]: Ciresan, D.. 의료 영상 컴퓨팅 및 컴퓨터 보조 중재 – MICCAI 2013. (2013)
[^85]: Ng, Andrew. 대규모 비지도 학습을 이용한 고수준 특징 구축
[^86]: Simonyan, Karen. 대규모 이미지 인식을 위한 매우 깊은 합성곱 네트워크
[^87]: Szegedy, Christian. 합성곱을 더 깊게. (2015)
[^88]: Vinyals, Oriol. 보여주고 말하기: 신경 이미지 캡션 생성기
[^89]: Fang, Hao. 캡션에서 시각 개념으로, 그리고 다시 돌아가기
[^90]: Kiros, Ryan. 다중 모달 신경 언어 모델을 이용한 시각-의미 임베딩 통합
[^91]: He, Kaiming. 정류기 깊이 탐구: ImageNet 분류에서 인간 수준 성능 초과
[^92]: He, Kaiming. 심층 잔차 학습을 이용한 이미지 인식. (2015년 12월 10일)
[^93]: He, Kaiming. 2016 IEEE 컴퓨터 비전 및 패턴 인식 컨퍼런스 (CVPR). IEEE. (2016)
[^94]: Goodfellow, Ian. 생성적 적대 신경망
[^95]: GAN 2.0: NVIDIA의 초사실적 얼굴 생성기. (2018년 12월 14일)
[^96]: Karras, T.. 향상된 품질, 안정성 및 다양성을 위한 GAN의 점진적 성장. (2018년 2월 26일)
[^97]: Google Research Blog. 구글 음성 전사 뒤의 신경망. 2015년 8월 11일. By Françoise Beaufays http://googleresearch.blogspot.co.at/2015/08/the-neural-networks-behind-google-voice
[^98]: Sak, Haşim. 구글 음성 검색: 더 빠르고 더 정확하게. (2015년 9월)
[^99]: Sak, Hasim. 대규모 음향 모델링을 위한 장단기 기억 순환 신경망 아키텍처. (2014)
[^100]: Li, Xiangang. 대규모 어휘 음성 인식을 위한 LSTM 기반 심층 순환 신경망 구축
[^101]: Zen, Heiga. 저지연 음성 합성을 위한 순환 출력 계층을 가진 단방향 장단기 기억 순환 신경망. ICASSP. (2015)
[^102]: 딥 러닝 및 신경망 가이드
[^103]: cite journal last1 = Kumar first1 = Nishant last2 = Raubal first2 = Martin title = 혼잡 탐지, 예측 및 완화에서의 딥 러닝 응용: 서베이 journal =
[^104]: Rolnick, David. 자연 함수 표현을 위한 더 깊은 네트워크의 힘. (2018)
[^105]: Gers, Felix A.. LSTM 순환 네트워크는 단순 문맥 자유 및 문맥 의존 언어를 학습한다
[^106]: Jozefowicz, Rafal. 언어 모델링의 한계 탐구
[^107]: Gillick, Dan. 바이트를 이용한 다국어 언어 처리
[^108]: Mikolov, T.. 순환 신경망 기반 언어 모델. (2010)
[^109]: Hochreiter, Sepp. 장단기 기억. (1997년 11월 1일)
[^110]: LSTM 순환 네트워크를 이용한 정밀 타이밍 학습 (PDF 다운로드 가능)
[^111]: LeCun, Y.. 문서 인식에 적용된 기울기 기반 학습
[^112]: Sainath, Tara N.. 2013 IEEE 국제 음향, 음성 및 신호 처리 컨퍼런스
[^113]: Dahl, G.. 정류 선형 유닛과 드롭아웃을 이용한 대규모 어휘 연속 음성 인식용 DNN 개선. (2013)
[^114]: cite journal last1 = Kumar first1 = Nishant last2 = Martin first2 = Henry last3 = Raubal first3 = Martin title = 딥 러닝 기반 도시 전역 교통 예측 파이프라인 향상
[^115]: Hinton, G. E.. 제한된 볼츠만 머신 훈련을 위한 실용 가이드. (2010)
[^116]: Ting Qin, et al. "RLS 기반 CMAC 학습 알고리즘". Neural Processing Letters 19.1 (2004): 49-61.
[^118]: Marega, Guilherme Migliato. 원자 수준 두께 반도체 기반 로직 인 메모리
[^119]: Feldmann, J.. 집적 광자 텐서를 이용한 병렬 합성곱 처리
[^120]: cite book title=TIMIT 음향-음소 연속 음성 말뭉치 author1=Garofolo, J.S. author2=Lamel, L.F. author3=Fisher, W.M. author4=Fiscus, J.G. author5=Pallett, D.S. author6=Dahlgren, N.L
[^121]: Abdel-Hamid, O.. 음성 인식을 위한 합성곱 신경망. (2014)
[^122]: Deng, L.. 음성 인식을 위한 앙상블 딥 러닝. (2014)
[^123]: Tóth, László. 계층적 합성곱 심층 맥스아웃 네트워크를 이용한 음소 인식. (2015)
[^124]: Hannun, Awni. 딥 스피치: 종단 간 음성 인식의 확장
[^125]: MNIST 필기 숫자 데이터베이스, Yann LeCun, Corinna Cortes 및 Chris Burges
[^126]: Cireşan, Dan. 교통 표지판 분류를 위한 다중 열 심층 신경망. (2012년 8월)
[^127]: 인간 수준을 초월하는 얼굴 인식
[^128]: 예술가로서의 기계: 서론. (2017년 4월 10일)
[^129]: 기계 지능 시대의 예술. (2017년 9월 29일)
[^130]: Goldberg, Yoav. word2vec 설명: Mikolov 등의 네거티브 샘플링 단어 임베딩 방법 유도
[^131]: Socher, Richard. 자연어 처리를 위한 딥 러닝
[^132]: cite book title=2013 경험적 자연어 처리 방법 컨퍼런스 논문집 author1=Socher, R. author2=Perelygin, A. author3=Wu, J. author4=Chuang, J. author5=Manning,
[^133]: cite journal last1 = Mesnil first1 = G. last2 = Dauphin first2 = Y. last3 = Yao first3 = K. last4 = Bengio first4 = Y. last5 = Deng first5 = L. last6 = Hakkani-Tur first6 = D.
[^134]: Sutskever, L.. 신경망을 이용한 시퀀스 투 시퀀스 학습. (2014)
[^135]: Gao, Jianfeng. 번역 모델링을 위한 연속 구문 표현 학습. (2014년 6월 1일)
[^136]: Cite journal doi = 10.1002/dac.3259 title = 심층 신뢰 네트워크 시스템을 이용한 저자 검증 journal = International Journal of Communication Systems volume = 30 issue = 12 article-number =
[^137]: Turovsky, Barak. 번역에서 발견: 구글 번역의 더 정확하고 유창한 문장. (2016년 11월 15일)
[^138]: Schuster, Mike. 구글의 다국어 신경 기계 번역 시스템을 이용한 제로샷 번역. (2016년 11월 22일)
[^139]: Wu, Yonghui. 구글의 신경 기계 번역 시스템: 인간과 기계 번역 사이의 격차 해소
[^140]: Metz, Cade. AI 주입으로 구글 번역이 그 어느 때보다 강력해지다. (2016년 9월 27일)
[^141]: Boitet, Christian. 웹 위의, 웹을 위한 기계 번역. (2010)
[^142]: Cite journal pmid = 23903212 year = 2013 last1 = Arrowsmith first1 = J title = 시험 관찰: 2011-2012년 2상 및 3상 탈락률 journal = Nature Reviews Drug Discovery volum
[^143]: Cite journal pmid = 25582842 year = 2015 last1 = Verbist first1 = B title = 전사체학을 활용한 신약 개발 프로젝트의 선도 물질 최적화 안내: QSTAR 프로젝트의 교훈
[^144]: 머크 분자 활성 챌린지
[^145]: QSAR 예측을 위한 다중 작업 신경망 {{!
[^146]: "21세기 독성학 데이터 챌린지"
[^147]: NCATS, Tox21 데이터 챌린지 수상자 발표
[^148]: NCATS, Tox21 데이터 챌린지 수상자 발표
[^149]: Cite news title = 토론토 스타트업이 효과적인 의약품을 더 빨리 발견하는 방법을 갖다 url = https://www.theglobeandmail.com/report-on-business/small-business/starting-out/toronto-startup-has-a-faster-w
[^150]: Shalev, Y.. 신경 결합 엔트로피 추정. (2022)
[^151]: 육군 연구진, 로봇 훈련을 위한 새로운 알고리즘 개발
[^152]: cite journal last1=Han first1=J. last2=Jentzen first2=A. last3=E first3=W. title=딥 러닝을 이용한 고차원 편미분 방정식 풀기 journal=Proceedings of the
[^153]: cite journal last1 = Utgoff first1 = P. E. last2 = Stracuzzi first2 = D. J. s2cid = 1119517 year = 2002 title = 다층 학습 journal = Neural Computation volume = 14 issue
[^154]: Elman, Jeffrey L.. 선천성 재고: 발달에 대한 연결주의적 관점. MIT Press
[^155]: cite journal last1 = Shrager first1 = J. last2 = Johnson first2 = MH year = 1996 title = 동적 가소성이 단순 피질 배열에서 기능의 출현에 미치는 영향 journal = Neur
[^156]: cite journal last1 = Quartz first1 = SR last2 = Sejnowski first2 = TJ year = 1997 title = 인지 발달의 신경적 기반: 구성주의적 선언 journal = Behavioral and B
[^157]: S. Blakeslee, "뇌의 초기 성장에서 시간표가 중요할 수 있다", ''The New York Times, Science Section'', pp. B5–B6, 1995.
[^158]: Metz, C.. 페이스북의 '딥 러닝' 대가가 밝히는 AI의 미래. (2013년 12월 12일)
[^159]: Goertzel, Ben. 오늘날의 딥 러닝 알고리즘의 병리 현상 뒤에 깊은 이유가 있는가?
[^160]: AI는 속이기 쉽다 — 왜 이것이 바뀌어야 하는가. (2017년 10월 10일)
[^161]: Mühlhoff, Rainer. 인간이 돕는 인공지능: 또는 인간의 뇌에서 대규모 계산을 실행하는 방법? 머신 러닝의 미디어 사회학을 향하여. (2019년 11월 6일)
[^162]: Schulz, Hannes. 딥 러닝. (2012년 11월 1일)
[^163]: 구글의 AlphaGo AI, 세계 최고의 바둑 기사를 상대로 3전 시리즈 우승. (2017년 5월 25일)
[^164]: 신경망과 뇌를 비교할 때 주의를 촉구하는 연구. (2022-11-02)
[^165]: Shigeki, Sugiyama. 의식에서의 인간 행동과 또 다른 종류: 새로운 연구와 기회: 새로운 연구와 기회. IGI Global. (2019년 4월 12일)
[^166]: 공진화하는 순환 뉴런은 심층 기억 POMDP를 학습한다. Proc. GECCO, Washington, D. C., pp. 1795–1802, ACM Press, New York, NY, USA, 2005.
[^167]: Fradkov, Alexander L.. 머신 러닝의 초기 역사. (2020-01-01)
[^168]: Orhan, A. E.. 비확률적 피드백으로 훈련된 일반 신경망에서의 효율적 확률적 추론. (2017)
[^169]: Rosenblatt, F.. 퍼셉트론: 뇌에서의 정보 저장 및 조직화를 위한 확률 모델.. (1958)
[^170]: Ivakhnenko, A.G.. 공학 사이버네틱스 문제에서의 발견적 자기 조직화. (1970년 3월)
[^171]: Ramachandran, Prajit. 활성화 함수 탐색. (2017년 10월 16일)
[^172]: Rumelhart, David E.. 오차 역전파에 의한 표현 학습. (1986년 10월)
[^173]: Zhang, Wei. 학습 네트워크를 기반으로 한 인간 각막 내피 영상 처리. (1991)
[^174]: Zhang, Wei. 이동 불변 인공 신경망을 이용한 디지털 유방 촬영 영상에서의 미세 석회화 군집 컴퓨터 탐지. (1994)
[^175]: Jordan, Michael I.. 연결주의적 순차 기계에서의 끌개 역학과 병렬성. (1986)
[^176]: Elman, Jeffrey L.. 시간 속에서 구조 찾기. (1990년 3월)
[^177]: Cite Q Q98967430
[^178]: Ackley, David H.. 볼츠만 머신을 위한 학습 알고리즘. (1985-01-01)
[^179]: Smolensky, Paul. 병렬 분산 처리: 인지의 미시 구조 탐구, 제1권: 기초. MIT Press
[^180]: Sejnowski, Terrence J.. 딥 러닝 혁명. [[The MIT Press]]. (2018)
[^181]: Qian, Ning. 신경망 모델을 이용한 구상 단백질의 이차 구조 예측. (1988-08-20)
[^182]: Morgan, Nelson. 연속 음성 인식을 위한 하이브리드 신경망/은닉 마르코프 모형 시스템. (1993년 8월 1일)
[^183]: Waibel, A.. 시간 지연 신경망을 이용한 음소 인식. (1989년 3월)
[^184]: L.P Heck and R. Teunen. "Nuance Verifier를 이용한 안전하고 편리한 거래". Nuance Users Conference, 1998년 4월.
[^185]: 대규모 어휘 연속 음성 인식을 위한 원시 시간 신호를 사용한 심층 신경망 음향 모델링 (PDF 다운로드 가능)
[^186]: Graves, Alex; and Schmidhuber, Jürgen; ''다차원 순환 신경망을 이용한 오프라인 필기 인식'', in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.;
[^187]: Hinton, Geoffrey E.. 다중 표현 계층 학습. (2007년 10월 1일)
[^188]: Hinton, Geoffrey E.. 다중 표현 계층 학습. (2007년 10월)
[^189]: Hinton, Geoffrey E.. 심층 신뢰 네트워크를 위한 빠른 학습 알고리즘. (2006년 7월)
[^190]: Hinton, Geoffrey E.. 심층 신뢰 네트워크. (2009-05-31)
[^191]: Deng, 권위 있는 IEEE 기술 성과상 수상 - Microsoft Research. (2015년 12월 3일)
[^192]: Seide, F.. Interspeech 2011. (2011)
[^193]: Deng, Li. 마이크로소프트의 음성 연구를 위한 딥 러닝의 최근 발전. (2013년 5월 1일)
[^194]: Raina, Rajat. 제26회 국제 머신 러닝 연례 컨퍼런스 논문집. Association for Computing Machinery. (2009-06-14)
[^195]: Simonyan, Karen. 대규모 이미지 인식을 위한 매우 깊은 합성곱 네트워크. (2015-04-10)
[^196]: Gatys, Leon A.. 예술적 스타일의 신경 알고리즘. (2015년 8월 26일)
[^197]: 당황하지 말고 대비하라: 합성 미디어와 딥페이크. witness.org
[^198]: Sohl-Dickstein, Jascha. 비평형 열역학을 이용한 심층 비지도 학습. PMLR. (2015-06-01)
[^199]: Singh, Premjeet. 2021 국제 컴퓨터 통신 및 정보학 컨퍼런스 (ICCCI)
[^200]: 2018 ACM A.M. 튜링상 수상자
[^201]: 아기를 위한 신경망. Sourcebooks
[^202]: Silver, David. 심층 신경망과 트리 탐색을 이용한 바둑 게임 정복. (2016년 1월)
[^203]: Szegedy, Christian. 객체 탐지를 위한 심층 신경망. (2013)
[^204]: Hof, Robert D.. 인공지능이 마침내 제자리를 찾고 있는가?
[^205]: Bengio, Yoshua. 2013 IEEE 국제 음향, 음성 및 신호 처리 컨퍼런스
[^206]: 데이터 증강 - deeplearning.ai {{!
[^207]: You, Yang. 고성능 컴퓨팅, 네트워킹, 스토리지 및 분석을 위한 국제 컨퍼런스 논문집 - SC '17. SC '17, ACM. (2017년 11월)
[^208]: Viebke, André. CHAOS: Intel Xeon Phi에서 합성곱 신경망 훈련을 위한 병렬화 방식
[^209]: Research, AI. 음성 인식에서의 음향 모델링을 위한 심층 신경망. (2015년 10월 23일)
[^210]: GPU, 당분간 AI 가속기 시장 계속 지배. (2019년 12월)
[^211]: Ray, Tiernan. AI가 컴퓨팅의 전체 본질을 바꾸고 있다. (2019)
[^212]: AI와 컴퓨팅. (2018년 5월 16일)
[^213]: 화웨이, IFA 2017에서 모바일 AI의 미래를 공개 | 화웨이 최신 뉴스 | 화웨이 글로벌
[^214]: P, JouppiNorman. 텐서 처리 장치의 데이터센터 내 성능 분석. (2017-06-24)
[^215]: Woodie, Alex. 세레브라스, 딥 러닝 워크로드를 위한 가속기 출시. (2021-11-01)
[^216]: 세레브라스, 2.6조 개 트랜지스터를 가진 새로운 AI 슈퍼컴퓨팅 프로세서 출시. (2021-04-20)
[^217]: Robinson, Tony. 순환 오차 전파 네트워크 음소 인식 시스템의 여러 개선 사항. (1991년 9월 30일)
[^218]: cite arXiv author1=Aaron van den Oord last2=Dieleman first2=Sander last3=Zen first3=Heiga last4=Simonyan first4=Karen last5=Vinyals first5=Oriol last6=Graves first6=Alex last7=
[^219]: WaveNet: 원시 오디오를 위한 생성 모델. (2016-09-08)
[^220]: cite arXiv last1=Latif first1=Siddique last2=Zaidi first2=Aun last3=Cuayahuitl first3=Heriberto last4=Shamshad first4=Fahad last5=Shoukat first5=Moazzam last6=Usama first6=Muha
[^221]: McMillan, Robert. 스카이프가 AI를 사용해 놀라운 새 언어 번역기를 구축한 방법 {{!. (2014년 12월 17일)
[^222]: [http://www.technologyreview.com/news/533936/nvidia-demos-a-car-computer-trained-with-deep-learning/ 엔비디아, "딥 러닝"으로 훈련된 차량용 컴퓨터 시연] (2015년 1월 6일), David Talbot, ''[[MIT T
[^223]: Cite journal url = http://aclweb.org/anthology/P/P13/P13-1045.pdf title = 합성 벡터 문법을 이용한 구문 분석 last1 = Socher first1 = Richard date = 2013 journal = Proceedings of the ACL 2013 C
[^224]: 정보 검색을 위한 합성곱 풀링 구조를 가진 잠재 의미 모델. (2014년 11월 1일)
[^225]: Huang, Po-Sen. 클릭스루 데이터를 이용한 웹 검색을 위한 심층 구조 의미 모델 학습. (2013년 10월 1일)
[^226]: Kariampuzha, William. 대규모 희귀 질환 역학을 위한 정밀 정보 추출. (2023)
[^227]: 자연어 처리를 위한 딥 러닝: 이론과 실습 (CIKM2014 튜토리얼) - Microsoft Research
[^228]: cite arXiv title = AtomNet: 구조 기반 약물 발견에서 생물학적 활성 예측을 위한 심층 합성곱 신경망 eprint= 1510.02855 date = 2015년 10월 9일 first1 = Izhar last1 = Wallach fir
[^229]: Cite web title = 스타트업, 슈퍼컴퓨터를 활용해 치료법 모색 url = http://ww2.kqed.org/futureofyou/2015/05/27/startup-harnesses-supercomputers-to-seek-cures/ website = KQED Future of You date=2015년 5월 27일
[^230]: Gilmer, Justin. 양자 화학을 위한 신경 메시지 전달. (2017-06-12)
[^231]: Zhavoronkov, Alex. 딥 러닝을 이용한 강력한 DDR1 키나제 억제제의 신속한 식별. (2019)
[^232]: Gregory, Barber. AI가 설계한 분자, '약물 유사' 특성 보여
[^233]: van den Oord, Aaron. 신경 정보 처리 시스템의 진보 26. Curran Associates, Inc.. (2013)
[^234]: cite journal last1 = Feng first1 = X.Y. last2 = Zhang first2 = H. last3 = Ren first3 = Y.J. last4 = Shang first4 = P.H. last5 = Zhu first5 = Y. last6 = Liang first6 = Y.C. la
[^235]: Elkahky, Ali Mamdouh. 추천 시스템에서의 교차 도메인 사용자 모델링을 위한 다중 관점 딥 러닝 접근법. (2015년 5월 1일)
[^236]: Chicco, Davide. 제5회 ACM 생물정보학, 전산생물학 및 건강정보학 컨퍼런스 논문집. ACM. (2014년 1월 1일)
[^237]: Sathyanarayana, Aarti. 웨어러블 데이터에서 딥 러닝을 이용한 수면 품질 예측. (2016년 1월 1일)
[^238]: Choi, Edward. 순환 신경망 모델을 이용한 심부전 발병의 조기 탐지. (2016년 8월 13일)
[^239]: 딥마인드의 단백질 접힘 AI가 생물학의 50년 된 대과제를 해결하다
[^240]: Shead, Sam. 딥마인드, 알파폴드 AI로 단백질 접힘 '대과제' 해결. (2020-11-30)
[^241]: Litjens, Geert. 의료 영상 분석에서의 딥 러닝 서베이. (2017년 12월)
[^242]: Forslid, Gustav. 2017 IEEE 국제 컴퓨터 비전 워크숍 (ICCVW)
[^243]: Dong, Xin. 딥 러닝 프레임워크 기반 하이브리드 완전 합성곱 신경망을 이용한 간암 탐지. (2020)
[^244]: Lyakhov, Pavel Alekseevich. 다중 모달 신경망 기반 이종 데이터 융합 및 분석을 이용한 색소 피부 병변 인식 시스템. (2022-04-03)
[^245]: De, Shaunak. 2017 제2회 국제 통신 시스템, 컴퓨팅 및 IT 응용 컨퍼런스 (CSCITA)
[^246]: 딥 러닝을 이용한 오래된 이미지의 색상 복원 및 복구. (2018년 11월 13일)
[^247]: Schmidt, Uwe. 효과적인 이미지 복원을 위한 수축 필드
[^248]: Kleanthous, Christos. 부가가치세 감사 사례 선정을 위한 게이트 혼합 변분 오토인코더
[^249]: Czech, Tomasz. 딥 러닝: 자금 세탁 탐지의 차세대 프론티어. (2018년 6월 28일)
[^250]: Nuñez, Michael. 구글 딥마인드의 소재 AI, 이미 220만 개의 새로운 결정 구조 발견. (2023-11-29)
[^251]: Merchant, Amil. 소재 발견을 위한 딥 러닝 확장. (2023년 12월)
[^252]: Peplow, Mark. 구글 AI와 로봇, 새로운 소재 제작을 위해 협력. (2023-11-29)
[^253]: Raissi, M.. 물리 정보 기반 신경망: 비선형 편미분 방정식을 포함하는 순방향 및 역방향 문제를 풀기 위한 딥 러닝 프레임워크. (2019-02-01)
[^254]: Mao, Zhiping. 고속 유동을 위한 물리 정보 기반 신경망. (2020-03-01)
[^255]: Raissi, Maziar. 숨겨진 유체 역학: 유동 가시화에서 속도장과 압력장 학습. (2020-02-28)
[^256]: Huang, Yunfei and Greenberg, David S. "[https://arxiv.org/pdf/2506.05513 기하학적 및 물리적 제약 조건이 신경 PDE 대리 모델을 시너지적으로 향상시킨다]." 제42회 국제 confe
[^257]: Oktem, Figen S.. 회절 렌즈와 학습된 재구성을 이용한 고해상도 다중 스펙트럼 이미징. (2021)
[^258]: Bernhardt, Melanie. 다중 도메인 시뮬레이션을 이용한 변분 네트워크 훈련: 음속 이미지 재구성. (2020년 12월)
[^259]: Lam, Remi. 능숙한 중기 범위 전지구 기상 예측 학습. (2023-12-22)
[^260]: Sivakumar, Ramakrishnan. GraphCast: 기상 예측의 돌파구. (2023-11-27)
[^261]: cite journal last1 = Galkin first1 = F. last2 = Mamoshina first2 = P. last3 = Kochetov first3 = K. last4 = Sidorenko first4 = D. last5 = Zhavoronkov first5 = A. year = 2020 tit
[^262]: Mazzoni, P.. 더 생물학적으로 타당한 신경망 학습 규칙.. (1991년 5월 15일)
[^263]: O'Reilly, Randall C.. 생물학적으로 타당한 오류 기반 학습을 위한 국소 활성화 차이 활용: 일반화된 재순환 알고리즘. (1996년 7월 1일)
[^264]: Testolin, Alberto. 확률 모델과 생성 신경망: 정상 및 손상된 신경인지 기능 모델링을 위한 통합 프레임워크를 향하여. (2016)
[^265]: Testolin, Alberto. 비지도 딥 러닝과 자연 이미지 특징의 재활용으로부터 나타나는 문자 인식. (2017년 9월)
[^266]: Buesing, Lars. 샘플링으로서의 신경 역학: 스파이킹 뉴런의 순환 네트워크에서의 확률적 계산 모델. (2011년 11월 3일)
[^267]: Cash, S.. CA1 피라미드 뉴런에 의한 흥분성 입력의 선형 합산. (1999년 2월)
[^268]: 감각 입력의 희소 코딩. (2004년 8월 1일)
[^269]: Yamins, Daniel L K. 감각 피질을 이해하기 위한 목표 지향적 딥 러닝 모델 활용. (2016년 3월)
[^270]: Zorzi, Marco. 수 감각의 기원에 대한 창발주의적 관점. (2018년 2월 19일)
[^271]: Güçlü, Umut. 심층 신경망이 복부 경로에 걸친 신경 표현의 복잡성 기울기를 밝히다. (2015년 7월 8일)
[^272]: Cite journal title = 구글 AI 알고리즘, 고대 바둑 게임 정복 journal = Nature year = 2016 doi = 10.1038/529445a last1 = Gibney first1 = Elizabeth volume = 529 issue = 7587 pages = 445–446 pmid
[^273]: (2016년 1월 28일)
[^274]: Cite web title = 구글 딥마인드 알고리즘, 딥 러닝 등을 사용하여 바둑 게임 정복 ! MIT Technology Review url = http://www.technologyreview.com/news/546066/googles-ai-masters-the-g
[^275]: Metz, Cade. A.I. 연구원들, 일론 머스크 연구소를 떠나 로봇 스타트업 설립. (2017년 11월 6일)
[^276]: 2008 제7회 IEEE 국제 발달 및 학습 컨퍼런스
[^277]: 알고리즘과 대화하라: AI가 더 빠른 학습자가 되다. (2018년 5월 16일)
[^278]: Marcus, Gary. 딥 러닝에 대한 회의론 옹호. (2018년 1월 14일)
[^279]: 인셉셔니즘: 신경망 더 깊이 들어가기. Google Research Blog. (2015년 6월 17일)
[^280]: 그렇다, 안드로이드는 전기 양을 꿈꾼다. (2015년 6월 18일)
[^281]: Takahashi, Carlos Kazunari. 검색 트렌드로 본 딥 러닝 확산: 국가별 분석. (2023-03-24)
[^282]: Nguyen, Anh. 심층 신경망은 쉽게 속는다: 인식 불가능한 이미지에 대한 높은 신뢰도 예측
[^283]: Szegedy, Christian. 신경망의 흥미로운 특성
[^284]: cite journal last1 = Zhu first1 = S.C. last2 = Mumford first2 = D. year = 2006 title = 이미지의 확률적 문법 journal = Found. Trends Comput. Graph. Vis. volume = 2 issue = 4
[^285]: Miller, G. A., and N. Chomsky. "패턴 인식". 미시간 대학교 패턴 탐지 컨퍼런스 발표 논문. 1957.
[^286]: Eisner, Jason. 재귀적 구조의 딥 러닝: 문법 유도
[^287]: 해커들, 이미 인공지능을 무기화하기 시작하다. (2017년 9월 11일)
[^288]: 해커가 AI를 속여 어리석은 실수를 하게 만드는 방법. (2018년 6월 18일)
[^289]: Gibney, Elizabeth. 가짜 영상을 발견하는 과학자
[^290]: Tubaro, Paola. 누구의 지능이 인공지능인가?. (2020)
관련 인사이트

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.

그 30분을 18년 동안 매일 반복했습니다 — 품질팀장이 본 AI Agent
18년차 품질팀장이 매일 아침 30분씩 반복하던 데이터 분석을 AI Agent가 3분 만에 해냈습니다. 챗봇과는 완전히 다른 물건 — 직접 시스템에 접근해서 데이터를 꺼내고 분석하는 AI의 현장 도입기.

ERP 20년, 나는 왜 AI를 얹기로 했나
ERP 20년차 제조IT본부장의 고백: 3,200만 행의 데이터가 잠들어 있었다. ERP를 바꾸지 않고 AI를 얹자, 일주일 걸리던 불량 분석이 수 초로 줄었다.