서포트 벡터 머신
머신 러닝에서 서포트 벡터 머신(SVM, 서포트 벡터 네트워크라고도 함[^3])은 분류 및 회귀 분석을 위해 데이터를 분석하는 관련 학습 알고리즘을 갖춘 지도 학습 기반의 최대 마진 모델이다. AT&T 벨 연구소에서 개발된[^3][^6] SVM은 Vapnik(1982, 1995)과 Chervonenkis(1974)가 제안한 VC 이론의 통계적 학습 프레임워크에 기반하여 가장 많이 연구된 모델 중 하나이다.
SVM은 선형 분류를 수행하는 것 외에도 커널 트릭을 사용하여 비선형 분류를 효율적으로 수행할 수 있는데, 이는 커널 함수를 이용하여 원래 데이터 포인트 간의 쌍별 유사도 비교 집합만으로 데이터를 표현하고, 이를 더 높은 차원의 특징 공간에서의 좌표로 변환하는 방식이다. 따라서 SVM은 커널 트릭을 사용하여 입력을 암묵적으로 고차원 특징 공간에 매핑하며, 그곳에서 선형 분류를 수행할 수 있다.[^7] 최대 마진 모델인 SVM은 잡음이 있는 데이터(예: 잘못 분류된 사례)에 대해 강건하다. SVM은 회귀 작업에도 사용될 수 있으며, 이 경우 목적 함수는 \epsilon-민감 방식이 된다.
Hava Siegelmann과 Vladimir Vapnik이 만든 서포트 벡터 클러스터링[^1] 알고리즘은 서포트 벡터 머신 알고리즘에서 개발된 서포트 벡터의 통계적 기법을 레이블이 없는 데이터의 범주화에 적용한 것이다. 이러한 데이터셋은 비지도 학습 접근법을 필요로 하며, 이 접근법은 데이터의 자연스러운 군집을 찾아 그룹으로 분류한 후 새로운 데이터를 이러한 군집에 따라 매핑하는 것을 목표로 한다.
SVM의 인기는 이론적 분석에 대한 적합성과 구조화된 예측 문제를 포함한 다양한 작업에 유연하게 적용될 수 있다는 점에 기인하는 것으로 보인다. SVM이 로지스틱 회귀나 선형 회귀와 같은 다른 선형 모델보다 더 나은 예측 성능을 갖는지는 명확하지 않다.[^8]
동기
.svg)
데이터 분류는 기계 학습에서 흔한 작업이다. 주어진 데이터 포인트들이 각각 두 클래스 중 하나에 속한다고 가정하고, 새로운 데이터 포인트가 어느 클래스에 속할지를 결정하는 것이 목표이다. 서포트 벡터 머신의 경우, 데이터 포인트는 p차원 벡터(p개의 숫자로 이루어진 목록)로 간주되며, 이러한 점들을 (p-1)차원 초평면으로 분리할 수 있는지를 알고자 한다. 이를 선형 분류기라고 한다. 데이터를 분류할 수 있는 초평면은 많이 존재한다. 최적의 초평면으로 합리적인 선택은 두 클래스 사이의 가장 큰 분리, 즉 마진을 나타내는 것이다. 따라서 초평면에서 각 쪽의 가장 가까운 데이터 포인트까지의 거리가 최대화되도록 초평면을 선택한다. 이러한 초평면이 존재하면, 이를 최대 마진 초평면이라 하고, 이것이 정의하는 선형 분류기를 최대 마진 분류기, 또는 동등하게 최적 안정성의 퍼셉트론이라고 한다.[^9]
더 형식적으로 말하면, 서포트 벡터 머신은 고차원 또는 무한 차원 공간에서 하나의 초평면 또는 초평면의 집합을 구성하며, 이는 분류, 회귀, 또는 이상치 탐지와 같은 기타 작업에 사용될 수 있다.[^10] 직관적으로, 어떤 클래스의 가장 가까운 훈련 데이터 포인트까지의 거리(이른바 함수적 마진)가 가장 큰 초평면에 의해 좋은 분리가 달성되는데, 일반적으로 마진이 클수록 분류기의 일반화 오차가 낮아지기 때문이다.[^11] 일반화 오차가 낮다는 것은 구현자가 과적합을 경험할 가능성이 낮다는 것을 의미한다.
원래 문제가 유한 차원 공간에서 정의될 수 있지만, 해당 공간에서 구별할 집합들이 선형적으로 분리 가능하지 않은 경우가 종종 발생한다. 이러한 이유로, 원래의 유한 차원 공간을 훨씬 더 고차원의 공간으로 매핑하여 해당 공간에서 분리를 더 쉽게 만드는 방법이 제안되었다.[^2] 계산 부하를 합리적으로 유지하기 위해, SVM 방식에서 사용되는 매핑은 입력 데이터 벡터 쌍의 내적이 원래 공간의 변수로 쉽게 계산될 수 있도록 설계되며, 이는 문제에 적합하도록 선택된 커널 함수 k(x, y)로 정의된다.[^12] 고차원 공간에서의 초평면은 해당 공간의 벡터와의 내적이 상수인 점들의 집합으로 정의되며, 이러한 벡터의 집합은 초평면을 정의하는 직교(따라서 최소) 벡터 집합이다. 초평면을 정의하는 벡터는 데이터베이스에 존재하는 특징 벡터 x_i의 이미지에 매개변수 \alpha_i를 사용한 선형 결합으로 선택할 수 있다. 이러한 초평면 선택에 따라, 초평면으로 매핑되는 특징 공간의 점 x는 관계식 \textstyle\sum_i \alpha_i k(x_i, x) = \text{constant}.로 정의된다. k(x, y)가 y가 x에서 멀어질수록 작아지면, 합의 각 항은 테스트 포인트 x가 대응하는 데이터베이스 포인트 x_i에 얼마나 가까운지를 측정한다는 점에 유의하라. 이러한 방식으로, 위의 커널 합은 각 테스트 포인트가 구별할 두 집합 중 하나에서 유래한 데이터 포인트들에 대한 상대적 근접도를 측정하는 데 사용될 수 있다. 임의의 초평면으로 매핑되는 점 x의 집합은 그 결과로 상당히 복잡한 형태가 될 수 있어, 원래 공간에서 전혀 볼록하지 않은 집합들 사이에서도 훨씬 더 복잡한 구별이 가능해진다는 사실에 주목하라.
응용 분야
SVM은 다양한 실제 문제를 해결하는 데 사용될 수 있다:
- SVM은 텍스트 및 하이퍼텍스트 분류에 유용하며, 이를 적용하면 표준 귀납적 설정과 변환적 설정 모두에서 레이블이 지정된 훈련 인스턴스의 필요성을 크게 줄일 수 있다.[^13] 일부 얕은 의미 분석 방법은 서포트 벡터 머신에 기반한다.[^14]
- 이미지 분류도 SVM을 사용하여 수행할 수 있다. 실험 결과에 따르면, SVM은 단 세 번에서 네 번의 관련성 피드백만으로 기존의 질의 정제 방식보다 훨씬 높은 검색 정확도를 달성한다. 이는 Vapnik이 제안한 특권 접근 방식을 사용하는 수정된 버전의 SVM을 포함한 이미지 분할 시스템에서도 마찬가지이다.[^15][^16]
- SAR 데이터와 같은 위성 데이터의 분류에 지도 학습 SVM이 사용된다.[^17]
- 손글씨 문자 인식에 SVM이 사용될 수 있다.[^18][^19]
- SVM 알고리즘은 생물학 및 기타 과학 분야에서 널리 적용되어 왔다. 단백질 분류에 사용되어 최대 90%의 화합물이 정확하게 분류되었다. SVM 가중치에 기반한 순열 검정이 SVM 모델 해석을 위한 메커니즘으로 제안되었다.[^20][^21] 서포트 벡터 머신 가중치는 과거에도 SVM 모델을 해석하는 데 사용되어 왔다.[^22] 모델이 예측에 사용하는 특징을 식별하기 위한 서포트 벡터 머신 모델의 사후 해석은 비교적 새로운 연구 분야로, 특히 생물학 분야에서 중요한 의미를 가진다.
역사
최초의 SVM 알고리즘은 1964년 Vladimir N. Vapnik과 Alexey Ya. Chervonenkis에 의해 발명되었다. 1992년에 Bernhard Boser, Isabelle Guyon, Vladimir Vapnik은 최대 마진 초평면에 커널 트릭을 적용하여 비선형 분류기를 만드는 방법을 제안하였다.[^2] 소프트웨어 패키지에서 일반적으로 사용되는 "소프트 마진" 구현은 1993년에 Corinna Cortes와 Vapnik이 제안하였으며, 1995년에 출판되었다.[^3]
선형 SVM
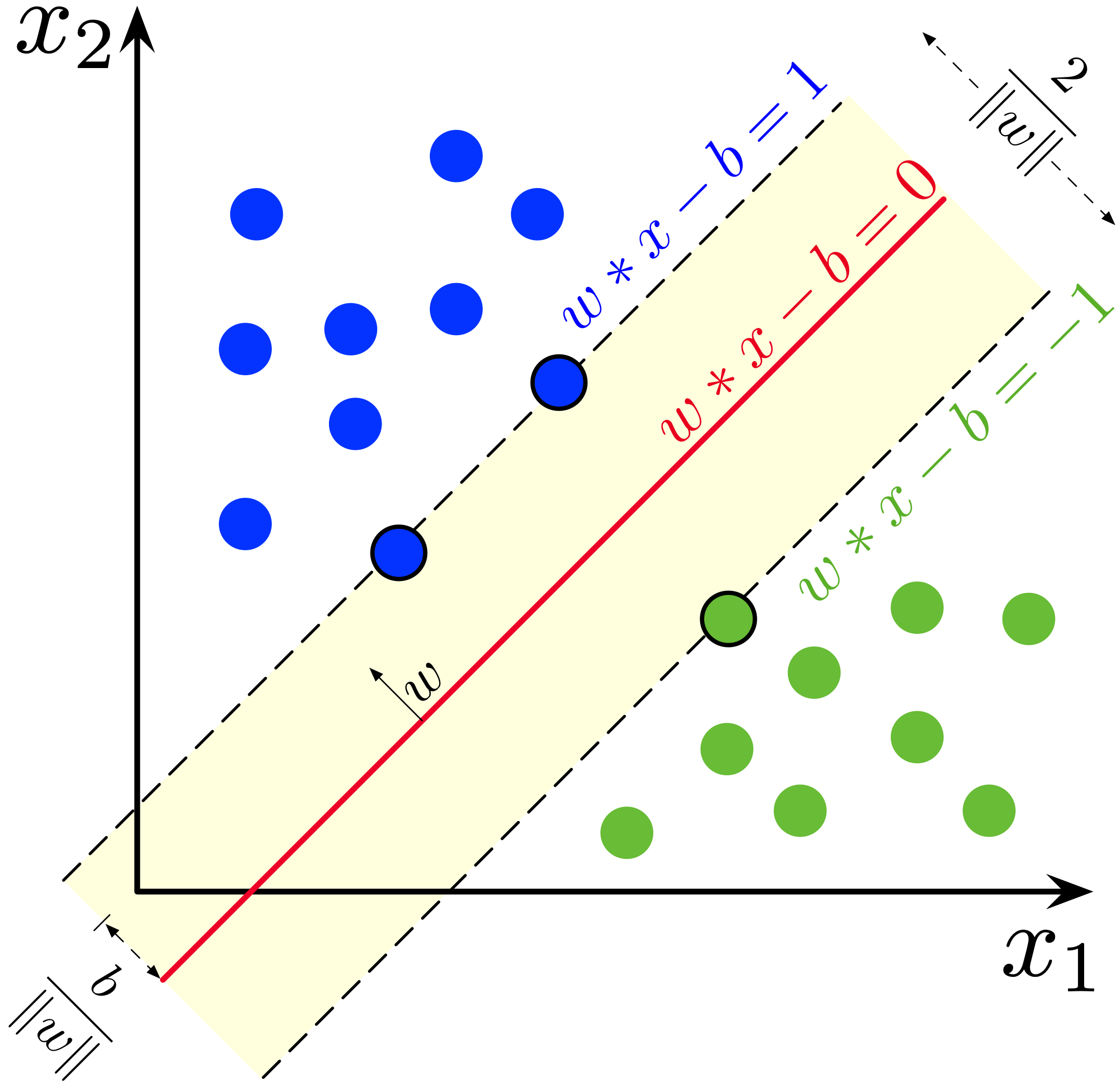
n개의 점으로 구성된 훈련 데이터셋이 다음과 같은 형태로 주어진다. (\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n), 여기서 y_i는 1 또는 −1의 값을 가지며, 각각은 점 \mathbf{x}_i 가 속하는 클래스를 나타낸다. 각 \mathbf{x}_i 는 p차원 실수 벡터이다. 우리는 y_i = 1인 점 \mathbf{x}_i의 그룹과 y_i = -1인 점의 그룹을 나누는 "최대 마진 초평면"을 찾고자 하며, 이는 초평면과 양쪽 그룹에서 가장 가까운 점 \mathbf{x}_i 사이의 거리가 최대가 되도록 정의된다.
임의의 초평면은 다음을 만족하는 점 \mathbf{x}의 집합으로 표현할 수 있다. \mathbf{w}^\mathsf{T} \mathbf{x} - b = 0, 여기서 \mathbf{w}는 초평면에 대한 (반드시 정규화될 필요는 없는) 법선 벡터이다. 이는 헤세 정규형과 매우 유사하나, \mathbf{w}가 반드시 단위 벡터일 필요는 없다는 점이 다르다. 매개변수 \tfrac{b}{|\mathbf{w}|}는 법선 벡터 \mathbf{w} 방향을 따른 원점으로부터의 초평면의 오프셋을 결정한다.
주의: 이 주제에 관한 대부분의 문헌에서는 편향을 다음과 같이 정의한다. \mathbf{w}^\mathsf{T} \mathbf{x} + b = 0.
하드 마진
훈련 데이터가 선형 분리 가능한 경우, 두 클래스의 데이터를 분리하는 두 개의 평행한 초평면을 선택하여 그 사이의 거리가 가능한 한 크도록 할 수 있다. 이 두 초평면 사이의 영역을 "마진"이라 하며, 최대 마진 초평면은 그 중간에 위치하는 초평면이다. 정규화 또는 표준화된 데이터셋에서 이러한 초평면은 다음 방정식으로 표현할 수 있다. \mathbf{w}^\mathsf{T} \mathbf{x} - b = 1 (이 경계 위 또는 그 이상에 있는 모든 것은 레이블 1인 한 클래스에 속함) 그리고 \mathbf{w}^\mathsf{T} \mathbf{x} - b = -1 (이 경계 아래 또는 그 이하에 있는 모든 것은 레이블 −1인 다른 클래스에 속함). 기하학적으로, 이 두 초평면 사이의 거리는 \tfrac{2}{|\mathbf{w}|}이므로,[^23] 평면 간 거리를 최대화하려면 |\mathbf{w}|를 최소화해야 한다. 이 거리는 점에서 평면까지의 거리 공식을 사용하여 계산된다. 또한 데이터 포인트가 마진 안으로 들어오는 것을 방지하기 위해 다음 제약 조건을 추가한다: 각 i에 대해 \mathbf{w}^\mathsf{T} \mathbf{x}_i - b \ge 1 , , \text{ if } y_i = 1, 또는 \mathbf{w}^\mathsf{T} \mathbf{x}_i - b \le -1 , , \text{ if } y_i = -1. 이 제약 조건은 각 데이터 포인트가 마진의 올바른 쪽에 위치해야 함을 명시한다.
이는 다음과 같이 다시 쓸 수 있다.
이를 종합하면 다음과 같은 최적화 문제를 얻을 수 있다:
\begin{align} &\underset{\mathbf{w},;b}{\operatorname{minimize}} && \frac{1}{2}|\mathbf{w}|^2\ &\text{subject to} && y_i(\mathbf{w}^\top \mathbf{x}_i - b) \geq 1 \quad \forall i \in {1,\dots,n} \end{align}
이 문제를 풀어 얻은 \mathbf{w}와 b가 최종 분류기 \mathbf{x} \mapsto \sgn(\mathbf{w}^\mathsf{T} \mathbf{x} - b)를 결정하며, 여기서 \sgn(\cdot)는 부호 함수이다.
이 기하학적 설명의 중요한 귀결은 최대 마진 초평면이 그에 가장 가까이 위치하는 \mathbf{x}_i에 의해 완전히 결정된다는 것이다(아래에서 설명). 이러한 \mathbf{x}_i를 서포트 벡터라 한다.
소프트 마진
데이터가 선형 분리 불가능한 경우에도 SVM을 확장하기 위해 힌지 손실 함수가 유용하다. \max\left(0, 1 - y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b)\right).
여기서 y_i는 i번째 목푯값(즉, 이 경우 1 또는 −1)이고, \mathbf{w}^\mathsf{T} \mathbf{x}_i - b는 i번째 출력값이다.
이 함수는 제약 조건이 만족되면 0의 값을 가진다. 즉, \mathbf{x}_i가 마진의 올바른 쪽에 위치하면 0이다. 마진의 잘못된 쪽에 있는 데이터의 경우, 함수의 값은 마진으로부터의 거리에 비례한다.
최적화의 목표는 다음을 최소화하는 것이다:
\lVert \mathbf{w} \rVert^2 + C \left[\frac 1 n \sum_{i=1}^n \max\left(0, 1 - y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b)\right) \right],
여기서 매개변수 C > 0는 마진 크기의 증가와 \mathbf{x}_i가 마진의 올바른 쪽에 위치하도록 보장하는 것 사이의 트레이드오프를 결정한다(위 방정식의 어느 항에나 가중치를 추가할 수 있다). 힌지 손실을 분해하면 이 최적화 문제를 다음과 같이 정식화할 수 있다:
\begin{align} &\underset{\mathbf{w},;b,;\mathbf{\zeta}}{\operatorname{minimize}} &&|\mathbf{w}|2^2 + C\sum{i=1}^n \zeta_i\ &\text{subject to} && y_i(\mathbf{w}^\top \mathbf{x}_i - b) \geq 1 - \zeta_i, \quad \zeta_i \geq 0 \quad \forall i\in {1,\dots,n} \end{align}
따라서 C의 값이 큰 경우, 입력 데이터가 선형 분류 가능하면 하드 마진 SVM과 유사하게 동작하지만, 분류 규칙이 실현 가능한지 여부는 여전히 학습할 수 있다.
비선형 커널

1963년 Vapnik이 제안한 최초의 최대 마진 초평면 알고리즘은 선형 분류기를 구성하였다. 그러나 1992년에 Bernhard Boser, Isabelle Guyon, Vladimir Vapnik은 커널 트릭(원래 Aizerman 등이 제안[^24])을 최대 마진 초평면에 적용하여 비선형 분류기를 만드는 방법을 제안하였다.[^2] 내적을 커널로 대체하는 커널 트릭은 SVM 문제의 쌍대 표현에서 쉽게 유도된다. 이를 통해 알고리즘은 변환된 특징 공간에서 최대 마진 초평면을 적합할 수 있다. 변환은 비선형일 수 있으며 변환된 공간은 고차원일 수 있다. 변환된 특징 공간에서 분류기는 초평면이지만, 원래 입력 공간에서는 비선형일 수 있다.
주목할 점은 더 높은 차원의 특징 공간에서 작업하면 서포트 벡터 머신의 일반화 오류가 증가하지만, 충분한 표본이 주어지면 알고리즘은 여전히 잘 작동한다는 것이다.[^25]
일반적으로 사용되는 커널에는 다음이 있다:
- 다항식 (동차): k(\mathbf{x}_i, \mathbf{x}_j) = (\mathbf{x}_i \cdot \mathbf{x}_j)^d. 특히 d = 1일 때, 이는 선형 커널이 된다.
- 다항식 (비동차): k(\mathbf{x}_i, \mathbf{x}_j) = (\mathbf{x}_i \cdot \mathbf{x}_j + r)^d.
- 가우시안 방사 기저 함수: k(\mathbf{x}_i, \mathbf{x}_j) = \exp\left(-\gamma \left|\mathbf{x}_i - \mathbf{x}_j\right|^2\right), \gamma > 0. 때때로 \gamma = 1/(2\sigma^2)를 사용하여 매개변수화한다.
- 시그모이드 함수 (쌍곡탄젠트): k(\mathbf{x_i}, \mathbf{x_j}) = \tanh(\kappa \mathbf{x}_i \cdot \mathbf{x}_j + c), 일부 (모든 것은 아닌) \kappa > 0 및 c < 0에 대해 성립한다.
커널은 k(\mathbf{x}_i, \mathbf{x}_j) = \varphi(\mathbf{x}_i) \cdot \varphi(\mathbf{x}_j) 방정식에 의해 변환 \varphi(\mathbf{x}_i)와 관련된다. 값은 변환된 공간에서도 마찬가지로 \mathbf{w} = \sum_i \alpha_i y_i \varphi(\mathbf{x}_i)이다. 분류를 위한 내적은 다시 커널 트릭으로 계산할 수 있다. 즉, \mathbf{w} \cdot \varphi(\mathbf{x}) = \sum_i \alpha_i y_i k(\mathbf{x}_i, \mathbf{x})이다.
SVM 분류기 계산
(소프트 마진) SVM 분류기를 계산하는 것은 다음과 같은 형태의 표현식을 최소화하는 것에 해당한다.
위에서 언급한 바와 같이 \lambda에 대해 충분히 작은 값을 선택하면 선형 분류 가능한 입력 데이터에 대해 하드 마진 분류기가 산출되므로, 여기서는 소프트 마진 분류기에 초점을 맞춘다. 이차 계획법 문제로 환원하는 고전적인 접근법을 아래에서 자세히 설명한다. 이후 준경사 하강법과 좌표 하강법과 같은 보다 최근의 접근법을 논의할 것이다.
원시 문제
를 최소화하는 것은 다음과 같이 미분 가능한 목적 함수를 가진 제약 조건부 최적화 문제로 다시 쓸 수 있다.
각 i \in {1,,\ldots,,n}에 대해 변수 \zeta_i = \max\left(0, 1 - y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b)\right)를 도입한다. \zeta_i는 y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b) \geq 1 - \zeta_i를 만족하는 가장 작은 음이 아닌 수임에 유의하라.
따라서 최적화 문제를 다음과 같이 다시 쓸 수 있다.
\begin{align} &\text{minimize } \frac 1 n \sum_{i=1}^n \zeta_i + \lambda |\mathbf{w}|^2 \[0.5ex] &\text{subject to } y_i\left(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b\right) \geq 1 - \zeta_i , \text{ and } , \zeta_i \geq 0,, \text{for all } i. \end{align}
이것을 원시 문제라고 한다.
쌍대 문제
위 문제의 라그랑주 쌍대를 풀면 다음과 같은 단순화된 문제를 얻는다.
\begin{align} &\text{maximize},, f(c_1 \ldots c_n) = \sum_{i=1}^n c_i - \frac 1 2 \sum_{i=1}^n\sum_{j=1}^n y_i c_i(\mathbf{x}_i^\mathsf{T} \mathbf{x}j)y_j c_j, \ &\text{subject to } \sum{i=1}^n c_iy_i = 0,,\text{and } 0 \leq c_i \leq \frac{1}{2n\lambda};\text{for all }i. \end{align}
이것을 쌍대 문제라고 한다. 쌍대 최대화 문제는 선형 제약 조건 하에서 c_i의 이차 함수이므로, 이차 계획법 알고리즘으로 효율적으로 풀 수 있다.
여기서 변수 c_i는 다음과 같이 정의된다.
\mathbf{w} = \sum_{i=1}^n c_iy_i \mathbf{x}_i.
또한, c_i = 0인 경우는 정확히 \mathbf{x}_i가 마진의 올바른 쪽에 있을 때이고, 0 < c_i <(2n\lambda)^{-1}인 경우는 \mathbf{x}_i가 마진의 경계 위에 있을 때이다. 따라서 \mathbf{w}는 서포트 벡터들의 선형 결합으로 쓸 수 있다.
오프셋 b는 마진의 경계 위에 있는 \mathbf{x}_i를 찾아 다음을 풀어서 복원할 수 있다. y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b) = 1 \iff b = \mathbf{w}^\mathsf{T} \mathbf{x}_i - y_i .
(y_i=\pm 1이므로 y_i^{-1}=y_i임에 유의하라.)
커널 트릭

이제 변환된 데이터 포인트 \varphi(\mathbf{x}_i)에 대한 선형 분류 규칙에 대응하는 비선형 분류 규칙을 학습하고자 한다고 가정하자. 또한, k(\mathbf{x}_i, \mathbf{x}_j) = \varphi(\mathbf{x}_i) \cdot \varphi(\mathbf{x}_j)를 만족하는 커널 함수 k가 주어져 있다고 하자.
변환된 공간에서의 분류 벡터 \mathbf{w}가 다음을 만족함을 알고 있다.
\mathbf{w} = \sum_{i=1}^n c_iy_i\varphi(\mathbf{x}_i),
여기서 c_i는 다음 최적화 문제를 풀어서 얻는다.
\begin{align} \text{maximize},, f(c_1 \ldots c_n) &= \sum_{i=1}^n c_i - \frac 1 2 \sum_{i=1}^n\sum_{j=1}^n y_ic_i(\varphi(\mathbf{x}i) \cdot \varphi(\mathbf{x}j))y_jc_j \ &= \sum{i=1}^n c_i - \frac 1 2 \sum{i=1}^n\sum_{j=1}^n y_ic_ik(\mathbf{x}_i, \mathbf{x}j)y_jc_j \ \text{subject to } \sum{i=1}^n c_i y_i &= 0,,\text{and } 0 \leq c_i \leq \frac{1}{2n\lambda};\text{for all }i. \end{align}
계수 c_i는 이전과 마찬가지로 이차 계획법을 사용하여 풀 수 있다. 다시, 0 < c_i <(2n\lambda)^{-1}인 인덱스 i를 찾을 수 있으며, 이는 \varphi(\mathbf{x}_i)가 변환된 공간에서 마진의 경계 위에 있음을 의미하고, 다음을 풀 수 있다.
\begin{align} b = \mathbf{w}^\mathsf{T} \varphi(\mathbf{x}i) - y_i &= \left[\sum{j=1}^n c_jy_j\varphi(\mathbf{x}_j) \cdot \varphi(\mathbf{x}i)\right] - y_i \ &= \left[\sum{j=1}^n c_jy_jk(\mathbf{x}_j, \mathbf{x}_i)\right] - y_i. \end{align}
최종적으로,
\mathbf{z} \mapsto \sgn(\mathbf{w}^\mathsf{T} \varphi(\mathbf{z}) - b) = \sgn \left(\left[\sum_{i=1}^n c_iy_ik(\mathbf{x}_i, \mathbf{z})\right] - b\right).
현대적 방법
SVM 분류기를 찾기 위한 최근 알고리즘에는 준경사 하강법과 좌표 하강법이 포함된다. 두 기법 모두 크고 희소한 데이터셋을 다룰 때 전통적인 접근법에 비해 상당한 이점을 제공하는 것으로 입증되었다—준경사 방법은 훈련 예시가 많을 때 특히 효율적이며, 좌표 하강법은 특징 공간의 차원이 높을 때 효율적이다.
준경사 하강법
SVM을 위한 준경사 하강법 알고리즘은 다음 표현식을 직접 다룬다.
f(\mathbf{w}, b) = \left[\frac 1 n \sum_{i=1}^n \max\left(0, 1 - y_i(\mathbf{w}^\mathsf{T} \mathbf{x}_i - b)\right) \right] + \lambda |\mathbf{w}|^2.
f는 \mathbf{w}와 b의 볼록 함수임에 유의하라. 따라서 전통적인 경사 하강법(또는 SGD) 방법을 적용할 수 있는데, 함수의 기울기 방향으로 한 단계를 진행하는 대신 함수의 준경사에서 선택된 벡터 방향으로 한 단계를 진행한다. 이 접근법은 특정 구현에서 반복 횟수가 데이터 포인트의 수 n에 비례하여 증가하지 않는다는 장점이 있다.[^26]
좌표 하강법
SVM을 위한 좌표 하강법 알고리즘은 쌍대 문제에서 출발한다.
\begin{align} &\text{maximize},, f(c_1 \ldots c_n) = \sum_{i=1}^n c_i - \frac 1 2 \sum_{i=1}^n\sum_{j=1}^n y_i c_i(x_i \cdot x_j)y_j c_j,\ &\text{subject to } \sum_{i=1}^n c_iy_i = 0,,\text{and } 0 \leq c_i \leq \frac{1}{2n\lambda};\text{for all }i. \end{align}
각 i \in {1,, \ldots,, n}에 대해, 반복적으로 계수 c_i를 \partial f/ \partial c_i 방향으로 조정한다. 그런 다음, 결과로 얻어진 계수 벡터 (c_1',,\ldots,,c_n')를 주어진 제약 조건을 만족하는 가장 가까운 계수 벡터로 사영한다. (일반적으로 유클리드 거리가 사용된다.) 이 과정을 거의 최적의 계수 벡터가 얻어질 때까지 반복한다. 이렇게 얻어진 알고리즘은 실제로 매우 빠르지만, 성능 보장이 증명된 것은 많지 않다.[^27]
경험적 위험 최소화
위에서 설명한 소프트 마진 서포트 벡터 머신은 힌지 손실에 대한 경험적 위험 최소화(ERM) 알고리즘의 한 예이다. 이러한 관점에서 서포트 벡터 머신은 통계적 추론을 위한 자연스러운 알고리즘 부류에 속하며, 그 고유한 특성의 상당 부분은 힌지 손실의 행동 양상에 기인한다. 이 관점은 SVM이 어떻게 그리고 왜 작동하는지에 대한 추가적인 통찰을 제공하며, 그 통계적 성질을 더 잘 분석할 수 있게 해준다.
위험 최소화
지도 학습에서는 레이블 y_1 \ldots y_n이 부여된 훈련 예제 집합 X_1 \ldots X_n이 주어지며, X_{n+1}이 주어졌을 때 y_{n+1}을 예측하고자 한다. 이를 위해 f(X_{n+1})이 y_{n+1}의 "좋은" 근사가 되도록 가설 f를 구성한다. "좋은" 근사는 보통 손실 함수 \ell(y,z)의 도움으로 정의되며, 이는 z가 y의 예측으로서 얼마나 나쁜지를 나타낸다. 그러면 우리는 기대 위험을 최소화하는 가설을 선택하고자 한다:
\varepsilon(f) = \mathbb{E}\left[\ell(y_{n+1}, f(X_{n+1})) \right].
대부분의 경우 X_{n+1},,y_{n+1}의 결합 분포를 직접 알 수 없다. 이러한 경우 일반적인 전략은 경험적 위험을 최소화하는 가설을 선택하는 것이다:
\hat \varepsilon(f) = \frac 1 n \sum_{k=1}^n \ell(y_k, f(X_k)).
확률 변수 열 X_k,, y_k에 대한 특정 가정 하에서(예를 들어, 유한 마르코프 과정에 의해 생성되는 경우), 고려하는 가설의 집합이 충분히 작다면, n이 커짐에 따라 경험적 위험의 최소화 함수는 기대 위험의 최소화 함수를 근사적으로 잘 따르게 된다. 이 접근법을 경험적 위험 최소화, 즉 ERM이라 한다.
정규화와 안정성
최소화 문제가 잘 정의된 해를 갖기 위해서는 고려하는 가설의 집합 \mathcal{H}에 제약 조건을 부과해야 한다. \mathcal{H}가 노름 공간인 경우(SVM의 경우가 이에 해당), 특히 효과적인 기법은 \lVert f \rVert_{\mathcal H} < k를 만족하는 가설 f만을 고려하는 것이다. 이는 정규화 벌칙 \mathcal R(f) = \lambda_k\lVert f \rVert_{\mathcal H}을 부과하고 다음의 새로운 최적화 문제를 푸는 것과 동치이다:
\hat f = \mathrm{arg}\min_{f \in \mathcal{H}} \hat \varepsilon(f) + \mathcal{R}(f).
이 접근법을 티호노프 정규화라 한다.
보다 일반적으로, \mathcal{R}(f)는 가설 f의 복잡도에 대한 어떤 측도가 될 수 있으며, 따라서 더 단순한 가설이 선호된다.
SVM과 힌지 손실
(소프트 마진) SVM 분류기 \hat\mathbf{w}, b: \mathbf{x} \mapsto \sgn(\hat\mathbf{w}^\mathsf{T} \mathbf{x} - b)는 다음 식을 최소화하도록 선택된다는 것을 상기하자:
\left[\frac 1 n \sum_{i=1}^n \max\left(0, 1 - y_i(\mathbf{w}^\mathsf{T} \mathbf{x} - b)\right) \right] + \lambda |\mathbf{w}|^2.
위의 논의에 비추어 보면, SVM 기법은 티호노프 정규화를 적용한 경험적 위험 최소화와 동치임을 알 수 있으며, 이 경우 손실 함수는 힌지 손실이다:
\ell(y,z) = \max\left(0, 1 - yz \right).
이 관점에서 SVM은 정규화 최소제곱법이나 로지스틱 회귀와 같은 다른 기본적인 분류 알고리즘과 밀접하게 관련되어 있다. 이 세 가지의 차이는 손실 함수의 선택에 있다: 정규화 최소제곱법은 제곱 손실 \ell_{sq}(y,z) = (y-z)^2을 사용한 경험적 위험 최소화에 해당하고, 로지스틱 회귀는 로그 손실을 사용한다:
\ell_{\log}(y,z) = \ln(1 + e^{-yz}).
목표 함수
힌지 손실과 다른 손실 함수들 사이의 차이는 목표 함수, 즉 주어진 확률 변수 쌍 X,,y에 대해 기대 위험을 최소화하는 함수의 관점에서 가장 잘 설명된다.
특히, y_x를 사건 X = x에 대한 y의 조건부 분포라 하자. 분류 설정에서 다음과 같다:
y_x = \begin{cases} 1 & \text{with probability } p_x \ -1 & \text{with probability } 1-p_x \end{cases}
따라서 최적 분류기는 다음과 같다:
f^*(x) = \begin{cases}1 & \text{if }p_x \geq 1/2 \ -1 & \text{otherwise}\end{cases}
제곱 손실의 경우 목표 함수는 조건부 기댓값 함수 f_{sq}(x) = \mathbb{E}\left[y_x\right]이고, 로지스틱 손실의 경우 로짓 함수 f_{\log}(x) = \ln\left(p_x / ({1-p_x})\right)이다. 이 두 목표 함수 모두 올바른 분류기를 산출하지만(\sgn(f_{sq}) = \sgn(f_\log) = f^*이므로), 실제로 필요한 것보다 더 많은 정보를 제공한다. 실제로 이들은 y_x의 분포를 완전히 기술하기에 충분한 정보를 제공한다.
반면에, 힌지 손실의 목표 함수는 정확히 f^*임을 확인할 수 있다. 따라서 충분히 풍부한 가설 공간에서—또는 동치적으로 적절히 선택된 커널에 대해—SVM 분류기는 데이터를 올바르게 분류하는 함수 중 (\mathcal{R}의 관점에서) 가장 단순한 함수로 수렴한다. 이는 SVM의 기하학적 해석을 확장하는 것이다—선형 분류의 경우, 마진이 서포트 벡터 사이에 놓이는 모든 함수가 경험적 위험을 최소화하며, 이들 중 가장 단순한 것이 최대 마진 분류기이다.[^28]
속성
SVM은 일반화 선형 분류기 계열에 속하며 퍼셉트론의 확장으로 해석할 수 있다.[^29] 또한 티호노프 정규화의 특수한 경우로 간주할 수도 있다. 특별한 속성은 경험적 분류 오류를 최소화하면서 동시에 기하학적 마진을 최대화한다는 점이며, 이러한 이유로 최대 마진 분류기라고도 불린다.
SVM과 다른 분류기의 비교는 Meyer, Leisch, Hornik에 의해 수행되었다.[^30]
매개변수 선택
SVM의 효과는 커널의 선택, 커널의 매개변수, 그리고 소프트 마진 매개변수 \lambda에 따라 달라진다. 일반적인 선택은 단일 매개변수 *\gamma*를 갖는 가우시안 커널이다. \lambda와 \gamma의 최적 조합은 흔히 \lambda와 *\gamma*의 지수적으로 증가하는 수열을 사용한 그리드 탐색으로 선택되며, 예를 들어 \lambda \in { 2^{-5}, 2^{-3}, \dots, 2^{13},2^{15} }; \gamma \in { 2^{-15},2^{-13}, \dots, 2^{1},2^{3} }이다. 일반적으로 각 매개변수 조합은 교차 검증을 통해 확인되며, 최상의 교차 검증 정확도를 가진 매개변수가 선택된다. 또는 베이즈 최적화에 관한 최근 연구를 사용하여 \lambda와 *\gamma*를 선택할 수 있으며, 이 방법은 흔히 그리드 탐색보다 훨씬 적은 수의 매개변수 조합 평가만을 필요로 한다. 테스트 및 새로운 데이터 분류에 사용되는 최종 모델은 선택된 매개변수를 사용하여 전체 훈련 세트에 대해 훈련된다.[^31]
문제점
SVM의 잠재적 단점은 다음과 같은 측면을 포함한다:
- 입력 데이터의 완전한 레이블링이 필요함
- 보정되지 않은 클래스 소속 확률—SVM은 유한 데이터에서의 확률 추정을 회피하는 Vapnik의 이론에서 비롯됨
- SVM은 두 클래스 과제에만 직접 적용할 수 있음. 따라서 다중 클래스 과제를 여러 이진 문제로 축소하는 알고리즘을 적용해야 하며, 다중 클래스 SVM 섹션을 참조할 것.
- 해결된 모델의 매개변수는 해석하기 어려움.
확장
다중 클래스 SVM
다중 클래스 SVM은 서포트 벡터 머신을 사용하여 인스턴스에 레이블을 할당하는 것을 목표로 하며, 레이블은 여러 원소로 구성된 유한 집합에서 추출된다.
이를 위한 주된 접근법은 단일 다중 클래스 문제를 여러 이진 분류 문제로 축소하는 것이다.[^4] 이러한 축소를 위한 일반적인 방법은 다음과 같다:[^4][^5]
- 하나의 레이블과 나머지를 구별하는(일대다, one-versus-all) 또는 모든 클래스 쌍 간을 구별하는(일대일, one-versus-one) 이진 분류기를 구축하는 방법. 일대다 방식에서 새로운 인스턴스의 분류는 승자독식 전략으로 수행되며, 가장 높은 출력 함수 값을 가진 분류기가 클래스를 할당한다(출력 함수가 비교 가능한 점수를 생성하도록 보정되어야 한다는 점이 중요하다). 일대일 접근법에서는 최다 득표 전략으로 분류가 수행되며, 각 분류기가 인스턴스를 두 클래스 중 하나에 할당한 후 할당된 클래스의 투표 수를 하나 증가시키고, 최종적으로 가장 많은 투표를 받은 클래스가 인스턴스의 분류를 결정한다.
- 방향 비순환 그래프 SVM (DAGSVM)[^32]
- 오류 정정 출력 코드[^33]
Crammer와 Singer는 다중 클래스 분류 문제를 여러 이진 분류 문제로 분해하는 대신 단일 최적화 문제로 변환하는 다중 클래스 SVM 방법을 제안하였다.[^34] Lee, Lin, Wahba[^35][^36] 및 Van den Burg와 Groenen도 참조하라.[^37]
변환 서포트 벡터 머신
변환 서포트 벡터 머신은 변환의 원리를 따라 준지도 학습에서 부분적으로 레이블이 지정된 데이터도 처리할 수 있도록 SVM을 확장한 것이다. 여기서 학습기는 훈련 집합 \mathcal{D} 외에도 분류할 테스트 예제의 집합
\mathcal{D}^\star = { \mathbf{x}^\star_i \mid \mathbf{x}^\star_i \in \mathbb{R}^p}_{i=1}^k
을 함께 제공받는다. 형식적으로, 변환 서포트 벡터 머신은 다음의 원시 최적화 문제로 정의된다:[^38]
(\mathbf{w}, b, \mathbf{y}^\star에 대해) 최소화
\frac{1}{2}|\mathbf{w}|^2
제약 조건 (임의의 i = 1, \dots, n 및 임의의 j = 1, \dots, k에 대해)
\begin{align} &y_i(\mathbf{w} \cdot \mathbf{x}_i - b) \ge 1, \ &y^\star_j(\mathbf{w} \cdot \mathbf{x}^\star_j - b) \ge 1, \end{align}
그리고
y^\star_j \in {-1, 1}.
변환 서포트 벡터 머신은 1998년 블라디미르 바프닉(Vladimir N. Vapnik)에 의해 도입되었다.
구조화 SVM
구조화 서포트 벡터 머신은 전통적인 SVM 모델의 확장이다. SVM 모델은 주로 이진 분류, 다중 클래스 분류, 회귀 작업을 위해 설계되었지만, 구조화 SVM은 구문 분석 트리, 분류 체계를 이용한 분류, 서열 정렬 등 일반적인 구조화 출력 레이블을 처리할 수 있도록 적용 범위를 넓힌다.[^39]
회귀

회귀를 위한 SVM 버전은 1996년 블라디미르 바프닉(Vladimir N. Vapnik), 해리스 드러커(Harris Drucker), 크리스토퍼 버지스(Christopher J. C. Burges), 린다 카우프만(Linda Kaufman), 알렉산더 스몰라(Alexander J. Smola)에 의해 제안되었다.[^40] 이 방법은 서포트 벡터 회귀(SVR)라고 불린다. (위에서 설명한) 서포트 벡터 분류에 의해 생성된 모델은 훈련 데이터의 부분 집합에만 의존하는데, 이는 모델 구축을 위한 비용 함수가 마진 너머에 위치한 훈련 점들을 고려하지 않기 때문이다. 유사하게, SVR에 의해 생성된 모델도 훈련 데이터의 부분 집합에만 의존하는데, 이는 모델 구축을 위한 비용 함수가 모델 예측에 가까운 훈련 데이터를 무시하기 때문이다. 최소제곱 서포트 벡터 머신(LS-SVM)으로 알려진 또 다른 SVM 버전은 Suykens와 Vandewalle에 의해 제안되었다.[^41]
원래의 SVR을 훈련하는 것은 다음을 푸는 것을 의미한다[^42]
최소화 \tfrac{1}{2} |w|^2 제약 조건 | y_i - \langle w, x_i \rangle - b | \le \varepsilon
여기서 x_i는 목표값 y_i를 가진 훈련 샘플이다. 내적에 절편을 더한 \langle w, x_i \rangle + b는 해당 샘플에 대한 예측이며, \varepsilon는 임계값으로 작용하는 자유 매개변수로, 모든 예측은 실제 예측의 \varepsilon 범위 내에 있어야 한다. 오차를 허용하고 위 문제가 실행 불가능한 경우 근사를 가능하게 하기 위해 일반적으로 여유 변수가 위 식에 추가된다.
베이즈 SVM
2011년 Polson과 Scott는 데이터 확장 기법을 통해 SVM이 베이즈 해석을 허용한다는 것을 보였다.[^43] 이 접근법에서 SVM은 그래프 모델(매개변수가 확률 분포를 통해 연결되는)로 간주된다. 이러한 확장된 관점은 유연한 특성 모델링, 자동 초매개변수 조정, 예측 불확실성 정량화 등 베이즈 기법을 SVM에 적용할 수 있게 해준다. 2017년에 플로리안 벤첼(Florian Wenzel)이 확장 가능한 베이즈 SVM 버전을 개발하여 빅데이터에 베이즈 SVM을 적용할 수 있게 하였다.[^44] 플로리안 벤첼은 베이즈 커널 서포트 벡터 머신(SVM)을 위한 변분 추론(VI) 방식과 선형 베이즈 SVM을 위한 확률적 버전(SVI)의 두 가지 다른 버전을 개발하였다.[^45]
구현
최대 마진 초평면의 매개변수는 최적화 문제를 풀어 도출된다. SVM에서 발생하는 이차 계획법(QP) 문제를 빠르게 풀기 위한 여러 특화된 알고리즘이 존재하며, 대부분 문제를 더 작고 관리 가능한 부분으로 분해하는 휴리스틱에 의존한다.
또 다른 접근법은 뉴턴 유사 반복법을 사용하여 원시 문제와 쌍대 문제의 카루시-쿤-터커 조건의 해를 구하는 내부점 방법을 사용하는 것이다.[^46] 이 접근법은 분해된 일련의 문제를 푸는 대신 문제를 한꺼번에 직접 풀어낸다. 큰 커널 행렬을 포함하는 선형 시스템을 푸는 것을 피하기 위해, 커널 트릭에서는 행렬의 저랭크 근사가 자주 사용된다.
또 다른 일반적인 방법은 플랫의 순차 최소 최적화(SMO) 알고리즘으로, 문제를 해석적으로 풀 수 있는 2차원 부분 문제로 분해하여 수치 최적화 알고리즘과 행렬 저장의 필요성을 제거한다. 이 알고리즘은 개념적으로 단순하고, 구현이 쉬우며, 일반적으로 더 빠르고, 어려운 SVM 문제에 대해 더 나은 확장성을 가진다.[^47]
선형 서포트 벡터 머신의 특수한 경우는 밀접한 관계에 있는 로지스틱 회귀를 최적화하는 데 사용되는 동일한 종류의 알고리즘으로 더 효율적으로 풀 수 있다. 이 부류의 알고리즘에는 부분경사 하강법(예: PEGASOS[^48])과 좌표 하강법(예: LIBLINEAR[^49])이 포함된다. LIBLINEAR는 매력적인 학습 시간 특성을 가지고 있다. 각 수렴 반복은 학습 데이터를 읽는 데 걸리는 시간에 선형적인 시간이 소요되며, 반복은 Q-선형 수렴 특성도 가지고 있어 알고리즘이 극도로 빠르다.
일반 커널 SVM은 부분경사 하강법(예: P-packSVM[^50])을 사용하여 더 효율적으로 풀 수 있으며, 특히 병렬화가 허용될 때 그러하다.
커널 SVM은 LIBSVM, MATLAB, SAS, SVMlight, kernlab, scikit-learn, Shogun, Weka, Shark, JKernelMachines, OpenCV 등 많은 머신러닝 도구에서 사용할 수 있다.
데이터의 전처리(표준화)는 분류 정확도를 높이기 위해 강력히 권장된다.[^51] 최소-최대, 소수점 스케일링에 의한 정규화, Z-점수 등 몇 가지 표준화 방법이 있다.[^52] SVM에서는 보통 각 특성의 평균을 빼고 분산으로 나누는 방법이 사용된다.[^53]
같이 보기
- 현장 적응 표작성
- 커널 머신
- 피셔 커널
- 플랫 스케일링
- 다항식 커널
- 예측 분석
- 서포트 벡터 머신의 정규화 관점
- 관련 벡터 머신, SVM과 기능적 형태가 동일한 확률적 희소 커널 모델
- 순차 최소 최적화
- 공간 매핑
- 위노 알고리즘
- 방사 기저 함수 네트워크
추가 읽을거리
-
-
-
-
-
-
-
-
-
외부 링크
-
-
-
-
-
-
-
-
- libsvm, LIBSVM은 널리 사용되는 SVM 학습기 라이브러리이다
- liblinear는 일부 SVM을 포함한 대규모 선형 분류를 위한 라이브러리이다
- SVM light는 SVM을 이용한 학습 및 분류를 위한 소프트웨어 도구 모음이다
- SVMJS 라이브 데모는 SVM의 자바스크립트 구현을 위한 GUI 데모이다
참고 문헌
[^1]: Ben-Hur, Asa. "서포트 벡터 클러스터링" (2001);
[^2]: Boser, Bernhard E.. 제5회 계산 학습 이론 연례 워크숍 논문집 – COLT '92
[^3]: Cortes, Corinna. 서포트 벡터 네트워크
[^4]: Duan, Kai-Bo. 다중 분류기 시스템
[^5]: Hsu, Chih-Wei. 다중 클래스 서포트 벡터 머신 방법 비교
[^6]: Vapnik, Vladimir N.. 인공 신경망 — ICANN'97. Springer. (1997)
[^7]: Awad, Mariette. 효율적 학습 기계. Apress
[^8]: cite journal last1 = Huang first1 = H. H. last2 = Xu first2 = T. last3 = Yang first3 = J. title = 로지스틱 회귀, 서포트 벡터 머신, 퍼머넌탈 분류기 비교
[^9]: cite journal last1 = Opper first1 = M last2 = Kinzel first2 = W last3 = Kleinz first3 = J last4 = Nehl first4 = R title = 최적 퍼셉트론의 일반화 능력에 관하여
[^10]: 1.4. 서포트 벡터 머신 — scikit-learn 0.20.2 문서
[^11]: Hastie, Trevor. 통계 학습의 기초 : 데이터 마이닝, 추론 및 예측. Springer
[^12]: Press, William H.. 수치 해석법: 과학 컴퓨팅의 기술. Cambridge University Press
[^13]: Joachims, Thorsten. 기계 학습: ECML-98. Springer. (1998)
[^14]: Pradhan, Sameer S.. 서포트 벡터 머신을 이용한 얕은 의미 분석. Association for Computational Linguistics. (2004년 5월 2일)
[^15]: Vapnik, Vladimir N.: 초청 연사. IPMU 정보 처리 및 관리 2014).
[^16]: cite book chapter-url=https://pdfs.semanticscholar.org/917f/15d33d32062bffeb6401eee9fe71d16d6a84.pdf s2cid=4154772 doi=10.1007/978-3-319-16829-6_12 chapter=공간-분류군 정보 그래뉼
[^17]: 다양한 지형지물에 대한 RADARSAT-2 편파 데이터의 지도 분류
[^18]: DeCoste, Dennis. 불변 서포트 벡터 머신 훈련. (2002)
[^19]: Maitra, D. S.. 2015 제13회 문서 분석 및 인식 국제 학술대회 (ICDAR). (2015년 8월)
[^20]: cite journal pmc=3767485 year=2013 last1=Gaonkar first1=B. last2=Davatzikos first2=C. title=서포트 벡터 머신 기반 다변량 통계적 유의성 지도의 해석적 추정
[^21]: Cuingnet, Rémi. 뇌졸중 결과와 관련된 확산 변화 검출을 위한 SVM의 공간 정규화
[^22]: Statnikov, Alexander; Hardin, Douglas; & Aliferis, Constantin; (2006); [http://www.ccdlab.org/paper-pdfs/NIPS_2006.pdf "SVM 가중치 기반 방법을 사용한 인과적 관련 및 비인과적 관련 변수 식별
[^23]: 왜 SVM 마진은 \frac{2와 같은가. (2015년 5월 30일)
[^24]: Aizerman, Mark A.. 패턴 인식 학습에서 포텐셜 함수 방법의 이론적 기초
[^25]: Jin, Chi. 차원 의존적 PAC-베이즈 마진 경계
[^26]: Shalev-Shwartz, Shai. Pegasos: SVM을 위한 원시 추정 하위 경사 솔버. (2010-10-16)
[^27]: Hsieh, Cho-Jui. 제25회 기계 학습 국제 학술대회 논문집 - ICML '08. ACM. (2008-01-01)
[^28]: Rosasco, Lorenzo. 손실 함수는 모두 동일한가?. (2004-05-01)
[^29]: R. Collobert and S. Bengio (2004). 퍼셉트론, MLP 및 SVM 간의 연결. 국제 기계 학습 학술대회 (ICML) 논문집.
[^30]: Meyer, David. 테스트 중인 서포트 벡터 머신. (2003년 9월)
[^31]: Hsu, Chih-Wei. 서포트 벡터 분류 실용 가이드
[^32]: Platt, John. 신경 정보 처리 시스템의 발전. MIT Press
[^33]: Dietterich, Thomas G.. 오류 수정 출력 코드를 통한 다중 클래스 학습 문제 해결
[^34]: Crammer, Koby. 다중 클래스 커널 기반 벡터 머신의 알고리즘적 구현에 관하여
[^35]: Lee, Yoonkyung. 다중 범주 서포트 벡터 머신
[^36]: Lee, Yoonkyung. 다중 범주 서포트 벡터 머신
[^37]: Van den Burg, Gerrit J. J.. GenSVM: 일반화된 다중 클래스 서포트 벡터 머신
[^38]: Joachims, Thorsten. 서포트 벡터 머신을 이용한 텍스트 분류의 변환 추론
[^39]: Cite web url=https://www.cs.cornell.edu/people/tj/publications/tsochantaridis_etal_04a.pdf title=상호 의존적 및 구조화된 출력 공간을 위한 서포트 벡터 머신 학습 website=www.cs.co
[^40]: Drucker, Harris; Burges, Christ. C.; Kaufman, Linda; Smola, Alexander J.; and Vapnik, Vladimir N. (1997); "[http://papers.nips.cc/paper/1238-support-vector-regression-machines.pdf 서포트 벡터 회귀 머신
[^41]: Suykens, Johan A. K.; Vandewalle, Joos P. L.; "[https://lirias.kuleuven.be/bitstream/123456789/218716/2/Suykens_NeurProcLett.pdf 최소 제곱 서포트 벡터 머신 분류기]", ''신경 처리
[^42]: Smola, Alex J.. 서포트 벡터 회귀 튜토리얼
[^43]: Polson, Nicholas G.. 서포트 벡터 머신을 위한 데이터 증강
[^44]: Wenzel, Florian. 데이터베이스에서의 기계 학습 및 지식 발견
[^45]: Florian Wenzel; Matthäus Deutsch; Théo Galy-Fajou; Marius Kloft; [http://approximateinference.org/accepted/WenzelEtAl2016.pdf "베이지안 비선형 서포트 벡터를 위한 확장 가능한 근사 추론
[^46]: Ferris, Michael C.. 대규모 서포트 벡터 머신을 위한 내부점 방법
[^47]: Platt, John C.. 순차 최소 최적화: 서포트 벡터 머신 훈련을 위한 빠른 알고리즘
[^48]: Shalev-Shwartz, Shai. Pegasos: SVM을 위한 원시 추정 하위 경사 솔버
[^49]: Fan, Rong-En. LIBLINEAR: 대규모 선형 분류를 위한 라이브러리
[^50]: Allen Zhu, Zeyuan. P-packSVM: 병렬 원시 경사 하강 커널 SVM
[^51]: Cite journal volume = 9 issue = Aug pages = 1871–1874 last1 = Fan first1 = Rong-En last2 = Chang first2 = Kai-Wei last3 = Hsieh first3 = Cho-Jui last4 = Wang first4 = Xiang-Rui last5 = Lin
[^52]: Cite journal doi = 10.19026/rjaset.6.3638 volume = 6 pages = 3299–3303 last1 = Mohamad first1 = Ismail last2 = Usman first2 = Dauda title = 표준화와 그것이 K-평균 클러스터링에 미치는 영향
[^53]: Cite journal doi = 10.1140/epjds/s13688-019-0201-0 volume = 8 last1 = Fennell first1 = Peter last2 = Zuo first2 = Zhiya last3 = Lerman first3 = Kristina author3-link=Kristina Lerman title =
관련 인사이트

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.

그 30분을 18년 동안 매일 반복했습니다 — 품질팀장이 본 AI Agent
18년차 품질팀장이 매일 아침 30분씩 반복하던 데이터 분석을 AI Agent가 3분 만에 해냈습니다. 챗봇과는 완전히 다른 물건 — 직접 시스템에 접근해서 데이터를 꺼내고 분석하는 AI의 현장 도입기.

ERP 20년, 나는 왜 AI를 얹기로 했나
ERP 20년차 제조IT본부장의 고백: 3,200만 행의 데이터가 잠들어 있었다. ERP를 바꾸지 않고 AI를 얹자, 일주일 걸리던 불량 분석이 수 초로 줄었다.