손실 함수
수학적 최적화와 결정 이론에서, 손실 함수 또는 비용 함수(때로는 오차 함수라고도 불림)[^1]는 사건이나 하나 이상의 변수의 값을 해당 사건과 관련된 어떤 "비용"을 직관적으로 나타내는 실수로 대응시키는 함수이다. 최적화 문제는 손실 함수를 최소화하는 것을 목표로 한다. 목적 함수는 손실 함수이거나 그 반대(특정 분야에서는 보상 함수, 이익 함수, 효용 함수, 적합도 함수 등으로 다양하게 불림)이며, 후자의 경우 최대화하는 것이 목표이다. 손실 함수는 계층 구조의 여러 수준에서 나온 항들을 포함할 수 있다.
통계학에서 손실 함수는 일반적으로 매개변수 추정에 사용되며, 해당 사건은 데이터 인스턴스에 대한 추정값과 실제값의 차이에 관한 어떤 함수이다. 라플라스 시대만큼이나 오래된 이 개념은 20세기 중반에 아브라함 발트에 의해 통계학에 재도입되었다.[^8] 예를 들어, 경제학의 맥락에서 이는 보통 경제적 비용 또는 후회를 의미한다. 분류에서는 사례의 잘못된 분류에 대한 벌칙이다. 보험계리학에서는 특히 1920년대 하랄드 크라메르의 연구 이후로 보험 맥락에서 보험료 대비 지급 보험금을 모형화하는 데 사용된다.[^9] 최적 제어에서 손실은 원하는 값을 달성하지 못한 것에 대한 벌칙이다. 금융 위험 관리에서 이 함수는 금전적 손실로 대응된다.
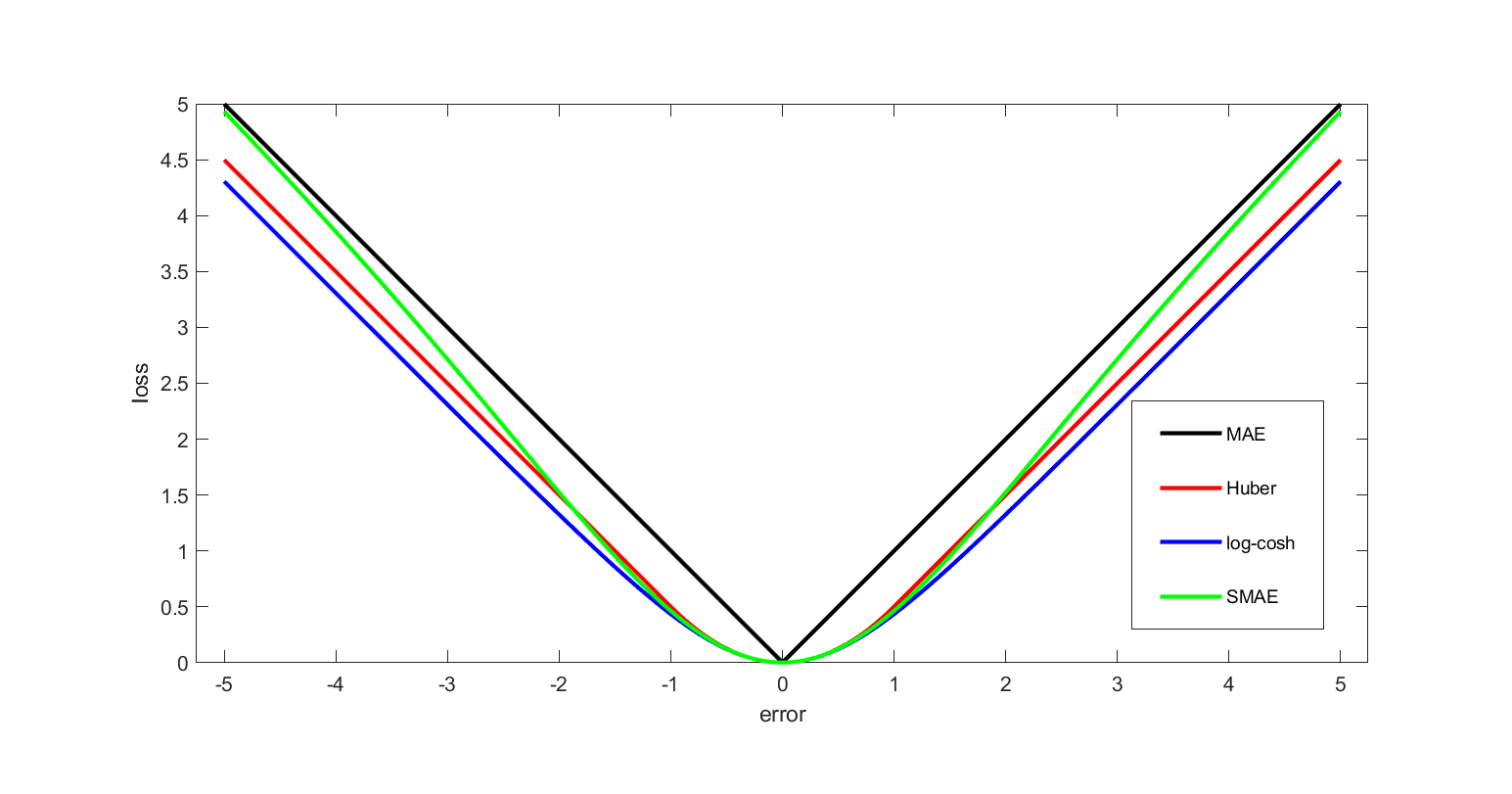 , SMAE, 후버 손실, 로그-코시 손실) 회귀에 사용됨]]
, SMAE, 후버 손실, 로그-코시 손실) 회귀에 사용됨]]
예시
후회
레너드 J. 새비지는 미니맥스와 같은 비베이즈 방법을 사용할 때, 손실 함수는 후회의 개념에 기반해야 한다고 주장했다. 즉, 어떤 결정에 따른 손실은 상황이 알려진 후에 내릴 수 있었던 최선의 결정의 결과와 상황이 알려지기 전에 실제로 내린 결정의 결과 사이의 차이여야 한다는 것이다.
이차 손실 함수
이차 손실 함수의 사용은 일반적이며, 예를 들어 최소제곱법을 사용할 때 흔히 쓰인다. 이차 손실 함수는 분산의 성질 덕분에 다른 손실 함수보다 수학적으로 다루기 쉬우며, 대칭적이기도 하다: 목표값보다 높은 오차는 목표값보다 같은 크기만큼 낮은 오차와 동일한 손실을 발생시킨다. 목표값이 t일 때, 이차 손실 함수는 다음과 같다. \lambda(x) = C (t-x)^2 ; 여기서 C는 어떤 상수이다. 이 상수의 값은 의사결정에 영향을 미치지 않으므로 1로 설정하여 무시할 수 있다. 이것은 제곱 오차 손실(SEL)이라고도 알려져 있다.[^1]
t-검정, 회귀 모형, 실험 설계 등 많은 일반적인 통계 기법은 이차 손실 함수에 기반한 선형 회귀 이론을 적용한 최소제곱법을 사용한다.
이차 손실 함수는 선형-이차 최적 제어 문제에서도 사용된다. 이러한 문제에서는 불확실성이 없더라도 모든 목표 변수의 원하는 값을 달성하는 것이 불가능할 수 있다. 흔히 손실은 관심 변수들이 원하는 값에서 벗어난 편차의 이차 형식으로 표현되며, 이 접근법은 1차 조건이 선형이 되어 다루기 쉽다. 확률적 제어의 맥락에서는 이차 형식의 기댓값이 사용된다. 이차 손실은 제곱의 특성으로 인해 실제 데이터보다 이상치에 더 큰 중요성을 부여하므로, 데이터에 큰 이상치가 많을 경우 후버, 로그-코시, SMAE 손실과 같은 대안이 사용된다.

0-1 손실 함수
통계학과 결정 이론에서 자주 사용되는 손실 함수는 0-1 손실 함수이다.
L(\hat{y}, y) = \begin{cases} 0 & \text{if } y = \hat{y} \ 1 & \text{if } y \neq \hat{y} \end{cases}
정보 이론에서 이 손실 함수는 해밍 왜곡으로 알려져 있다.
손실 함수와 목적 함수의 구성
많은 응용 분야에서 손실 함수를 특수한 경우로 포함하는 목적 함수는 문제의 정식화에 의해 결정된다. 다른 상황에서는 의사결정자의 선호를 도출하여 최적화에 적합한 형태의 스칼라 값 함수(효용 함수라고도 함)로 표현해야 하는데, 이는 라그나르 프리슈가 노벨상 수상 강연에서 강조한 문제이다.[^10] 목적 함수를 구성하기 위한 기존 방법들은 두 차례의 전문 학술대회 논문집에 수록되어 있다.[^2][^3] 특히, 안드라니크 탕기안은 가장 유용한 목적 함수인 이차 함수와 가법 함수가 소수의 무차별점에 의해 결정됨을 보였다. 그는 의사결정자들과의 컴퓨터 보조 인터뷰를 통해 도출된 서열 데이터 또는 기수 데이터로부터 이러한 목적 함수를 구성하는 모형에 이 성질을 활용하였다.[^4][^5] 그 밖에도 그는 베스트팔렌 지역 16개 대학의 예산을 최적으로 배분하기 위한 목적 함수를 구성하였으며,[^6] 271개 독일 지역 간의 실업률 균등화를 위한 유럽 보조금의 목적 함수도 구성하였다.[^7]
기대 손실
일부 맥락에서 손실 함수의 값 자체가 확률 변수 X의 결과에 의존하기 때문에 확률적 양이 된다.
통계학
빈도주의 및 베이즈 통계 이론 모두 손실 함수의 기댓값에 기반하여 의사결정을 내리는 것을 포함하지만, 이 양은 두 패러다임에서 서로 다르게 정의된다.
빈도주의 기대 손실
먼저 빈도주의 맥락에서 기대 손실을 정의한다. 이는 관측 데이터 X의 확률 분포 Pθ에 대한 기댓값을 취함으로써 얻어진다. 이를 의사결정 규칙 δ와 모수 θ의 위험 함수[^11][^12][^13][^14]라고도 한다. 여기서 의사결정 규칙은 X의 결과에 의존한다. 위험 함수는 다음과 같이 주어진다:
R(\theta, \delta) = \operatorname{E}\theta L\big( \theta, \delta(X) \big) = \int_X L\big( \theta, \delta(x) \big) , \mathrm{d} P\theta (x) .
여기서 θ는 고정되어 있지만 알려지지 않았을 수 있는 자연 상태이고, X는 모집단에서 확률적으로 추출된 관측값의 벡터이며, \operatorname{E}_\theta는 X의 모든 모집단 값에 대한 기댓값이고, dPθ는 X의 사건 공간에 대한 확률 측도(θ로 매개변수화됨)이며, 적분은 X의 전체 지지(support)에 대해 평가된다.
베이즈 위험
베이즈 접근법에서는 모수 θ의 사전 분포 *를 사용하여 기댓값을 계산한다:
\rho(\pi^,a) = \int_\Theta \int _{\bold X} L(\theta, a(\bold x)) , \mathrm{d} P(\bold x \vert \theta) ,\mathrm{d} \pi^ (\theta)= \int_{\bold X} \int_\Theta L(\theta,a(\bold x)),\mathrm{d} \pi^*(\theta\vert \bold x),\mathrm{d}M(\bold x)
여기서 m(x)는 θ가 "적분으로 제거된" 예측 우도로 알려져 있고, * (θ | x)는 사후 분포이며, 적분의 순서가 변경되었다. 그런 다음 이 기대 손실을 최소화하는 행동 a*를 선택해야 하며, 이를 베이즈 위험이라 한다. 후자의 식에서 dx 내부의 피적분 함수는 사후 위험으로 알려져 있으며, 의사결정 a에 대해 이를 최소화하면 전체 베이즈 위험도 최소화된다. 이 최적 의사결정 a*는 베이즈 (의사결정) 규칙으로 알려져 있으며, 모든 가능한 자연 상태 θ에 걸쳐, 모든 가능한 (확률 가중) 데이터 결과에 걸쳐 평균 손실을 최소화한다. 베이즈 접근법의 한 가지 장점은 균일하게 최적인 의사결정을 얻기 위해 실제 관측된 데이터에서만 최적 행동을 선택하면 된다는 것인 반면, 모든 가능한 관측값의 함수로서 실제 빈도주의 최적 의사결정 규칙을 선택하는 것은 훨씬 더 어려운 문제이다. 그러나 동등하게 중요한 것은, 베이즈 규칙이 서로 다른 자연 상태 θ에서의 손실 결과를 고려한다는 점이다.
통계학에서의 예시
- 스칼라 모수 θ, 출력 \hat\theta가 θ의 추정량인 의사결정 함수, 그리고 이차 손실 함수(제곱 오차 손실) L(\theta,\hat\theta)=(\theta-\hat\theta)^2, 에 대해, 위험 함수는 추정량의 평균 제곱 오차가 된다. R(\theta,\hat\theta)= \operatorname{E}_\theta \left [ (\theta-\hat\theta)^2 \right ].평균 제곱 오차를 최소화하여 구한 추정량은 사후 분포의 평균을 추정한다.
- 밀도 추정에서 미지의 모수는 확률 밀도 자체이다. 손실 함수는 일반적으로 적절한 함수 공간에서의 노름으로 선택된다. 예를 들어, L2 노름의 경우, L(f,\hat f) = |f-\hat f|_2^2,, 위험 함수는 평균 적분 제곱 오차가 된다. R(f,\hat f)=\operatorname{E} \left ( |f-\hat f|^2 \right ).,
불확실성 하의 경제적 선택
경제학에서 불확실성 하의 의사결정은 흔히 기말 부(wealth)와 같은 불확실한 관심 변수의 폰 노이만-모르겐슈테른 효용 함수를 사용하여 모형화된다. 이 변수의 값이 불확실하므로 효용 함수의 값도 불확실하며, 최대화되는 것은 효용의 기댓값이다.
결정 규칙
결정 규칙은 최적성 기준을 사용하여 선택을 내린다. 일반적으로 사용되는 기준은 다음과 같다:
*** 미니맥스**: 최악의 손실이 가장 낮은 결정 규칙을 선택한다 — 즉, 최악의 경우(가능한 최대) 손실을 최소화한다: \underset{\delta} {\operatorname{arg,min}} \ \max_{\theta \in \Theta} \ R(\theta,\delta). *** 불변성**: 불변성 요건을 충족하는 결정 규칙을 선택한다. *평균 손실이 가장 낮은 결정 규칙을 선택한다 (즉, 손실 함수의 기댓값을 최소화한다): \underset{\delta} {\operatorname{arg,min}} \operatorname{E}{\theta \in \Theta} [R(\theta,\delta)] = \underset{\delta} {\operatorname{arg,min}} \ \int{\theta \in \Theta} R(\theta,\delta) , p(\theta) ,d\theta.
손실 함수 선택
건전한 통계적 실천을 위해서는 특정 응용 문제의 맥락에서 실제로 경험하게 되는 허용 가능한 변동에 부합하는 추정량을 선택해야 한다. 따라서 손실 함수의 응용에서, 어떤 통계적 방법을 사용하여 응용 문제를 모형화할지 선택하는 것은 해당 문제의 특정 상황에서 오류로 인해 발생하는 손실이 무엇인지 아는 것에 달려 있다.[^15]
흔한 예로 "위치"의 추정이 있다. 일반적인 통계적 가정하에서, 평균은 제곱 오차 손실 함수에서 기대 손실을 최소화하는 위치 추정 통계량이며, 중앙값은 절대 차이 손실 함수에서 기대 손실을 최소화하는 추정량이다. 그 밖의 덜 일반적인 상황에서는 또 다른 추정량이 최적이 될 수 있다.
경제학에서 행위자가 위험 중립적일 때, 목적 함수는 이윤, 소득, 또는 기말 자산과 같은 화폐적 양의 기대값으로 간단히 표현된다. 위험 회피적이거나 위험 선호적인 행위자의 경우, 손실은 효용 함수의 음수로 측정되며, 최적화할 목적 함수는 효용의 기대값이 된다.
그 밖에도 공중 보건이나 안전 공학 분야에서의 사망률이나 이환율 등 다른 비용 척도도 가능하다.
대부분의 최적화 알고리즘에서는 손실 함수가 전역적으로 연속이고 미분 가능한 것이 바람직하다.
매우 흔히 사용되는 두 가지 손실 함수는 제곱 손실 L(a) = a^2과 절대 손실 L(a)=|a|이다. 그러나 절대 손실은 a=0에서 미분 불가능하다는 단점이 있다. 제곱 손실은 이상치에 의해 지배되는 경향이 있다는 단점이 있다—a들의 집합에 대해 합산할 때(\sum_{i=1}^n L(a_i) 에서와 같이), 최종 합은 평균적인 a 값의 표현이라기보다 특별히 큰 몇몇 a 값의 결과가 되는 경향이 있다.
손실 함수의 선택은 자의적이지 않다. 이는 매우 제한적이며 때로는 손실 함수가 바람직한 성질에 의해 특성화될 수 있다.[^16] 선택 원칙 중에는 예를 들어 독립 동일 분포 관측의 경우 대칭 통계량 부류의 완비성 요건, 완전 정보 원칙 등이 있다.
W. Edwards Deming과 Nassim Nicholas Taleb은 훌륭한 수학적 성질이 아니라 경험적 현실이 손실 함수를 선택하는 유일한 근거가 되어야 한다고 주장하며, 실제 손실은 수학적으로 깔끔하지 않은 경우가 많고 미분 불가능하거나, 불연속이거나, 비대칭인 경우 등이 있다고 말한다. 예를 들어, 비행기 탑승구가 닫히기 전에 도착한 사람은 여전히 탑승할 수 있지만, 닫힌 후에 도착한 사람은 탑승할 수 없으며, 이러한 불연속성과 비대칭성으로 인해 약간 늦게 도착하는 것이 약간 일찍 도착하는 것보다 훨씬 더 큰 비용을 초래한다. 약물 투여에서 약물이 너무 적으면 효능 부족이 문제가 될 수 있고, 너무 많으면 허용 가능한 독성이 문제가 될 수 있는데, 이 또한 비대칭의 예이다. 교통, 배관, 보, 생태계, 기후 등은 어느 지점까지는 증가된 부하나 스트레스를 거의 눈에 띄는 변화 없이 견딜 수 있지만, 그 지점을 넘으면 정체되거나 재앙적으로 붕괴된다. Deming과 Taleb은 이러한 상황이 실생활 문제에서 흔하며, 아마도 고전적인 매끄럽고 연속적이며 대칭적인 미분 가능 사례보다 더 흔할 것이라고 주장한다.[^17]
같이 보기
*베이즈 후회 *분류를 위한 손실 함수 *할인된 최대 손실 *힌지 손실 *채점 규칙 *통계적 위험
더 읽을거리
참고 문헌
[^1]: Hastie, Trevor. 통계 학습의 기초. Springer
[^2]: Tangian, Andranik. 스칼라 값 목적 함수의 구성. 제3회 계량경제학적 의사결정 모형 국제 학술대회 논문집: 스칼라 값 목적 함수의 구성, 하겐 대학교, 슈베르테 가톨릭 아카데미에서 1995년 9월 5–8일 개최. Springer. (1997)
[^3]: Tangian, Andranik. 목적 함수의 구성과 적용. 제4회 계량경제학적 의사결정 모형 국제 학술대회 논문집: 목적 함수의 구성과 적용, 하겐 대학교, 노르트헬레 하우스에서 2000년 8월 28–31일 개최. Springer. (2002)
[^4]: Tangian, Andranik. 의사결정자 면접을 통한 준오목 이차 목적 함수의 구성
[^5]: Tangian, Andranik. 가법적 목적 함수의 순서적 구성 모형
[^6]: Tangian, Andranik. 현상 유지를 고려한 대학 예산의 재분배
[^7]: Tangian, Andranik. 지역 고용 정책의 다기준 최적화: 독일에 대한 시뮬레이션 분석
[^8]: Wald, A.. 통계적 결정 함수. Wiley
[^9]: Cramér, H.. 위험의 수학적 이론에 관하여. Centraltryckeriet
[^10]: Frisch. 노벨상 수상 강연. (1969)
[^11]: Nikulin, M.S.
[^12]: Berger, James O.. 통계적 결정 이론과 베이즈 분석. Springer-Verlag
[^13]: DeGroot, Morris. 최적 통계적 결정. Wiley Classics Library
[^14]: Robert, Christian P.. 베이즈적 선택. Springer
[^15]: Pfanzagl, J.. 모수적 통계 이론. Walter de Gruyter
[^16]: Klebanov, B.. 통계학에서의 로버스트 모형과 비로버스트 모형. Nova Scientific Publishers, Inc.
[^17]: Deming, W. Edwards. 위기에서 벗어나기. The MIT Press
관련 인사이트

로봇은 왜 볼트를 떨어뜨리는가 — Physical AI가 공장에 필요한 진짜 이유
AI가 데이터 패턴만 외우는 시대는 끝나고 있다. 물리 법칙을 이해하는 Physical AI가 제조 현장에 왜 필요한지, KAIST 교수와 자동차 부품 공장 팀장이 볼트 하나를 놓고 이야기한다.

디지털 트윈, 당신 공장엔 이미 있다 — 엑셀과 MES 사이 어딘가에
디지털 트윈은 10억짜리 3D 시뮬레이션이 아니다. 지금 쓰고 있는 엑셀에 좋은 질문 하나를 더하는 것 — 두 전문가가 중소 제조기업이 이미 가진 데이터로 예측하는 공장을 만드는 현실적 로드맵을 제시한다.

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.