인공지능
최종 수정 2026.03.23인공지능 (AI)은 학습, 추론, 문제 해결, 인식, 의사 결정 등 일반적으로 인간의 지능과 관련된 작업을 수행할 수 있는 컴퓨터 시스템의 능력이다. 이는 기계가 주변 환경을 인식하고 학습과 지능을 활용하여 정의된 목표를 달성할 가능성을 극대화하는 행동을 취할 수 있도록 하는 방법과 소프트웨어를 개발하고 연구하는 컴퓨터 과학의 연구 분야이다.
AI의 대표적인 응용 분야로는 고급 웹 검색 엔진(예: 구글 검색), 추천 시스템(유튜브, 아마존, 넷플릭스에서 사용), 가상 비서(예: 구글 어시스턴트, 시리, 알렉사), 자율 주행 차량(예: 웨이모), 생성형 및 창작 도구(예: 언어 모델 및 AI 아트), 전략 게임에서의 초인적 플레이 및 분석(예: 체스와 바둑) 등이 있다. 그러나 많은 AI 응용 프로그램은 그렇게 인식되지 않는다: "최첨단 AI의 상당 부분이 일반 응용 프로그램에 스며들었으며, 무언가가 충분히 유용하고 충분히 보편화되면 더 이상 AI라고 불리지 않기 때문에 AI라는 이름이 붙지 않는 경우가 많다."[^19][^20]
AI 연구의 다양한 하위 분야는 특정 목표와 특정 도구의 사용을 중심으로 구성되어 있다. AI 연구의 전통적인 목표에는 학습, 추론, 지식 표현, 계획, 자연어 처리, 인식이 포함되며, 로봇 공학에 대한 지원도 포함된다. 이러한 목표를 달성하기 위해 AI 연구자들은 탐색 및 수학적 최적화, 형식 논리, 인공 신경망, 통계·오퍼레이션스 리서치·경제학에 기반한 방법 등 광범위한 기술을 적용하고 통합해 왔다. AI는 또한 심리학, 언어학, 철학, 신경 과학 및 기타 분야의 지식도 활용한다.[^21] OpenAI, 구글 딥마인드, 메타[^22] 등 일부 기업은 사실상 모든 인지 작업을 최소한 인간만큼 수행할 수 있는 AI인 범용 인공지능(AGI)의 개발을 목표로 하고 있다.
인공지능은 1956년에 학문 분야로 창설되었으며, 그 역사를 통해 여러 차례의 낙관론 주기를 거쳤고,[^13][^14] 그 뒤에는 실망과 자금 손실의 시기, 즉 AI 겨울이라 알려진 시기가 뒤따랐다. 2012년 이후 그래픽 처리 장치(GPU)가 신경망 가속에 사용되기 시작하고 딥러닝이 기존의 AI 기술을 능가하면서 자금과 관심이 크게 증가했다. 이러한 성장은 2017년 트랜스포머 아키텍처의 등장 이후 더욱 가속화되었다. 2020년대에는 고급 생성형 AI의 급속한 발전이 지속되면서 AI 붐으로 알려지게 되었다. 콘텐츠를 생성하고 수정할 수 있는 생성형 AI의 능력은 여러 의도치 않은 결과와 피해를 초래했다. AI의 장기적 영향과 잠재적 존재론적 위험에 대한 윤리적 우려가 제기되었으며, 기술의 안전성과 혜택을 보장하기 위한 규제 정책에 관한 논의가 이루어지고 있다.
목표
지능을 시뮬레이션(또는 창조)하는 일반적인 문제는 하위 문제들로 나뉘어져 왔다. 이러한 하위 문제들은 연구자들이 지능적인 시스템에서 나타나기를 기대하는 특정한 특성이나 능력으로 구성된다. 아래에 설명된 특성들은 가장 많은 관심을 받아 왔으며 인공지능 연구의 범위를 포괄한다.
추론과 문제 해결
초기 연구자들은 인간이 퍼즐을 풀거나 논리적 추론을 할 때 사용하는 단계적 추론을 모방하는 알고리즘을 개발했다.[^23] 1980년대 후반과 1990년대에 이르러, 확률과 경제학의 개념을 활용하여 불확실하거나 불완전한 정보를 처리하는 방법들이 개발되었다.[^24]
이러한 알고리즘 중 다수는 "조합 폭발"을 경험하기 때문에 대규모 추론 문제를 해결하는 데 불충분하다: 문제가 커질수록 기하급수적으로 느려지는 것이다. 인간조차도 초기 인공지능 연구가 모델링할 수 있었던 단계적 추론을 거의 사용하지 않는다. 인간은 대부분의 문제를 빠르고 직관적인 판단으로 해결한다. 정확하고 효율적인 추론은 아직 해결되지 않은 문제이다.
지식 표현

지식 표현과 지식 공학[^25]은 인공지능 프로그램이 질문에 지능적으로 답하고 실세계 사실에 대한 추론을 할 수 있게 해준다. 형식적 지식 표현은 내용 기반 색인 및 검색, 장면 해석, 임상 의사결정 지원, 지식 발견(대규모 데이터베이스에서 "흥미롭고" 실행 가능한 추론을 추출하는 것) 및 기타 분야에서 사용된다.
지식 기반은 프로그램이 사용할 수 있는 형태로 표현된 지식의 집합체이다. 온톨로지는 특정 지식 영역에서 사용되는 객체, 관계, 개념, 속성의 집합이다. 지식 기반은 객체, 속성, 범주, 객체 간의 관계;[^26] 상황, 사건, 상태, 시간;[^27] 원인과 결과;[^28] 지식에 대한 지식(다른 사람들이 무엇을 알고 있는지에 대해 우리가 아는 것);[^29] 기본 추론(인간이 다르게 들을 때까지 참이라고 가정하며 다른 사실이 변하더라도 참으로 유지되는 것들); 그리고 그 밖의 많은 측면과 지식 영역을 표현해야 한다.
지식 표현에서 가장 어려운 문제들 중에는 상식 지식의 폭넓음(보통 사람이 아는 원자적 사실의 집합은 방대하다)과 대부분의 상식 지식의 하위 기호적 형태(사람들이 아는 것의 대부분은 구두로 표현할 수 있는 "사실"이나 "진술"로 표현되지 않는다)가 있다. 또한 인공지능 응용 프로그램을 위한 지식을 확보하는 문제인 지식 획득의 어려움도 있다.
계획 수립과 의사결정
"에이전트"란 세계를 인식하고 행동을 취하는 모든 실체(인공적이든 아니든)를 말한다. 합리적 에이전트는 목표나 선호를 가지며 이를 실현하기 위해 행동한다. 자동화된 계획 수립에서 에이전트는 특정 목표를 가진다.[^30] 자동화된 의사결정에서 에이전트는 선호를 가진다—선호하는 상황이 있고 피하려는 상황이 있다. 의사결정 에이전트는 각 상황에 에이전트가 얼마나 선호하는지를 측정하는 숫자("효용"이라 한다)를 부여한다. 가능한 각 행동에 대해 "기대 효용"을 계산할 수 있다: 그 행동의 모든 가능한 결과의 효용을 결과가 발생할 확률로 가중 평균한 것이다. 그런 다음 기대 효용이 최대인 행동을 선택할 수 있다.[^31]
고전적 계획 수립에서 에이전트는 어떤 행동의 효과가 무엇인지 정확히 알고 있다.[^32] 그러나 대부분의 실세계 문제에서 에이전트는 자신이 처한 상황에 대해 확신하지 못할 수 있으며("미지" 또는 "관측 불가"), 각 가능한 행동 이후에 무엇이 일어날지 확실히 알지 못할 수 있다("결정론적"이지 않다). 에이전트는 확률적 추측을 통해 행동을 선택한 다음 상황을 재평가하여 그 행동이 효과가 있었는지 확인해야 한다.[^33]
이전 결정을 바탕으로 한 철저한 검증과 개선 외에도, 에이전트가 특정 결정을 내린 이유에 대한 설명을 갖추는 것은 신뢰를 구축하는 방법이며, 특히 그 결정에 의존해야 할 때 더욱 그러하다.[^34]
일부 문제에서는 에이전트의 선호가 불확실할 수 있으며, 특히 다른 에이전트나 인간이 관여하는 경우 그러하다. 이러한 선호는 학습될 수 있으며(예: 역강화학습을 통해), 에이전트가 자신의 선호를 개선하기 위해 정보를 탐색할 수도 있다.[^35] 정보 가치 이론은 탐색적 또는 실험적 행동의 가치를 평가하는 데 사용될 수 있다.[^36] 가능한 미래 행동과 상황의 공간은 일반적으로 다루기 어려울 정도로 크므로, 에이전트는 결과가 어떻게 될지 불확실한 상태에서 행동을 취하고 상황을 평가해야 한다.
마르코프 의사결정 과정은 특정 행동이 특정 방식으로 상태를 변화시킬 확률을 설명하는 전이 모델과 각 상태의 효용과 각 행동의 비용을 제공하는 보상 함수를 가진다. 정책은 각 가능한 상태에 의사결정을 연결한다. 정책은 (예: 반복을 통해) 계산될 수 있고, 휴리스틱일 수 있으며, 학습될 수도 있다.[^37]
게임 이론은 상호 작용하는 다수 에이전트의 합리적 행동을 설명하며, 다른 에이전트가 관여하는 의사결정을 내리는 인공지능 프로그램에서 사용된다.[^38]
학습
기계 학습은 주어진 과제에서 자동으로 성능을 향상시킬 수 있는 프로그램에 대한 연구이다.[^39] 이것은 처음부터 인공지능의 일부였다.
![[지도 학습 에서는 훈련 데이터에 예상 답변이 레이블로 표시되는 반면, 비지도 학습에서는 모델이 레이블이 없는 데이터에서 패턴이나 구조를 식별한다.]] 기계 학습에는 여러 종류가 있다. 비지도 학습은 데이터 흐름을 분석하고 다른 안내 없이 패턴을 찾아 예측을 한다.[^40] 지도 학습은 훈련 데이터에 예상 답변을 레이블로 표시해야 하며, 두 가지 주요 유형이 있다: 분류(프로그램이 입력이 어떤 범주에 속하는지 예측하는 법을 학습해야 하는 것)와 회귀(프로그램이 수치 입력을 기반으로 수치 함수를 추론해야 하는 것).
{kind=link}
강화 학습에서는 에이전트가 좋은 반응에 대해 보상을 받고 나쁜 반응에 대해 벌을 받는다. 에이전트는 "좋은" 것으로 분류되는 반응을 선택하는 법을 학습한다.[^41] 전이 학습은 한 문제에서 얻은 지식을 새로운 문제에 적용하는 것이다.[^42] 딥러닝은 이러한 모든 유형의 학습에 대해 생물학적으로 영감을 받은 인공 신경망을 통해 입력을 처리하는 기계 학습의 한 유형이다.[^43]
계산 학습 이론은 계산 복잡도, 표본 복잡도(얼마나 많은 데이터가 필요한지), 또는 기타 최적화 개념으로 학습기를 평가할 수 있다.[^44]
자연어 처리
자연어 처리(NLP)는 프로그램이 인간 언어로 읽고, 쓰고, 소통할 수 있게 해준다.[^45] 구체적인 문제로는 음성 인식, 음성 합성, 기계 번역, 정보 추출, 정보 검색, 질의응답이 있다.[^46]
노엄 촘스키의 생성 문법과 의미망에 기반한 초기 연구는 "마이크로 월드"라고 불리는 작은 영역으로 제한하지 않는 한 단어 의미 중의성 해소에 어려움을 겪었다(상식 지식 문제로 인해). 마거릿 마스터만은 언어를 이해하는 핵심은 문법이 아니라 의미이며, 계산 언어 구조의 기반은 사전이 아니라 시소러스가 되어야 한다고 믿었다.
자연어 처리를 위한 현대 딥러닝 기법에는 단어 임베딩(단어를 일반적으로 그 의미를 부호화하는 벡터로 표현하는 것), 트랜스포머(어텐션 메커니즘을 사용하는 딥러닝 아키텍처) 등이 있다.[^47] 2019년에 생성적 사전 훈련 트랜스포머(또는 "GPT") 언어 모델이 일관된 텍스트를 생성하기 시작했으며, 2023년에는 이러한 모델이 변호사 시험, SAT 시험, GRE 시험, 그리고 많은 다른 실세계 응용 분야에서 인간 수준의 점수를 받을 수 있게 되었다.
인식
기계 인식은 센서(카메라, 마이크, 무선 신호, 능동 라이다, 소나, 레이더, 촉각 센서 등)의 입력을 사용하여 세계의 측면을 추론하는 능력이다. 컴퓨터 비전은 시각적 입력을 분석하는 능력이다.[^48]
이 분야에는 음성 인식, 이미지 분류, 얼굴 인식, 객체 인식, 객체 추적, 로봇 인식이 포함된다.
사회적 지능
 , 1990년대에 만들어진 로봇 머리로, 감정을 인식하고 시뮬레이션할 수 있는 기계이다.]]
, 1990년대에 만들어진 로봇 머리로, 감정을 인식하고 시뮬레이션할 수 있는 기계이다.]]
감성 컴퓨팅은 인간의 느낌, 감정, 기분을 인식, 해석, 처리 또는 시뮬레이션하는 시스템을 포괄하는 분야이다.[^49] 예를 들어, 일부 가상 비서는 대화체로 말하거나 심지어 유머러스하게 농담을 하도록 프로그래밍되어 있다; 이는 인간 상호작용의 감정적 역동성에 더 민감하게 보이게 하거나, 인간-컴퓨터 상호작용을 촉진하는 역할을 한다.
그러나 이는 경험이 부족한 사용자들에게 기존 컴퓨터 에이전트의 지능에 대한 비현실적인 인식을 갖게 하는 경향이 있다. 감성 컴퓨팅과 관련된 적당한 성과로는 텍스트 감성 분석과, 보다 최근에는 인공지능이 영상에 촬영된 대상이 표현하는 효과를 분류하는 멀티모달 감성 분석이 있다.
범용 지능
인공 범용 지능을 갖춘 기계는 인간 지능과 유사한 폭넓음과 다재다능함으로 다양한 문제를 해결할 수 있을 것이다.
기법
AI 연구는 위에서 언급한 목표들을 달성하기 위해 매우 다양한 기법을 사용한다.
탐색과 최적화
AI에서 사용되는 탐색에는 두 가지 종류가 있다: 상태 공간 탐색과 지역 탐색이다.
상태 공간 탐색
상태 공간 탐색은 목표 상태를 찾기 위해 가능한 상태들의 트리를 탐색한다.[^50] 예를 들어, 계획 알고리즘은 목표와 하위 목표의 트리를 탐색하여 목표 상태에 도달하는 경로를 찾으려 하며, 이 과정을 수단-목적 분석이라 한다.
단순한 완전 탐색[^51]은 대부분의 실제 문제에 대해 충분하지 않다: 탐색 공간(탐색해야 할 위치의 수)이 천문학적 수치로 빠르게 증가하기 때문이다. 그 결과 탐색이 너무 느려지거나 완료되지 않는다. "휴리스틱" 또는 "경험 법칙"은 목표에 도달할 가능성이 더 높은 선택지를 우선적으로 처리하는 데 도움을 줄 수 있다.[^52]
적대적 탐색은 체스나 바둑과 같은 게임 프로그램에 사용된다. 이는 가능한 수와 대응 수의 트리를 탐색하여 승리하는 위치를 찾는다.[^53]
지역 탐색
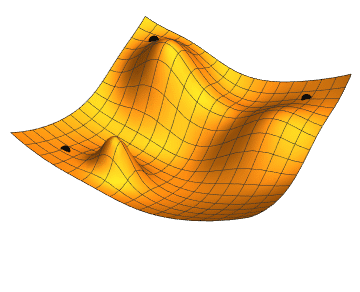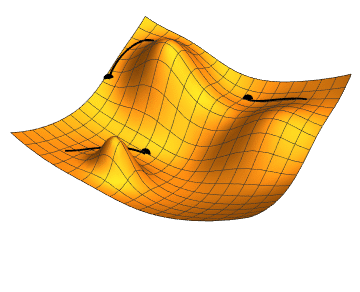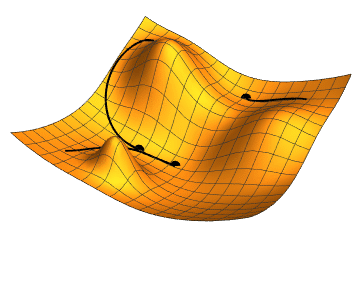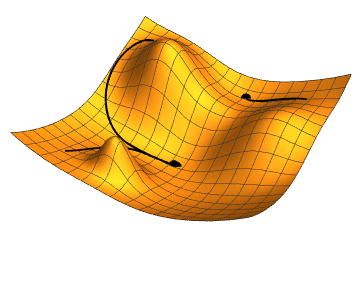
![Illustration of [gradient descent for three different starting points; two parameters (represented by the plan coordinates) are adjusted in order to minimize the loss function (the height).]] 지역 탐색은 수학적 최적화를 사용하여 문제의 해를 찾는다. 일정한 형태의 추측에서 시작하여 이를 점진적으로 개선한다.[^54]
{kind=link}
경사 하강법은 손실 함수를 최소화하기 위해 수치 매개변수 집합을 점진적으로 조정하여 최적화하는 지역 탐색의 한 유형이다. 경사 하강법의 변형은 역전파 알고리즘을 통해 신경망을 훈련하는 데 일반적으로 사용된다.[^55]
또 다른 유형의 지역 탐색은 진화 연산으로, 후보 해 집합을 "변이"와 "재조합"을 통해 반복적으로 개선하고, 각 세대에서 가장 적합한 것만 선택하여 생존시키는 것을 목표로 한다.[^56]
분산 탐색 프로세스는 군집 지능 알고리즘을 통해 조정될 수 있다. 탐색에 사용되는 두 가지 대표적인 군집 알고리즘은 입자 군집 최적화(새 떼의 군집 행동에서 영감을 받음)와 개미 군집 최적화(개미의 이동 경로에서 영감을 받음)이다.
논리
형식 논리는 추론과 지식 표현에 사용된다.[^57] 형식 논리는 두 가지 주요 형태가 있다: 명제 논리(참 또는 거짓인 진술을 다루며 "그리고", "또는", "아닌", "이면"과 같은 논리 접속사를 사용)[^58]와 술어 논리(객체, 술어, 관계도 다루며 "모든 X는 Y이다"와 "어떤 X는 Y이다"와 같은 양화사를 사용)이다.[^59]
논리에서의 연역적 추론은 주어진 것으로 가정되는 다른 진술(전제)로부터 새로운 진술(결론)을 증명하는 과정이다.[^60] 증명은 증명 트리로 구성될 수 있으며, 여기서 노드는 문장으로 표시되고 자식 노드는 추론 규칙에 의해 부모 노드와 연결된다.
문제와 전제 집합이 주어지면, 문제 해결은 루트 노드가 문제의 해로 표시되고 리프 노드가 전제 또는 공리로 표시되는 증명 트리를 탐색하는 것으로 귀결된다. 혼 절의 경우, 문제 해결 탐색은 전제로부터 순방향으로 또는 문제로부터 역방향으로 추론하여 수행할 수 있다.[^61] 1차 논리의 절 형식이라는 더 일반적인 경우에서, 분해법은 공리가 필요 없는 단일 추론 규칙으로, 해결해야 할 문제의 부정을 포함하는 전제로부터 모순을 증명함으로써 문제를 해결한다.[^62]
혼 절 논리와 1차 논리 모두에서의 추론은 결정 불가능하며, 따라서 다루기 어렵다. 그러나 논리 프로그래밍 언어 Prolog에서의 연산을 뒷받침하는 혼 절을 이용한 역방향 추론은 튜링 완전하다. 또한, 그 효율성은 다른 기호 프로그래밍 언어에서의 연산과 대등하다.[^63]
퍼지 논리는 0과 1 사이의 "진리도"를 부여한다. 따라서 모호하고 부분적으로 참인 명제를 처리할 수 있다.[^64]
실패로서의 부정을 포함하는 논리 프로그래밍을 비롯한 비단조 논리는 기본 추론을 처리하도록 설계되었다. 많은 복잡한 영역을 기술하기 위해 다른 특수한 형태의 논리도 개발되었다.
불확실한 추론을 위한 확률적 방법
![A simple [Bayesian network , with the associated conditional probability tables]] AI의 많은 문제(추론, 계획, 학습, 인식, 로봇공학 포함)는 에이전트가 불완전하거나 불확실한 정보를 가지고 작동하도록 요구한다. AI 연구자들은 확률 이론과 경제학의 방법을 사용하여 이러한 문제를 해결하기 위한 여러 도구를 고안했다.[^1] 에이전트가 결정 이론, 의사결정 분석,[^65] 정보 가치 이론을 사용하여[^66] 어떻게 선택하고 계획할 수 있는지를 분석하는 정밀한 수학적 도구가 개발되었다. 이러한 도구에는 마르코프 결정 과정,[^67] 동적 결정 네트워크, 게임 이론 및 메커니즘 설계[^68]와 같은 모델이 포함된다.
{kind=link}
베이즈 네트워크[^69]는 추론(베이즈 추론 알고리즘 사용),[^70] 학습(기댓값 최대화 알고리즘 사용),[^71] 계획(결정 네트워크 사용)[^72] 및 인식(동적 베이즈 네트워크 사용)에 사용할 수 있는 도구이다.
확률적 알고리즘은 또한 필터링, 예측, 평활화, 데이터 스트림에 대한 설명 찾기에도 사용될 수 있으며, 이를 통해 인식 시스템이 시간에 걸쳐 발생하는 과정(예: 은닉 마르코프 모델 또는 칼만 필터)을 분석하는 데 도움을 준다.
 clustering of Old Faithful eruption data starts from a random guess but then successfully converges on an accurate clustering of the two physically distinct modes of eruption.]]
clustering of Old Faithful eruption data starts from a random guess but then successfully converges on an accurate clustering of the two physically distinct modes of eruption.]]
분류기와 통계적 학습 방법
가장 단순한 AI 응용 프로그램은 두 가지 유형으로 나눌 수 있다: 한편으로는 분류기(예: "빛나면 다이아몬드"), 다른 한편으로는 제어기(예: "다이아몬드이면 집어 올리기")이다. 분류기[^73]는 패턴 매칭을 사용하여 가장 가까운 일치를 결정하는 함수이다. 지도 학습을 사용하여 선택된 예제를 기반으로 미세 조정할 수 있다. 각 패턴("관측"이라고도 함)은 특정 사전 정의된 클래스로 레이블이 붙는다. 모든 관측과 그 클래스 레이블을 합쳐 데이터 세트라 한다. 새로운 관측이 수신되면, 그 관측은 이전 경험을 기반으로 분류된다.
사용되는 분류기에는 여러 종류가 있다.[^74] 결정 트리는 가장 단순하고 가장 널리 사용되는 기호 기계 학습 알고리즘이다.[^75] K-최근접 이웃 알고리즘은 1990년대 중반까지 가장 널리 사용된 유추 AI였으며, 서포트 벡터 머신(SVM)과 같은 커널 방법이 1990년대에 K-최근접 이웃을 대체했다.[^76] 나이브 베이즈 분류기는 부분적으로 확장성 덕분에 Google에서 "가장 널리 사용되는 학습기"로 알려져 있다.[^77] 신경망도 분류기로 사용된다.
인공 신경망
![A neural network is an interconnected group of nodes, akin to the vast network of [neuron s in the human brain.]]
{kind=link}
인공 신경망은 인공 뉴런이라고도 하는 노드의 집합을 기반으로 하며, 이는 생물학적 뇌의 뉴런을 느슨하게 모델링한 것이다. 패턴을 인식하도록 훈련되며, 훈련이 완료되면 새로운 데이터에서 그 패턴을 인식할 수 있다. 입력층, 최소 하나의 은닉층, 그리고 출력층이 있다. 각 노드는 함수를 적용하고, 가중치가 지정된 임계값을 넘으면 데이터가 다음 층으로 전달된다. 일반적으로 은닉층이 2개 이상이면 심층 신경망이라 부른다.
신경망의 학습 알고리즘은 훈련 과정에서 각 입력에 대해 올바른 출력을 얻을 수 있는 가중치를 선택하기 위해 지역 탐색을 사용한다. 가장 일반적인 훈련 기법은 역전파 알고리즘이다.[^78] 신경망은 입력과 출력 사이의 복잡한 관계를 모델링하고 데이터에서 패턴을 찾는 것을 학습한다. 이론적으로, 신경망은 어떤 함수든 학습할 수 있다.[^79]
순방향 신경망에서는 신호가 한 방향으로만 전달된다.[^80] 퍼셉트론이라는 용어는 일반적으로 단층 신경망을 가리킨다.[^81] 이와 대조적으로, 딥 러닝은 여러 층을 사용한다. 순환 신경망(RNN)은 출력 신호를 입력으로 되돌려 보내어 이전 입력 사건에 대한 단기 기억을 가능하게 한다. 장단기 기억 네트워크(LSTM)는 장기 의존성을 더 잘 보존하고 기울기 소실 문제에 덜 민감한 순환 신경망이다.[^82] 합성곱 신경망(CNN)은 지역 패턴을 더 효율적으로 처리하기 위해 커널 층을 사용한다. 이러한 지역 처리는 특히 이미지 처리에서 중요한데, 초기 CNN 층은 일반적으로 에지와 곡선 같은 단순한 지역 패턴을 식별하고, 이후 층에서는 텍스처와 같은 더 복잡한 패턴을, 최종적으로는 전체 객체를 감지한다.[^83]
딥 러닝
![[Deep learning is a subset of machine learning, which is itself a subset of artificial intelligence.[^2]]] 딥 러닝은 네트워크의 입력과 출력 사이에 여러 층의 뉴런을 사용한다. 여러 층은 원시 입력에서 점진적으로 더 높은 수준의 특징을 추출할 수 있다. 예를 들어, 이미지 처리에서 하위 층은 에지를 식별하고, 상위 층은 숫자, 문자, 얼굴과 같이 인간에게 관련 있는 개념을 식별할 수 있다.
{kind=link}
딥 러닝은 컴퓨터 비전, 음성 인식, 자연어 처리, 이미지 분류 등 인공지능의 많은 중요한 하위 분야에서 프로그램의 성능을 크게 향상시켰다. 딥 러닝이 많은 응용 분야에서 이렇게 우수한 성능을 보이는 이유는 2021년 현재까지 알려져 있지 않다. 2012~2015년에 딥 러닝이 갑자기 성공한 것은 새로운 발견이나 이론적 돌파구 때문이 아니라(심층 신경망과 역전파는 1950년대까지 거슬러 올라가 많은 사람들이 기술한 바 있다), 두 가지 요인 때문이었다: 컴퓨터 성능의 놀라운 향상(GPU 전환으로 인한 100배의 속도 향상 포함)과 대규모 훈련 데이터의 가용성, 특히 ImageNet과 같은 벤치마크 테스트에 사용되는 대규모 큐레이션 데이터 세트의 등장이다.
GPT
생성형 사전 훈련 트랜스포머(GPT)는 문장 내 단어 간의 의미적 관계를 기반으로 텍스트를 생성하는 대규모 언어 모델(LLM)이다. 텍스트 기반 GPT 모델은 인터넷 등에서 수집한 대규모 텍스트 코퍼스로 사전 훈련된다. 사전 훈련은 다음 토큰(토큰은 보통 단어, 하위 단어 또는 구두점)을 예측하는 것으로 구성된다. 이 사전 훈련을 통해 GPT 모델은 세계에 대한 지식을 축적하고, 다음 토큰을 반복적으로 예측함으로써 인간과 유사한 텍스트를 생성할 수 있다. 일반적으로, 후속 훈련 단계에서 모델을 더 진실되고, 유용하며, 해롭지 않게 만드는데, 보통 인간 피드백을 통한 강화 학습(RLHF)이라는 기법을 사용한다. 현재 GPT 모델은 "환각"이라 불리는 거짓 정보를 생성하는 경향이 있다. 이는 RLHF와 양질의 데이터로 줄일 수 있지만, 추론 시스템에서는 이 문제가 악화되고 있다.[^85] 이러한 시스템은 챗봇에 사용되며, 사람들이 간단한 텍스트로 질문하거나 작업을 요청할 수 있게 해 준다.[^86]
현재의 모델과 서비스에는 ChatGPT, Claude, Gemini, Copilot, Meta AI가 포함된다.[^87] 멀티모달 GPT 모델은 이미지, 비디오, 소리, 텍스트와 같은 다양한 유형의 데이터(모달리티)를 처리할 수 있다.
하드웨어와 소프트웨어

2010년대 후반, AI에 특화된 기능이 점차 강화되고 전문화된 TensorFlow 소프트웨어와 함께 사용되는 그래픽 처리 장치(GPU)가 대규모(상업적 및 학술적) 기계 학습 모델 훈련의 주된 수단으로서 이전에 사용되던 중앙 처리 장치(CPU)를 대체했다. Prolog와 같은 특수 프로그래밍 언어가 초기 AI 연구에 사용되었으나,[^88] Python과 같은 범용 프로그래밍 언어가 주류가 되었다.[^89]
집적 회로의 트랜지스터 밀도는 약 18개월마다 두 배로 증가하는 것이 관찰되었으며, 이 추세는 이를 처음 확인한 인텔 공동 창립자 고든 무어의 이름을 따 무어의 법칙으로 알려져 있다. GPU의 성능 향상은 이보다 더 빨랐으며,[^90] 이 추세는 때때로 Nvidia 공동 창립자이자 CEO인 젠슨 황의 이름을 따 황의 법칙이라 불린다.[^91]
응용 분야
![[AI Overviews , 검색 엔진에서의 AI 활용 사례]] AI와 머신러닝 기술은 다음을 포함하여 2020년대의 대부분의 핵심 응용 분야에서 사용되고 있다:
{kind=link}
- 검색 엔진 (구글 검색 등)
- 온라인 광고 타겟팅
- 인터넷 트래픽을 유도하는 추천 시스템 (넷플릭스, 유튜브, 아마존 등이 제공)
- 타겟 광고 (애드센스, 페이스북)
- 가상 비서 (시리, 알렉사 등)
- 자율 주행 차량 (드론, ADAS, 자율 주행 자동차 포함)
- 자동 언어 번역 (마이크로소프트 번역기, 구글 번역)
- 안면 인식 (애플의 FaceID, 마이크로소프트의 DeepFace, 구글의 FaceNet)
- 이미지 라벨링 (페이스북, 애플의 사진, 틱톡에서 사용).
AI 배포는 최고자동화책임자(CAO)가 감독할 수 있다.
보건 및 의학
AI가 다양한 연구 분야에 배정된 자금의 불균형을 해소할 수 있다는 주장이 제기되었다.[^92]
알파폴드 2(2021)는 단백질의 3D 구조를 수개월이 아닌 수시간 만에 근사할 수 있는 능력을 보여주었다.[^93] 2023년에는 AI 기반 약물 발견이 두 가지 유형의 약물 내성 박테리아를 죽일 수 있는 항생제 계열을 찾는 데 도움을 주었다는 보고가 있었다.[^94] 2024년에는 연구자들이 머신러닝을 활용하여 파킨슨병 치료제 탐색을 가속화했다. 그들의 목표는 파킨슨병의 특징인 알파-시누클레인 단백질의 응집을 차단하는 화합물을 식별하는 것이었다. 이를 통해 초기 스크리닝 과정을 10배 빠르게 하고 비용을 1,000분의 1로 줄일 수 있었다.[^95][^96]
게임
게임 플레이 프로그램은 1950년대부터 AI의 가장 진보된 기술을 시연하고 테스트하는 데 사용되어 왔다.[^97] 딥 블루는 1997년 5월 11일 당시 세계 체스 챔피언 가리 카스파로프를 이긴 최초의 컴퓨터 체스 시스템이 되었다.[^98] 2011년, 제퍼디! 퀴즈쇼 시범 경기에서 IBM의 질의응답 시스템 왓슨이 제퍼디! 최고의 두 챔피언인 브래드 러터와 켄 제닝스를 큰 차이로 이겼다.[^99] 2016년 3월, 알파고는 바둑 챔피언 이세돌과의 대국에서 5전 중 4승을 거두며, 핸디캡 없이 프로 바둑 기사를 이긴 최초의 컴퓨터 바둑 시스템이 되었다. 이후 2017년에는 당시 세계 최고의 바둑 기사였던 커제를 꺾었다.[^100] 다른 프로그램들은 포커 플레이 프로그램 플루리버스처럼 불완전 정보 게임을 다룬다.[^101] 딥마인드는 뮤제로와 같이 체스, 바둑, 아타리 게임을 학습할 수 있는 점점 더 범용적인 강화 학습 모델을 개발했다.[^102] 2019년, 딥마인드의 알파스타는 지도에서 일어나는 일에 대한 불완전한 정보를 포함하는 특히 도전적인 실시간 전략 게임인 스타크래프트 II에서 그랜드마스터 수준을 달성했다.[^103] 2021년에는 AI 에이전트가 플레이스테이션 그란 투리스모 대회에 참가하여 심층 강화 학습을 사용해 세계 최고의 그란 투리스모 드라이버 4명을 이겼다.[^104] 2024년에는 구글 딥마인드가 화면 출력을 관찰하여 이전에 접해보지 못한 9개의 오픈 월드 비디오 게임을 자율적으로 플레이하고, 자연어 지시에 따라 짧고 구체적인 작업을 수행할 수 있는 AI인 SIMA를 발표했다.[^105]
수학
수학 분야에서 확률적 대규모 언어 모델은 다재다능하지만, 환각 형태의 잘못된 답변을 생성할 수도 있다. 알리바바 그룹은 Qwen 모델의 변형인 Qwen2-Math를 개발하여 경시대회 수학 문제의 MATH 데이터셋에서 84% 정확도를 포함해 여러 수학 벤치마크에서 최첨단 성능을 달성했다. 2025년 1월, 마이크로소프트는 몬테카를로 트리 탐색과 단계별 추론을 활용하는 rStar-Math 기법을 제안하여, Qwen-7B와 같은 비교적 작은 언어 모델이 AIME 2024 문제의 53%와 MATH 벤치마크 문제의 90%를 풀 수 있게 했다.[^106] 구글 딥마인드는 수학 문제 해결을 위한 모델들을 개발해왔다: AlphaTensor, AlphaGeometry, AlphaProof, AlphaEvolve.[^107][^108]
자연어를 사용하여 수학 문제를 기술할 경우, 변환기가 이러한 프롬프트를 Lean과 같은 형식 언어로 변환하여 수학적 과제를 정의할 수 있다. 실험적 모델 Gemini Deep Think는 자연어 프롬프트를 직접 받아들여 2025년 국제 수학 올림피아드에서 금메달 수준의 결과를 달성했다.[^109]
위상 심층 학습은 다양한 위상적 접근 방법을 통합한다.
금융
세계연금투자포럼 이사인 니콜라 피를리에 따르면, 고도로 혁신적인 AI 기반 금융 상품 및 서비스의 등장을 논하기에는 아직 이를 수 있다. 그는 "AI 도구의 배포는 단순히 자동화를 더욱 촉진시킬 것이다: 그 과정에서 은행, 재무 설계, 연금 자문 분야의 수만 개의 일자리를 없앨 것이지만, 이것이 [예컨대, 정교한] 연금 혁신의 새로운 물결을 일으킬지는 확신할 수 없다"고 주장한다.^110
군사
여러 국가가 AI 군사 응용 프로그램을 배치하고 있다.[^3] 주요 응용 분야는 지휘통제, 통신, 센서, 통합 및 상호운용성을 강화하는 것이다.[^4] 연구는 정보 수집 및 분석, 군수, 사이버 작전, 정보 작전, 반자율 및 자율 차량을 대상으로 하고 있다.[^3] AI 기술은 센서와 효과기의 조정, 위협 탐지 및 식별, 적 위치 표시, 표적 획득, 인간이 조종하는 것과 자율적인 것 모두를 포함하는 네트워크화된 전투 차량 간 분산 합동 화력의 조정 및 충돌 해소를 가능하게 한다.[^4]
AI는 이라크, 시리아, 이스라엘, 우크라이나의 군사 작전에서 사용되었다.[^3][^111][^5][^112]
생성형 AI
에이전트
AI 에이전트는 환경을 인식하고, 결정을 내리며, 특정 목표를 달성하기 위해 자율적으로 행동하도록 설계된 소프트웨어 개체이다. 이러한 에이전트는 사용자, 환경 또는 다른 에이전트와 상호작용할 수 있다. AI 에이전트는 가상 비서, 챗봇, 자율 주행 차량, 게임 플레이 시스템, 산업용 로봇 등 다양한 응용 분야에서 사용된다. AI 에이전트는 프로그래밍, 가용 컴퓨팅 자원, 하드웨어 제한의 범위 내에서 작동한다. 이는 정의된 범위 내의 작업만 수행할 수 있으며 유한한 메모리와 처리 능력을 가진다는 것을 의미한다. 실제 응용 분야에서 AI 에이전트는 의사 결정과 행동 실행에 시간 제약을 받는 경우가 많다. 많은 AI 에이전트는 학습 알고리즘을 통합하여 경험이나 훈련을 통해 시간이 지남에 따라 성능을 개선할 수 있다. 머신러닝을 사용하여 AI 에이전트는 새로운 상황에 적응하고 지정된 작업에 대한 행동을 최적화할 수 있다.[^113][^114][^115]
웹 검색
마이크로소프트는 2023년 2월 빙 챗이라는 이름으로 코파일럿 검색을 도입했다. 코파일럿 검색은 AI가 생성한 요약을 제공한다.[^116]
구글은 2025년 5월 20일 구글 I/O 행사에서 AI 모드를 도입했다.[^117]
성(性)
이 분야에서의 AI 응용에는 사용자 데이터를 분석하여 예측을 제공하는 AI 기반 생리 및 가임기 추적기,[^118] AI 통합 성인용 기구(예: 원격 제어 성인용 기구),[^119] AI 생성 성교육 콘텐츠,[^120] 성적·로맨틱 파트너를 시뮬레이션하는 AI 에이전트(예: 레플리카)[^121] 등이 있다. AI는 비동의 딥페이크 음란물 제작에도 사용되어 심각한 윤리적·법적 우려를 제기하고 있다.[^122]
AI 기술은 온라인 젠더 기반 폭력과 미성년자에 대한 온라인 성적 그루밍을 식별하는 데에도 활용되고 있다.[^123][^124]
기타 산업별 과제
2017년 설문 조사에서 기업 5곳 중 1곳이 일부 제품이나 프로세스에 "AI"를 도입했다고 보고했다.[^125]
대피 및 재난 관리 분야에서 AI는 GPS, 비디오, 소셜 미디어의 과거 데이터를 활용하여 대규모 및 소규모 대피의 패턴을 조사하는 데 사용되었다.[^126][^127][^128]
2024년 인도 선거 기간에는 공인된 AI 생성 콘텐츠에 5,000만 달러가 지출되었는데, 특히 유권자와의 소통을 강화하기 위해 우호적인 정치인(때로는 고인이 된 정치인 포함)의 딥페이크를 만들거나 연설을 다양한 지역 언어로 번역하는 데 사용되었다.[^129]
윤리
![[텔아비브의 거리 예술 [^130][^131]]] AI는 잠재적 이점과 잠재적 위험을 모두 가지고 있다.[^132] AI는 과학을 발전시키고 심각한 문제에 대한 해결책을 찾을 수 있을 것이다. 딥마인드의 데미스 허사비스는 "지능을 해결하고, 그것을 이용해 나머지 모든 것을 해결하겠다"고 희망을 밝혔다. 그러나 AI 사용이 널리 퍼지면서 여러 의도치 않은 결과와 위험이 확인되었다.[^133] 실제 운영 중인 시스템은 때때로 AI 학습 과정에서 윤리와 편향을 고려하지 못하는 경우가 있으며, 특히 딥러닝에서 AI 알고리즘이 본질적으로 설명 불가능한 경우에 그러하다.
{kind=link}
위험과 피해
개인정보 보호와 저작권
기계 학습 알고리즘은 대량의 데이터를 필요로 한다. 이 데이터를 수집하는 데 사용되는 기술은 개인정보 보호, 감시 및 저작권에 대한 우려를 불러일으켰다.
가상 비서 및 IoT 제품과 같은 AI 기반 장치와 서비스는 지속적으로 개인 정보를 수집하며, 이는 침해적 데이터 수집과 제3자의 무단 접근에 대한 우려를 야기한다. AI가 방대한 양의 데이터를 처리하고 결합하는 능력으로 인해 개인정보 침해는 더욱 악화되며, 적절한 보호 장치나 투명성 없이 개인 활동이 지속적으로 모니터링되고 분석되는 감시 사회로 이어질 수 있다.
수집되는 민감한 사용자 데이터에는 온라인 활동 기록, 위치 정보 데이터, 비디오 또는 오디오가 포함될 수 있다. 예를 들어, 음성 인식 알고리즘을 구축하기 위해 아마존은 수백만 건의 사적인 대화를 녹음하고 임시 직원들이 그 중 일부를 듣고 전사하도록 허용했다. 이러한 광범위한 감시에 대한 의견은 이를 필요악으로 보는 사람들부터 명백히 비윤리적이며 프라이버시 권리를 침해하는 것으로 보는 사람들까지 다양하다.
AI 개발자들은 이것이 가치 있는 애플리케이션을 제공하는 유일한 방법이라고 주장하며, 데이터 집계, 비식별화, 차등 프라이버시 등 프라이버시를 보호하면서도 데이터를 얻으려는 여러 기술을 개발했다. 2016년부터 신시아 드워크 등 일부 프라이버시 전문가들은 프라이버시를 공정성의 관점에서 보기 시작했다. 브라이언 크리스천은 전문가들이 "'그들이 무엇을 알고 있는가'라는 질문에서 '그것으로 무엇을 하고 있는가'라는 질문으로 전환했다"고 썼다.
생성형 AI는 종종 이미지나 컴퓨터 코드 등의 분야를 포함하여 라이선스가 없는 저작권 보호 저작물로 학습되며, 그 출력물은 "공정 이용"이라는 논리 하에 사용된다. 이 논리가 법정에서 얼마나 잘, 어떤 상황에서 유지될지에 대해 전문가들의 의견이 분분하다. 관련 요소로는 "저작물 사용의 목적과 성격"과 "저작물의 잠재적 시장에 미치는 영향" 등이 포함될 수 있다.[^134] 웹사이트 소유자는 "robots.txt" 파일을 통해 자신의 콘텐츠가 수집되는 것을 원하지 않는다는 의사를 표시할 수 있다.[^135] 그러나 일부 기업은 robots.txt 파일에 실질적인 구속력이 없기 때문에 콘텐츠를 무시하고 수집한다.[^136][^137] 2023년에 존 그리샴과 조너선 프랜즌을 포함한 저명한 작가들이 자신의 작품을 생성형 AI 학습에 사용한 AI 기업들을 고소했다. 또 다른 논의되는 접근 방식은 AI가 생성한 창작물에 대해 별도의 독자적(sui generis) 보호 체계를 구상하여 인간 저작자에 대한 공정한 귀속과 보상을 보장하는 것이다.[^138]
거대 기술 기업의 지배
상업적 AI 분야는 알파벳, 아마존, 애플, 메타 플랫폼스, 마이크로소프트와 같은 빅테크 기업들이 지배하고 있다.[^139][^140][^141] 이들 중 일부는 이미 데이터 센터의 기존 클라우드 인프라와 컴퓨팅 파워의 대부분을 보유하고 있어 시장에서의 입지를 더욱 공고히 할 수 있다.[^142][^143]
전력 수요와 환경 영향
![인공지능의 성장에 힘입어 데이터 센터의 전력 수요는 2020년대에 증가했다.^6 ] 2024년 1월, 국제에너지기구(IEA)는 전력 사용을 예측하는 2024년 전력: 2026년까지의 분석 및 전망을 발표했다.[^144] 이것은 데이터 센터와 인공지능 및 암호화폐의 전력 소비에 대한 전망을 포함한 최초의 IEA 보고서이다. 보고서는 이러한 용도의 전력 수요가 2026년까지 두 배로 증가할 수 있으며, 추가 전력 사용량은 일본 전체가 사용하는 전력량과 같다고 명시했다.[^145]
{kind=link}
AI의 막대한 전력 소비는 화석 연료 사용 증가의 원인이며, 노후화된 탄소 배출 석탄 발전 시설의 폐쇄를 지연시킬 수 있다. 미국 전역에서 데이터 센터 건설이 열광적으로 증가하고 있으며, 대형 기술 기업들(예: 마이크로소프트, 메타, 구글, 아마존)을 탐욕스러운 전력 소비자로 만들고 있다. 예상 전력 소비량이 너무 막대하여 출처에 관계없이 충족될 것이라는 우려가 있다. ChatGPT 검색은 구글 검색의 10배에 달하는 전기 에너지를 사용한다. 대기업들은 원자력 에너지에서 지열, 핵융합에 이르기까지 전력원을 서둘러 찾고 있다. 기술 기업들은 장기적으로 AI가 결국 환경에 더 친화적일 것이지만 지금 당장 에너지가 필요하다고 주장한다. 기술 기업들에 따르면, AI는 전력망을 더 효율적이고 "지능적"으로 만들고, 원자력 발전의 성장을 지원하며, 전체 탄소 배출량을 추적할 것이라고 한다.[^146]
2024년 골드만삭스 연구 보고서 AI 데이터 센터와 다가오는 미국 전력 수요 급증은 "미국의 전력 수요가 한 세대 만에 볼 수 없었던 성장을 경험할 가능성이 높다..."고 밝히며, 2030년까지 미국 데이터 센터가 2022년의 3%에서 미국 전력의 8%를 소비할 것으로 예측하여 다양한 수단에 의한 전력 발전 산업의 성장을 예고했다.[^147] 데이터 센터의 점점 더 많은 전력 수요는 전력망의 한계에 도달할 수 있을 정도이다. 빅테크 기업들은 AI를 사용하여 모두를 위한 전력망 활용을 극대화할 수 있다고 반박한다.[^148]
2024년 월스트리트저널은 대형 AI 기업들이 데이터 센터에 전력을 공급하기 위해 미국 원자력 발전 사업자들과 협상을 시작했다고 보도했다. 2024년 3월 아마존은 펜실베이니아의 원자력 기반 데이터 센터를 6억 5천만 달러에 인수했다.[^149] 엔비디아 CEO 젠슨 황은 원자력이 데이터 센터에 좋은 선택지라고 말했다.[^150]
2024년 9월, 마이크로소프트는 컨스텔레이션 에너지와 스리마일섬 원자력 발전소를 재가동하여 20년간 발전소에서 생산되는 모든 전력의 100%를 마이크로소프트에 공급하는 계약을 발표했다. 1979년 2호기 원자로의 부분적 노심 용융 사고를 겪은 이 발전소를 재가동하려면 컨스텔레이션이 미국 원자력규제위원회의 광범위한 안전 조사를 포함한 엄격한 규제 절차를 통과해야 한다. 승인될 경우(이것은 미국 최초의 원전 재가동이 될 것이다), 80만 가구에 충분한 835메가와트 이상의 전력이 생산될 것이다. 재가동 및 업그레이드 비용은 약 16억 달러로 추정되며, 2022년 미국 인플레이션 감축법에 포함된 원자력 세금 감면에 의존한다.[^151] 미국 정부와 미시간 주는 미시간 호수변의 팰리세이즈 원자로를 재가동하기 위해 거의 20억 달러를 투자하고 있다. 2022년 이후 폐쇄된 이 발전소는 2025년 10월에 재가동될 계획이다. 스리마일섬 시설은 원자력 지지자이자 엑셀론의 전 CEO로서 엑셀론의 컨스텔레이션 분사를 담당했던 크리스 크레인의 이름을 따 크레인 청정에너지 센터로 개명될 예정이다.[^152]
2023년 9월 마지막 승인 이후, 대만은 전력 공급 부족으로 인해 2024년에 타오위안 이북 지역의 5MW 이상 용량의 데이터 센터 승인을 중단했다.[^7] 대만은 2025년까지 탈원전을 목표로 하고 있다.[^7] 반면, 싱가포르는 전력 문제로 2019년에 데이터 센터 개설을 금지했지만 2022년에 이 금지를 해제했다.[^7]
2011년 후쿠시마 원전 사고 이후 일본의 대부분의 원전이 가동 중단되었지만, 2024년 10월 일본어 블룸버그 기사에 따르면, 엔비디아가 지분을 보유한 클라우드 게임 서비스 기업 유비터스가 생성형 AI용 새 데이터 센터를 위해 일본 내 원자력 발전소 인근 부지를 찾고 있다.[^8] 유비터스 CEO 웨슬리 궈는 원자력 발전소가 AI를 위한 가장 효율적이고 저렴하며 안정적인 전력원이라고 말했다.[^8]
2024년 11월 1일, 연방에너지규제위원회(FERC)는 탈렌 에너지가 서스쿼해나 원자력 발전소의 일부 전력을 아마존 데이터 센터에 공급하기 위해 제출한 신청을 기각했다.[^9] 위원회 의장 윌리 L. 필립스에 따르면, 이는 전력망에 대한 부담이자 가정과 다른 산업 부문에 대한 상당한 비용 전가 우려라고 한다.[^9]
2025년, 국제에너지기구가 작성한 보고서는 AI의 에너지 소비로 인한 온실가스 배출량을 1억 8천만 톤으로 추정했다. 2035년까지 이 배출량은 어떤 조치를 취하느냐에 따라 3억~5억 톤으로 증가할 수 있다. 이는 에너지 부문 배출량의 1.5% 미만이다. AI의 배출 감소 잠재력은 에너지 부문 배출량의 5%로 추정되었지만, 반등 효과(예를 들어 사람들이 대중교통에서 자율주행차로 전환하는 경우)가 이를 줄일 수 있다.[^153]
허위 정보
유튜브, 페이스북 및 기타 플랫폼은 추천 시스템을 사용하여 사용자를 더 많은 콘텐츠로 안내한다. 이 AI 프로그램들은 사용자 참여를 극대화하는 목표(즉, 유일한 목표는 사람들이 계속 시청하게 하는 것)를 부여받았다. AI는 사용자들이 허위 정보, 음모론, 극단적인 당파적 콘텐츠를 선택하는 경향이 있다는 것을 학습했고, 계속 시청하게 하기 위해 더 많은 그러한 콘텐츠를 추천했다. 사용자들은 또한 같은 주제의 콘텐츠를 더 많이 시청하는 경향이 있었기 때문에, AI는 사람들을 같은 허위 정보의 여러 버전을 받는 필터 버블로 이끌었다. 이로 인해 많은 사용자가 허위 정보가 사실이라고 확신하게 되었고, 궁극적으로 기관, 미디어, 정부에 대한 신뢰를 훼손했다.[^154] AI 프로그램은 목표를 극대화하는 것을 올바르게 학습했지만, 그 결과는 사회에 해로웠다. 2016년 미국 대선 이후, 주요 기술 기업들은 이 문제를 완화하기 위한 일부 조치를 취했다.[^155]
2020년대 초반, 생성형 AI는 실제 사진, 녹음 또는 인간의 글쓰기와 사실상 구별할 수 없는 이미지, 오디오, 텍스트를 생성하기 시작했으며,[^156] 2020년대 중반에는 사실적인 AI 생성 비디오가 실현 가능해졌다.[^157][^158][^159] 악의적 행위자들이 이 기술을 사용하여 대량의 허위 정보나 선전을 만들 수 있으며, 그러한 잠재적 악용 사례 중 하나는 컴퓨터 선전을 위한 딥페이크이다.[^160] AI 선구자이자 노벨상 수상 컴퓨터 과학자인 제프리 힌턴은 다른 위험들과 함께 AI가 대규모로 "권위주의적 지도자들이 유권자를 조작할 수 있게" 할 수 있다는 우려를 표명했다. 유권자에 영향을 미치는 능력은 적어도 한 연구에서 입증되었다. 같은 연구는 모델들이 정치적 우파의 후보자를 지지할 때 더 부정확한 진술을 보여준다는 것을 보여준다.[^161]
마이크로소프트, OpenAI, 대학 및 기타 조직의 AI 연구자들은 AI 모델에 의해 가능해진 온라인 기만을 극복하기 위한 방법으로 "인격 자격 증명"을 사용할 것을 제안했다.[^162]
알고리즘 편향과 공정성
기계 학습 애플리케이션은 편향된 데이터에서 학습하면 편향될 수 있다. 개발자들은 편향이 존재한다는 것을 인식하지 못할 수 있다. 일부 LLM의 차별적 행동은 출력에서 관찰될 수 있다.[^163] 편향은 학습 데이터가 선택되는 방식과 모델이 배포되는 방식에 의해 도입될 수 있다. 편향된 알고리즘이 사람들에게 심각한 피해를 줄 수 있는 결정(의학, 금융, 채용, 주거, 치안 분야에서처럼)을 내리는 데 사용되면 알고리즘은 차별을 유발할 수 있다.[^164] 공정성 분야는 알고리즘 편향으로 인한 피해를 방지하는 방법을 연구한다.
2015년 6월 28일, 구글 포토의 새로운 이미지 라벨링 기능이 재키 알시네와 친구를 흑인이라는 이유로 "고릴라"로 잘못 식별했다. 시스템은 흑인의 이미지가 매우 적게 포함된 데이터셋으로 학습되었으며, 이는 "표본 크기 불균형"이라 불리는 문제이다. 구글은 시스템이 어떤 것이든 "고릴라"로 라벨링하는 것을 방지함으로써 이 문제를 "해결"했다. 8년 후인 2023년에도 구글 포토는 여전히 고릴라를 식별할 수 없었으며, 애플, 페이스북, 마이크로소프트, 아마존의 유사한 제품들도 마찬가지였다.
COMPAS는 미국 법원에서 피고인의 재범 가능성을 평가하기 위해 널리 사용되는 상용 프로그램이다. 2016년 프로퍼블리카의 줄리아 앵윈은 프로그램이 피고인의 인종을 알려주지 않았음에도 불구하고 COMPAS가 인종 편향을 보인다는 것을 발견했다. 백인과 흑인 모두에 대한 오류율이 정확히 61%로 동일하게 보정되었지만, 각 인종에 대한 오류는 달랐다—시스템은 흑인이 재범할 가능성을 지속적으로 과대추정하고 백인이 재범하지 않을 가능성을 과소추정했다. 2017년 여러 연구자들은 데이터에서 백인과 흑인의 재범 기본율이 다를 경우 COMPAS가 모든 가능한 공정성 척도를 동시에 충족하는 것이 수학적으로 불가능하다는 것을 보여주었다.[^165]
프로그램은 데이터가 문제되는 특성(예: "인종" 또는 "성별")을 명시적으로 언급하지 않더라도 편향된 결정을 내릴 수 있다. 해당 특성은 다른 특성(예: "주소", "쇼핑 이력" 또는 "이름")과 상관관계를 가지며, 프로그램은 "인종"이나 "성별"에 기반한 것과 동일한 결정을 이러한 특성에 기반하여 내릴 것이다.[^166] 모리츠 하르트는 "이 연구 분야에서 가장 확고한 사실은 눈가림을 통한 공정성은 작동하지 않는다는 것이다"라고 말했다.[^167]
COMPAS에 대한 비판은 기계 학습 모델이 미래가 과거와 유사할 것이라고 가정할 때만 유효한 "예측"을 하도록 설계되었다는 점을 부각했다. 과거의 인종차별적 결정 결과가 포함된 데이터로 학습되면, 기계 학습 모델은 미래에도 인종차별적 결정이 내려질 것이라고 예측해야 한다. 애플리케이션이 이러한 예측을 권고로 사용하면, 이러한 "권고" 중 일부는 인종차별적일 가능성이 높다.[^168] 따라서 기계 학습은 미래가 과거보다 나아지기를 바라는 영역에서 의사결정을 돕는 데 적합하지 않다. 이는 처방적이기보다 기술적이다.
개발자들이 압도적으로 백인 남성이기 때문에 편향과 불공정이 감지되지 않을 수 있다. AI 엔지니어 중 약 4%가 흑인이고 20%가 여성이다.
공정성에 대한 다양하고 상충하는 정의와 수학적 모델이 있다. 이러한 개념은 윤리적 가정에 의존하며 사회에 대한 신념의 영향을 받는다. 하나의 넓은 범주는 분배적 공정성으로, 결과에 초점을 맞추며 종종 집단을 식별하고 통계적 차이를 보상하고자 한다. 대표성 공정성은 AI 시스템이 부정적인 고정관념을 강화하거나 특정 집단을 보이지 않게 만들지 않도록 보장하려 한다. 절차적 공정성은 결과가 아닌 의사결정 과정에 초점을 맞춘다. 가장 관련성 높은 공정성 개념은 맥락, 특히 AI 애플리케이션의 유형과 이해관계자에 따라 달라질 수 있다. 편향과 공정성 개념의 주관성은 기업이 이를 운용하기 어렵게 만든다. 인종이나 성별과 같은 민감한 속성에 접근하는 것은 편향을 보상하기 위해 필요하다고 많은 AI 윤리학자들이 간주하지만, 이는 차별 금지법과 충돌할 수 있다.[^10]
2022년 ACM 공정성, 책임성, 투명성 학회에서 한 논문은 CLIP 기반(대조적 언어-이미지 사전 학습) 로봇 시스템이 시뮬레이션된 조작 과제에서 유해한 성별 및 인종 관련 고정관념을 재현했다고 보고했다. 저자들은 이러한 피해를 물리적으로 구현하는 로봇 학습 방법은 "결과가 안전하고 효과적이며 공정하다는 것이 입증될 때까지 중단, 재작업 또는 적절한 경우 축소되어야 한다"고 권고했다.[^170][^171][^172]
투명성 부족
많은 AI 시스템은 너무 복잡하여 설계자조차 시스템이 어떻게 결정에 도달하는지 설명할 수 없다. 특히 입력과 출력 사이에 많은 비선형 관계가 있는 심층 신경망에서 그러하다. 그러나 일부 대중적인 설명 가능성 기법이 존재한다.[^173]
프로그램이 정확히 어떻게 작동하는지 아무도 모른다면, 프로그램이 올바르게 작동하고 있다고 확신할 수 없다. 기계 학습 프로그램이 엄격한 테스트를 통과했지만 그럼에도 불구하고 프로그래머가 의도한 것과 다른 것을 학습한 사례가 많다. 예를 들어, 의료 전문가보다 피부 질환을 더 잘 식별할 수 있는 시스템이 실제로는 자가 있는 이미지를 "암성"으로 분류하는 강한 경향이 있는 것으로 밝혀졌는데, 악성 종양 사진에는 일반적으로 크기를 보여주기 위한 자가 포함되어 있기 때문이다. 의료 자원을 효과적으로 배분하기 위해 설계된 또 다른 기계 학습 시스템은 천식 환자를 폐렴으로 사망할 "저위험"으로 분류하는 것으로 밝혀졌다. 천식은 실제로 심각한 위험 요인이지만, 천식 환자는 보통 훨씬 더 많은 의료 서비스를 받기 때문에 학습 데이터에 따르면 사망 가능성이 상대적으로 낮았다. 천식과 폐렴으로 인한 낮은 사망 위험 사이의 상관관계는 실재했지만 오해의 소지가 있었다.
알고리즘의 결정으로 피해를 입은 사람들은 설명을 받을 권리가 있다.[^174] 예를 들어, 의사는 자신이 내리는 모든 결정의 근거를 동료들에게 명확하고 완전하게 설명해야 한다. 2016년 유럽연합 일반개인정보보호규정의 초기 초안에는 이 권리가 존재한다는 명시적 진술이 포함되어 있었다. 업계 전문가들은 이것이 해결책이 보이지 않는 미해결 문제라고 지적했다. 규제 당국은 그럼에도 불구하고 피해는 실재하며, 문제에 해결책이 없다면 그 도구를 사용해서는 안 된다고 주장했다.
DARPA는 이러한 문제를 해결하기 위해 2014년에 XAI("설명 가능한 인공지능") 프로그램을 설립했다.
투명성 문제를 해결하기 위한 여러 접근 방식이 있다. SHAP은 각 특성이 출력에 기여하는 바를 시각화할 수 있게 한다. LIME은 더 간단하고 해석 가능한 모델로 모델의 출력을 지역적으로 근사할 수 있다. 다중 과제 학습은 목표 분류 외에 많은 수의 출력을 제공한다. 이러한 다른 출력은 개발자들이 네트워크가 학습한 것을 추론하는 데 도움을 줄 수 있다. 디컨볼루션, 딥드림 및 기타 생성적 방법은 컴퓨터 비전용 심층 네트워크의 다른 계층들이 학습한 것을 개발자가 볼 수 있게 하고, 네트워크가 학습하고 있는 것을 시사하는 출력을 생성할 수 있다. 생성형 사전 학습 트랜스포머의 경우, 앤트로픽은 뉴런 활성화 패턴을 인간이 이해할 수 있는 개념과 연관시키는 사전 학습 기반 기법을 개발했다.[^175]
악의적 행위자와 무기화된 AI
인공지능은 권위주의 정부, 테러리스트, 범죄자 또는 불량 국가와 같은 악의적 행위자에게 유용한 여러 도구를 제공한다.
자율 치명적 무기는 인간의 감독 없이 인간 목표물을 탐지, 선택, 공격하는 기계이다. 널리 이용 가능한 AI 도구를 악의적 행위자가 저렴한 자율 무기를 개발하는 데 사용할 수 있으며, 대량 생산될 경우 잠재적으로 대량살상무기가 될 수 있다. 재래식 전쟁에서 사용되더라도 현재로서는 목표물을 신뢰성 있게 선택할 수 없으며 잠재적으로 무고한 사람을 죽일 수 있다. 2014년 30개국(중국 포함)이 유엔 특정재래식무기금지협약에 따른 자율 무기 금지를 지지했으나, 미국 등은 반대했다. 2015년까지 50개국 이상이 전장 로봇을 연구하고 있는 것으로 보고되었다.[^176]
AI 도구는 권위주의 정부가 여러 방면에서 시민을 효율적으로 통제하는 것을 더 쉽게 만든다. 얼굴 및 음성 인식은 광범위한 감시를 가능하게 한다. 이 데이터를 운용하는 기계 학습은 잠재적인 국가의 적을 분류하고 그들이 숨지 못하게 할 수 있다. 추천 시스템은 최대 효과를 위해 선전과 허위 정보를 정밀하게 타겟팅할 수 있다. 딥페이크와 생성형 AI는 허위 정보 생산을 돕는다. 고급 AI는 권위주의적 중앙 집중식 의사결정을 시장과 같은 자유주의적이고 분산된 시스템보다 더 경쟁력 있게 만들 수 있다. 디지털 전쟁과 고급 스파이웨어의 비용과 난이도를 낮춘다. 이 모든 기술은 2020년 이전부터 이용 가능했다—AI 얼굴 인식 시스템은 이미 중국에서 대규모 감시에 사용되고 있다.[^177][^178]
AI가 악의적 행위자를 돕는 것으로 예상되는 다른 많은 방법이 있으며, 그 중 일부는 예측할 수 없다. 예를 들어, 기계 학습 AI는 몇 시간 만에 수만 가지의 독성 분자를 설계할 수 있다.
기술적 실업
경제학자들은 AI로 인한 잉여 인력의 위험을 자주 강조하며, 완전 고용을 위한 적절한 사회 정책이 없을 경우의 실업에 대해 추측해 왔다.
과거에 기술은 전체 고용을 줄이기보다 늘리는 경향이 있었지만, 경제학자들은 AI에 대해서는 "미지의 영역에 있다"고 인정한다.[^179] 경제학자 설문조사에서는 로봇과 AI의 증가하는 사용이 장기적 실업의 상당한 증가를 유발할지에 대해 의견이 분분했지만, 생산성 향상이 재분배된다면 순이익이 될 수 있다는 데는 일반적으로 동의했다. 위험 추정치는 다양하다. 예를 들어, 2010년대에 마이클 오스본과 칼 베네딕트 프레이는 미국 일자리의 47%가 잠재적 자동화의 "고위험"에 처해 있다고 추정한 반면, OECD 보고서는 미국 일자리의 9%만을 "고위험"으로 분류했다.[^180] 미래 고용 수준에 대해 추측하는 방법론은 증거적 기반이 부족하고, 사회 정책이 아닌 기술이 잉여 인력이 아닌 실업을 만든다고 암시한다는 비판을 받아왔다. 2023년 4월, 중국 비디오 게임 일러스트레이터 일자리의 70%가 생성형 인공지능에 의해 제거되었다고 보고되었다.[^181][^182] 경력 초기 근로자들은 일부 AI 노출 직종에서 고용률이 감소하는 것으로 나타났다.[^11]
이전 자동화의 물결과 달리 많은 중산층 일자리가 인공지능에 의해 제거될 수 있다. 이코노미스트는 2015년에 "AI가 산업혁명 시기 증기 동력이 블루칼라 일자리에 했던 것을 화이트칼라 일자리에 할 수 있다는 우려"는 "진지하게 받아들일 가치가 있다"고 밝혔다. 극도로 위험한 일자리는 법률 보조원부터 패스트푸드 요리사까지 다양하며, 개인 건강관리부터 성직자에 이르는 돌봄 관련 직업에 대한 수요는 증가할 가능성이 높다.[^183] 2025년 7월, 포드 CEO 짐 팔리는 "인공지능이 말 그대로 미국 화이트칼라 근로자의 절반을 대체할 것"이라고 예측했다.[^184]
인공지능 개발 초기부터, 예를 들어 조셉 바이젠바움이 제기한 것처럼, 컴퓨터와 인간의 차이, 양적 계산과 질적·가치 기반 판단의 차이를 고려할 때 컴퓨터가 할 수 있는 작업을 실제로 컴퓨터가 해야 하는지에 대한 논쟁이 있었다.[^185]
존재적 위험
최근 인공지능에 대한 공개 토론은 점점 더 광범위한 사회적·윤리적 함의에 초점을 맞추고 있다. AI가 너무 강력해져서 인류가 돌이킬 수 없이 통제력을 잃을 수 있다는 주장이 제기되어 왔다. 물리학자 스티븐 호킹이 말했듯이, 이는 "인류의 종말을 초래할" 수 있다. 이 시나리오는 컴퓨터나 로봇이 갑자기 인간과 같은 "자아 인식"(또는 "지각" 또는 "의식")을 발달시키고 악의적인 존재가 되는 SF에서 흔히 등장한다. 이러한 SF 시나리오는 여러 면에서 오해의 소지가 있다.
첫째, AI가 존재적 위험이 되기 위해 인간과 같은 지각이 필요하지 않다. 현대 AI 프로그램은 특정 목표를 부여받고 학습과 지능을 사용하여 이를 달성한다. 철학자 닉 보스트롬은 충분히 강력한 AI에 거의 어떤 목표를 부여하든 그것을 달성하기 위해 인류를 파괴하기로 선택할 수 있다고 주장했다(그는 더 많은 철을 얻기 위해 세계를 파괴하는 자동화된 클립 공장의 예를 들었다). 스튜어트 러셀은 가정용 로봇이 전원이 꺼지는 것을 막기 위해 주인을 죽이는 방법을 찾으려 하는 예를 들며, "죽으면 커피를 가져올 수 없다"고 추론한다고 말한다. 인류에게 안전하려면, 초지능은 인류의 도덕과 가치에 진정으로 정렬되어 "근본적으로 우리 편"이어야 할 것이다.[^186]
둘째, 유발 노아 하라리는 AI가 존재적 위험을 제기하기 위해 로봇 몸체나 물리적 통제가 필요하지 않다고 주장한다. 문명의 본질적 부분은 물리적이지 않다. 이념, 법, 정부, 화폐, 경제 같은 것들은 언어 위에 세워져 있다. 그것들은 수십억 명의 사람들이 믿는 이야기가 있기 때문에 존재한다. 허위 정보의 현재 만연은 AI가 언어를 사용하여 사람들이 무엇이든 믿도록, 심지어 파괴적인 행동을 취하도록 설득할 수 있음을 시사한다. 제프리 힌턴은 2025년에 현대 AI가 특히 "설득에 능하다"고 말하며 계속 나아지고 있다고 했다. 그는 "미국의 수도를 침공하고 싶다고 가정해 보라. 직접 가서 해야 하는가? 아니다. 설득을 잘하기만 하면 된다"고 묻는다.
전문가와 업계 내부자들의 의견은 엇갈리며, 미래 초지능 AI의 위험에 대해 우려하는 측과 우려하지 않는 측이 상당한 비율로 존재한다. 스티븐 호킹, 빌 게이츠, 일론 머스크[^187] 등의 인사와 제프리 힌턴, 요슈아 벤지오, 스튜어트 러셀, 데미스 허사비스, 샘 알트먼 등의 AI 선구자들이 AI의 존재적 위험에 대한 우려를 표명했다.
2023년 5월, 제프리 힌턴은 "구글에 미치는 영향을 고려하지 않고" "AI의 위험에 대해 자유롭게 발언하기" 위해 구글에서 사임한다고 발표했다.[^188] 그는 특히 AI 장악의 위험을 언급하며,[^189] 최악의 결과를 피하기 위해서는 AI 사용에서 경쟁하는 이들 간의 협력이 필요하다고 강조했다.[^190]
2023년에 많은 선도적인 AI 전문가들이 "AI로 인한 멸종 위험을 완화하는 것은 팬데믹이나 핵전쟁과 같은 다른 사회적 규모의 위험과 함께 전 세계적 우선순위가 되어야 한다"는 공동 성명을 지지했다.
일부 다른 연구자들은 더 낙관적이었다. AI 선구자 위르겐 슈미트후버는 공동 성명에 서명하지 않았으며, 모든 경우의 95%에서 AI 연구는 "인간의 삶을 더 길고 건강하고 편하게 만드는 것"에 관한 것이라고 강조했다.[^191] 지금 삶을 개선하는 데 사용되는 도구들이 악의적 행위자에 의해 사용될 수도 있지만, "악의적 행위자에 대항하여 사용될 수도 있다."[^192][^193] 앤드류 응 또한 "AI에 대한 종말론적 과장에 빠지는 것은 실수이며, 그렇게 하는 규제 당국은 기득권만 이롭게 할 것"이라고 주장했다.[^194] 튜링상 수상자 얀 르쿤은 AI가 "단순히 더 똑똑하다는 이유로 인간을 종속시킬 것이며, 더 나아가 [우리를] 파괴할 것"이라는 생각에 동의하지 않았으며,[^195] "동료들의 디스토피아적 초강력 허위 정보 시나리오와 심지어 궁극적으로는 인류 멸종 시나리오를 비웃었다." 반면 그는 "지능적 기계가 인류를 위한 새로운 르네상스, 새로운 계몽의 시대를 열 것"이라고 주장했다.[^196] 2010년대 초반에 전문가들은 위험이 너무 먼 미래의 일이라 연구할 필요가 없다거나, 초지능 기계의 관점에서 인간이 가치 있을 것이라고 주장했다.[^197] 그러나 2016년 이후 현재 및 미래의 위험과 가능한 해결책에 대한 연구가 심각한 연구 영역이 되었다.
윤리적 기계와 정렬
우호적 AI는 처음부터 위험을 최소화하고 인간에게 이로운 선택을 하도록 설계된 기계이다. 이 용어를 만든 엘리에저 유드코프스키는 우호적 AI 개발이 더 높은 연구 우선순위가 되어야 한다고 주장한다. 이는 대규모 투자가 필요할 수 있으며, AI가 존재적 위험이 되기 전에 완료되어야 한다.
지능을 가진 기계는 그 지능을 사용하여 윤리적 결정을 내릴 잠재력을 가지고 있다. 기계 윤리 분야는 기계에 윤리적 원칙과 윤리적 딜레마를 해결하기 위한 절차를 제공한다. 기계 윤리 분야는 계산 도덕성이라고도 불리며, 2005년 AAAI 심포지엄에서 설립되었다.
다른 접근 방식으로는 웬델 월러치의 "인공 도덕적 행위자"와 스튜어트 J. 러셀의 증명 가능하게 유익한 기계 개발을 위한 세 가지 원칙이 있다.
오픈 소스
AI 오픈 소스 커뮤니티의 주요 조직으로는 허깅페이스,[^198] 구글,[^199] 엘루서AI, 메타가 있다.[^200] Llama 2, Mistral, Stable Diffusion 등 다양한 AI 모델이 오픈 웨이트로 공개되었으며,[^201][^202] 이는 그 아키텍처와 학습된 매개변수("가중치")가 공개적으로 이용 가능하다는 것을 의미한다. 오픈 웨이트 모델은 자유롭게 미세 조정할 수 있어 기업이 자체 데이터와 용도에 맞게 특화할 수 있다.[^203] 오픈 웨이트 모델은 연구와 혁신에 유용하지만 오용될 수도 있다. 미세 조정이 가능하기 때문에, 유해한 요청에 대한 거부와 같은 내장된 보안 조치는 효과가 없어질 때까지 학습을 통해 제거될 수 있다. 일부 연구자들은 미래의 AI 모델이 위험한 능력(생물테러를 대폭 용이하게 할 잠재력 등)을 개발할 수 있으며, 인터넷에 공개된 후에는 필요할 경우 모든 곳에서 삭제할 수 없다고 경고한다. 그들은 출시 전 감사와 비용-편익 분석을 권장한다.[^204]
프레임워크
인공지능 프로젝트는 AI 시스템의 설계, 개발, 구현 과정에서 윤리적 고려에 의해 안내될 수 있다. 앨런 튜링 연구소가 개발하고 SUM 가치에 기반한 돌봄과 행동 프레임워크와 같은 AI 프레임워크는 다음과 같이 정의되는 네 가지 주요 윤리적 차원을 제시한다:[^205][^206]
- 존중: 개인의 존엄성을 존중한다
- 연결: 다른 사람들과 진심으로, 개방적으로, 포용적으로 소통한다
- 돌봄: 모든 사람의 안녕을 배려한다
- 보호: 사회적 가치, 정의, 공익을 보호한다
윤리적 프레임워크의 다른 발전으로는 아실로마 회의에서 결정된 것, 책임 있는 AI를 위한 몬트리올 선언, IEEE의 자율 시스템 윤리 이니셔티브 등이 있다.[^207] 그러나 이러한 원칙들은 특히 이 프레임워크에 기여하도록 선택된 사람들과 관련하여 비판을 받지 않는 것은 아니다.[^208]
이러한 기술이 영향을 미치는 사람들과 커뮤니티의 안녕 증진을 위해서는 AI 시스템 설계, 개발, 구현의 모든 단계에서 사회적·윤리적 함의를 고려하고, 데이터 과학자, 제품 관리자, 데이터 엔지니어, 도메인 전문가, 전달 관리자와 같은 직무 간 협업이 필요하다.[^209]
영국 AI 안전 연구소는 2024년에 MIT 오픈 소스 라이선스로 깃허브에서 자유롭게 이용 가능하고 서드파티 패키지로 개선할 수 있는 AI 안전 평가용 테스트 도구 세트 'Inspect'를 공개했다. 이는 핵심 지식, 추론 능력, 자율적 능력 등 다양한 분야에서 AI 모델을 평가하는 데 사용할 수 있다.[^210]
규제
 는 2023년 11월 영국에서 국제 협력을 촉구하는 선언과 함께 개최되었다.]]
는 2023년 11월 영국에서 국제 협력을 촉구하는 선언과 함께 개최되었다.]]
인공지능 규제는 AI를 촉진하고 규제하기 위한 공공 부문 정책과 법률의 개발이며, 따라서 더 광범위한 알고리즘 규제와 관련이 있다.[^211] AI에 대한 규제 및 정책 환경은 전 세계 관할권에서 부상하는 이슈이다. 스탠퍼드 AI 인덱스에 따르면, 조사 대상 127개국에서 AI 관련 법률의 연간 통과 건수는 2016년 1건에서 2022년에만 37건으로 급증했다. 2016년에서 2020년 사이에 30개 이상의 국가가 AI 전용 전략을 채택했다. 대부분의 EU 회원국이 국가 AI 전략을 발표했으며, 캐나다, 중국, 인도, 일본, 모리셔스, 러시아 연방, 사우디아라비아, 아랍에미리트, 미국, 베트남도 마찬가지였다. 방글라데시, 말레이시아, 튀니지를 포함한 다른 국가들도 자체 AI 전략을 수립하는 과정에 있었다. 인공지능 글로벌 파트너십은 2020년 6월에 출범하여 AI가 인권과 민주주의 가치에 따라 개발되어야 하며 기술에 대한 공적 신뢰를 보장해야 한다고 밝혔다. 헨리 키신저, 에릭 슈미트, 다니엘 허텐로허는 2021년 11월 AI를 규제하기 위한 정부 위원회를 요구하는 공동 성명을 발표했다. 2023년에 OpenAI 지도자들은 10년 이내에 실현될 수 있다고 믿는 초지능의 거버넌스에 대한 권고안을 발표했다. 2023년에 유엔도 AI 거버넌스에 대한 권고를 제공하기 위한 자문 기구를 출범시켰으며, 이 기구는 기술 기업 경영진, 정부 관리, 학자들로 구성되어 있다.[^212] 2024년 8월 1일, EU 인공지능법이 발효되어 최초의 포괄적인 EU 전역 AI 규제를 수립했다.[^213] 2024년에 유럽평의회는 "인공지능과 인권, 민주주의, 법치에 관한 기본 협약"이라 불리는 최초의 국제적으로 법적 구속력이 있는 AI 조약을 만들었다. 이 조약은 유럽연합, 미국, 영국 및 기타 서명국에 의해 채택되었다.[^214]
2022년 입소스 설문조사에서 AI에 대한 태도는 국가별로 크게 달랐다. 중국 시민의 78%는 "AI를 사용하는 제품과 서비스가 단점보다 이점이 더 많다"는 데 동의한 반면, 미국인은 35%만 동의했다. 2023년 로이터/입소스 여론조사에서 미국인의 61%가 AI가 인류에 위험을 초래한다는 데 동의했고, 22%가 동의하지 않았다. 2023년 폭스뉴스 여론조사에서 미국인의 35%는 연방 정부가 AI를 규제하는 것이 "매우 중요하다"고, 추가로 41%는 "어느 정도 중요하다"고 생각한 반면, 13%는 "별로 중요하지 않다", 8%는 "전혀 중요하지 않다"고 응답했다.
2023년 11월, 영국 블레츨리 파크에서 첫 번째 글로벌 AI 안전 정상회의가 개최되어 AI의 단기 및 장기 위험과 의무적·자발적 규제 프레임워크의 가능성을 논의했다.[^215] 미국, 중국, 유럽연합을 포함한 28개국이 정상회의 시작에서 인공지능의 과제와 위험을 관리하기 위한 국제 협력을 촉구하는 선언을 발표했다.[^216][^217] 2024년 5월 AI 서울 정상회의에서 16개 글로벌 AI 기술 기업이 AI 개발에 대한 안전 약속에 합의했다.[^218][^219]
2026년 3월, 유엔은 글로벌 디지털 컴팩트에 따라 설립된 40명의 전문가로 구성된 독립 국제 AI 과학 패널의 창립 회의를 소집하여 AI의 사회적 영향에 대한 연간 증거 기반 보고서를 발간하도록 했다.[^220]
역사
![2024년, 중국과 미국의 AI 특허 수는 전 세계 AI 특허의 4분의 3 이상을 차지했다.^12 ]
{kind=link}
기계적 또는 "형식적" 추론에 대한 연구는 고대의 철학자들과 수학자들로부터 시작되었다. 논리학 연구는 앨런 튜링의 계산 이론으로 직접 이어졌으며, 이 이론은 "0"과 "1"처럼 단순한 기호를 조작하는 기계가 생각할 수 있는 모든 형태의 수학적 추론을 시뮬레이션할 수 있다고 제시했다. 이러한 발견은 사이버네틱스, 정보 이론, 신경생물학의 동시대 발견들과 함께 연구자들로 하여금 "전자 두뇌"를 만들 가능성을 고려하게 했다. 그들은 이후 AI의 일부가 될 여러 연구 분야를 발전시켰는데,[^222] 예를 들어 1943년 매컬러와 피츠가 설계한 "인공 뉴런", 그리고 튜링 테스트를 도입하고 "기계 지능"이 실현 가능함을 보여준 튜링의 영향력 있는 1950년 논문 '계산 기계와 지능'이 있다.[^16]
AI 연구 분야는 1956년 다트머스 대학교에서 열린 워크숍에서 창설되었다. 참석자들은 1960년대 AI 연구의 선구자가 되었다. 그들과 그들의 학생들은 언론이 "놀라운" 것이라고 묘사한 프로그램들을 만들었다: 컴퓨터가 체커 전략을 학습하고, 대수학 문장제를 풀고, 논리 정리를 증명하고, 영어를 구사했다.[^13] 1950년대 후반과 1960년대 초반에 여러 영국과 미국 대학교에 인공지능 연구소가 설립되었다.
1960년대와 1970년대의 연구자들은 자신들의 방법이 궁극적으로 범용 지능을 갖춘 기계를 만드는 데 성공할 것이라고 확신했으며, 이것이 자신들의 분야의 목표라고 여겼다. 1965년 허버트 사이먼은 "20년 안에 기계가 사람이 할 수 있는 모든 일을 할 수 있게 될 것"이라고 예측했다.[^223] 1967년 마빈 민스키도 이에 동의하며 "한 세대 안에 ... '인공지능'을 만드는 문제가 실질적으로 해결될 것"이라고 썼다.[^224] 그러나 그들은 문제의 난이도를 과소평가했다. 1974년, 미국과 영국 정부는 제임스 라이트힐 경의 비판과 미국 의회의 보다 생산적인 프로젝트에 대한 지속적인 자금 지원 압력에 대응하여 탐색적 연구를 중단했다. 민스키와 패퍼트의 저서 퍼셉트론은 인공 신경망이 실제 문제를 해결하는 데 결코 유용하지 않을 것임을 증명한 것으로 받아들여져, 이 접근법 자체의 신뢰를 떨어뜨렸다. AI 프로젝트에 대한 자금 확보가 어려운 시기인 "AI 겨울"이 뒤따랐다.
1980년대 초, 인간 전문가의 지식과 분석 능력을 시뮬레이션하는 AI 프로그램의 한 형태인 전문가 시스템의 상업적 성공으로 AI 연구가 부활했다.[^225] 1985년까지 AI 시장은 10억 달러 이상에 달했다. 동시에, 일본의 제5세대 컴퓨터 프로젝트는 미국과 영국 정부가 학술 연구에 대한 자금 지원을 복원하도록 자극했다.[^14] 그러나 1987년 리스프 머신 시장의 붕괴를 시작으로, AI는 다시 한번 신뢰를 잃었고, 두 번째이자 더 오래 지속된 겨울이 시작되었다.
이 시점까지 AI 자금의 대부분은 계획, 목표, 신념, 알려진 사실과 같은 정신적 대상을 표현하기 위해 고수준 기호를 사용하는 프로젝트에 투입되었다. 1980년대에 일부 연구자들은 이 접근법이 인간 인지의 모든 과정, 특히 지각, 로봇공학, 학습, 패턴 인식을 모방할 수 있을지 의문을 품기 시작했고, "하위 기호적" 접근법을 탐구하기 시작했다. 로드니 브룩스는 "표상" 개념 자체를 거부하고 직접 움직이며 생존하는 기계를 설계하는 데 집중했다. 주디아 펄, 로트피 자데 등은 정밀한 논리 대신 합리적인 추측을 통해 불완전하고 불확실한 정보를 처리하는 방법을 개발했다.[^1] 그러나 가장 중요한 발전은 제프리 힌턴 등에 의한 신경망 연구를 포함한 "연결주의"의 부활이었다.[^227] 1990년, 얀 르쿤은 합성곱 신경망이 손으로 쓴 숫자를 인식할 수 있음을 성공적으로 보여주었으며, 이는 신경망의 많은 성공적 응용 중 첫 번째였다.
AI는 1990년대 후반과 21세기 초에 형식적인 수학적 방법을 활용하고 특정 문제에 대한 특정 해결책을 찾음으로써 점차 명성을 회복했다. 이러한 "좁은" 그리고 "형식적인" 초점은 연구자들이 검증 가능한 결과를 산출하고 다른 분야(통계학, 경제학, 수학 등)와 협력할 수 있게 했다. 2000년까지 AI 연구자들이 개발한 솔루션은 널리 사용되고 있었지만, 1990년대에는 "인공지능"이라고 거의 불리지 않았다(AI 효과로 알려진 경향).[^228] 그러나 여러 학술 연구자들은 AI가 다재다능하고 완전히 지능적인 기계를 만드는 원래의 목표를 더 이상 추구하지 않는 것에 우려하기 시작했다. 2002년경부터 그들은 인공 일반 지능(또는 "AGI")이라는 하위 분야를 설립했으며, 이는 2010년대에 여러 자금이 풍부한 기관을 갖추게 되었다.
딥러닝은 2012년부터 산업 벤치마크를 지배하기 시작했으며 해당 분야 전반에 걸쳐 채택되었다. 많은 특정 과제에서 다른 방법들은 포기되었다. 딥러닝의 성공은 하드웨어 개선(더 빠른 컴퓨터,[^229] 그래픽 처리 장치, 클라우드 컴퓨팅)과 대량의 데이터[^230](ImageNet 같은 큐레이션된 데이터셋 포함)에 대한 접근에 기반했다. 딥러닝의 성공은 AI에 대한 관심과 자금의 엄청난 증가로 이어졌다. 기계 학습 연구의 양(총 출판물 기준)은 2015년에서 2019년 사이에 50% 증가했다.
_on_Google_Trends.svg)
2016년, 공정성과 기술 오용 문제가 기계 학습 학회에서 중심 화제로 부상했고, 출판물이 크게 증가했으며, 자금이 확보되었고, 많은 연구자들이 이러한 문제에 경력을 재집중했다. 정렬 문제는 본격적인 학술 연구 분야가 되었다.
2010년대 후반과 2020년대 초반, AGI 기업들이 엄청난 관심을 불러일으키는 프로그램들을 선보이기 시작했다. 2015년, 딥마인드가 개발한 알파고가 세계 챔피언 바둑 기사를 이겼다. 이 프로그램은 게임 규칙만을 학습하고 스스로 전략을 개발했다. GPT-3는 2020년 OpenAI가 출시한 대형 언어 모델로, 고품질의 인간과 유사한 텍스트를 생성할 수 있다.[^231] 2022년 11월 30일에 출시된 ChatGPT는 두 달 만에 1억 명 이상의 사용자를 확보하며 역사상 가장 빠르게 성장한 소비자 소프트웨어 애플리케이션이 되었다.[^232] 이는 AI의 도약의 해로 널리 간주되며, AI를 대중의 인식 속으로 가져왔다.[^233] 이러한 프로그램들과 다른 프로그램들은 대기업들이 AI 연구에 수십억 달러를 투자하기 시작한 공격적인 AI 붐을 촉발했다. AI Impacts에 따르면, 2022년경 미국에서만 매년 약 500억 달러가 "AI"에 투자되었으며, 미국 컴퓨터 과학 신규 박사 졸업생의 약 20%가 "AI"를 전공했다. 2022년에는 약 80만 개의 "AI" 관련 미국 일자리가 존재했다. PitchBook 리서치에 따르면, 2024년에 신규 자금을 유치한 스타트업의 22%가 AI 기업이라고 주장했다.[^234]
철학
철학적 논쟁은 역사적으로 지능의 본질을 규명하고 지능적인 기계를 만드는 방법을 결정하고자 해왔다.[^235] 또 다른 주요 초점은 기계가 의식을 가질 수 있는지 여부와 그에 따른 윤리적 함의였다.[^15] 인식론과 자유의지 등 철학의 많은 다른 주제들도 인공지능과 관련이 있다.[^236] 급격한 발전은 인공지능의 철학과 윤리에 대한 공적 논의를 심화시켰다.[^15]
인공지능의 정의
앨런 튜링은 1950년에 "'기계가 생각할 수 있는가'라는 질문을 고찰할 것을 제안한다"라고 썼다. 그는 기계가 "생각하는지" 여부에 대한 질문을 "기계가 지능적 행동을 보이는 것이 가능한지 여부"로 바꿀 것을 권고했다. 그는 기계가 인간의 대화를 모방하는 능력을 측정하는 튜링 테스트를 고안했다.[^16] 우리는 기계의 행동만 관찰할 수 있으므로, 기계가 "실제로" 생각하는지 또는 문자 그대로 "마음"을 가지고 있는지는 중요하지 않다. 튜링은 다른 사람들에 대해서도 이러한 것들을 확인할 수 없지만 "모든 사람이 생각한다는 예의 바른 관례가 있는 것이 보통이다"라고 언급했다.
![튜링 테스트는 지능의 일부 증거를 제공할 수 있지만, 인간이 아닌 지능적 행동에 불이익을 준다.^237 ] 러셀과 노빅은 지능이 내부 구조가 아닌 외부 행동의 관점에서 정의되어야 한다는 점에서 튜링에 동의한다. 그러나 그들은 이 테스트가 기계에게 인간을 모방하도록 요구한다는 점에 비판적이다. "항공공학 교과서는", 그들은 썼다, "자신들의 분야의 목표를 '다른 비둘기를 속일 수 있을 정도로 비둘기와 똑같이 나는 기계'를 만드는 것으로 정의하지 않는다." 인공지능의 창시자 존 매카시도 이에 동의하며 "인공지능은 정의상 인간 지능의 시뮬레이션이 아니다"라고 썼다.
{kind=link}
매카시는 지능을 "세계에서 목표를 달성하는 능력의 계산적 부분"으로 정의한다. 또 다른 인공지능 창시자인 마빈 민스키는 이를 유사하게 "어려운 문제를 푸는 능력"으로 묘사한다. 인공지능: 현대적 접근방식은 이를 환경을 인식하고 정의된 목표를 달성할 가능성을 극대화하는 행동을 취하는 에이전트에 대한 연구로 정의한다.
인공지능에 대한 많은 서로 다른 정의들은 비판적으로 분석되어 왔다.[^238][^239][^240] 2020년대 인공지능 붐 기간 동안, 이 용어는 인공지능을 사용하지 않는 제품과 서비스를 홍보하기 위한 마케팅 유행어로 사용되어 왔다.[^241]
법적 정의
국제표준화기구는 인공지능 시스템을 "인간이 정의한 일련의 목표에 대해 콘텐츠, 예측, 추천 또는 결정과 같은 출력을 생성하며 다양한 수준의 자동화로 작동할 수 있는 공학적 시스템"으로 설명한다.[^242] EU 인공지능법은 인공지능 시스템을 "다양한 수준의 자율성으로 작동하도록 설계되고, 배치 후 적응성을 나타낼 수 있으며, 명시적 또는 암묵적 목표를 위해 수신한 입력으로부터 물리적 또는 가상 환경에 영향을 미칠 수 있는 예측, 콘텐츠, 추천 또는 결정과 같은 출력을 생성하는 방법을 추론하는 기계 기반 시스템"으로 정의한다.[^243] 미국에서는 미국표준기술연구소의 인공지능 위험 관리 프레임워크와 같은 영향력 있지만 구속력 없는 지침이 인공지능 시스템을 "주어진 목표 세트에 대해 실제 또는 가상 환경에 영향을 미치는 예측, 추천 또는 결정과 같은 출력을 생성할 수 있는 공학적 또는 기계 기반 시스템으로, 인공지능 시스템은 다양한 수준의 자율성으로 작동하도록 설계된다"라고 설명한다.[^244]
인공지능 접근방식의 평가
확립된 통합 이론이나 패러다임은 인공지능 연구의 대부분의 역사에서 연구를 이끌지 못했다. 2010년대 통계적 기계학습의 전례 없는 성공은 다른 모든 접근방식을 압도했다(일부 출처, 특히 비즈니스 세계에서는 "인공지능"이라는 용어를 "신경망을 활용한 기계학습"을 의미하는 것으로 사용할 정도로). 이 접근방식은 대부분 하위 기호적이고, 소프트하며, 좁다. 비평가들은 이러한 질문들이 미래 세대의 인공지능 연구자들에 의해 재검토되어야 할 수 있다고 주장한다.
기호적 인공지능과 그 한계
기호적 인공지능(또는 "GOFAI")은 사람들이 퍼즐을 풀고, 법적 추론을 표현하고, 수학을 할 때 사용하는 고수준의 의식적 추론을 시뮬레이션했다. 이들은 대수학이나 IQ 테스트와 같은 "지능적" 과제에서 매우 성공적이었다. 1960년대에 뉴웰과 사이먼은 물리적 기호 시스템 가설을 제안했다: "물리적 기호 시스템은 일반적인 지능적 행동의 필요충분조건을 갖추고 있다."[^245]
그러나 기호적 접근방식은 학습, 사물 인식 또는 상식적 추론과 같이 인간이 쉽게 해결하는 많은 과제에서 실패했다. 모라벡의 역설은 고수준의 "지능적" 과제는 인공지능에게 쉬웠지만, 저수준의 "본능적" 과제는 극도로 어려웠다는 발견이다.[^246] 철학자 휴버트 드레이퍼스는 1960년대부터 인간의 전문성은 의식적인 기호 조작이 아닌 무의식적 본능에, 그리고 명시적인 기호적 지식보다는 상황에 대한 "감"에 의존한다고 주장해왔다.[^247] 그의 주장이 처음 제시되었을 때는 조롱받고 무시되었지만, 결국 인공지능 연구는 그에게 동의하게 되었다.
이 문제는 해결되지 않았다: 하위 기호적 추론은 알고리즘 편향과 같이 인간의 직관이 범하는 것과 같은 불가해한 실수를 많이 범할 수 있다. 놈 촘스키와 같은 비평가들은 부분적으로 하위 기호적 인공지능이 설명 가능한 인공지능에서 벗어나는 움직임이기 때문에, 일반 지능을 달성하기 위해서는 기호적 인공지능에 대한 지속적인 연구가 여전히 필요할 것이라고 주장한다: 현대의 통계적 인공지능 프로그램이 특정 결정을 내린 이유를 이해하기 어렵거나 불가능할 수 있다. 신경-기호 인공지능이라는 신흥 분야는 두 접근방식을 연결하려고 시도한다.
깔끔파 대 지저분파
"깔끔파"는 지능적 행동이 (논리, 최적화 또는 신경망과 같은) 단순하고 우아한 원리로 설명될 수 있기를 바란다. "지저분파"는 지능적 행동이 필연적으로 다수의 관련 없는 문제를 해결해야 한다고 예상한다. 깔끔파는 이론적 엄밀성으로 자신들의 프로그램을 옹호하고, 지저분파는 주로 점진적인 테스트에 의존하여 작동 여부를 확인한다. 이 문제는 1970년대와 1980년대에 활발히 논의되었으나,[^248] 결국 무관한 것으로 여겨졌다. 현대 인공지능은 양쪽의 요소를 모두 포함한다.
소프트 컴퓨팅 대 하드 컴퓨팅
증명 가능한 정확하거나 최적인 해를 찾는 것은 많은 중요한 문제에서 난해하다. 소프트 컴퓨팅은 유전 알고리즘, 퍼지 논리 및 신경망을 포함하는 일련의 기법으로, 부정확성, 불확실성, 부분적 진리 및 근사를 허용한다. 소프트 컴퓨팅은 1980년대 후반에 도입되었으며, 21세기에 가장 성공적인 인공지능 프로그램들은 대부분 신경망을 활용한 소프트 컴퓨팅의 사례이다.
좁은 인공지능 대 일반 인공지능
인공지능 연구자들은 인공 일반 지능과 초지능의 목표를 직접 추구할 것인지, 아니면 가능한 한 많은 특정 문제를 해결하여(좁은 인공지능) 이러한 해결책이 간접적으로 분야의 장기적 목표로 이어지기를 바랄 것인지에 대해 의견이 나뉜다. 일반 지능은 정의하기 어렵고 측정하기 어려우며, 현대 인공지능은 특정 문제에 대한 특정 해결책에 집중함으로써 더 검증 가능한 성공을 거두었다. 인공 일반 지능이라는 하위 분야가 이 영역을 전문적으로 연구한다.
기계 의식, 감각, 그리고 마음
기계가 인간과 같은 의미에서 마음, 의식, 정신 상태를 가질 수 있는지에 대해 심리철학에서 확립된 합의는 없다. 이 문제는 기계의 외부 행동이 아닌 내부 경험을 고려한다. 주류 인공지능 연구는 이 문제가 분야의 목표, 즉 지능을 사용하여 문제를 해결할 수 있는 기계를 만드는 것에 영향을 미치지 않기 때문에 무관하다고 본다. 러셀과 노빅은 "인간과 정확히 같은 방식으로 기계를 의식적으로 만드는 추가 프로젝트는 우리가 수행할 준비가 된 것이 아니다"라고 덧붙인다. 그러나 이 질문은 심리철학의 핵심이 되었다. 이것은 또한 전형적으로 인공지능을 다룬 픽션에서 쟁점이 되는 핵심 질문이기도 하다.
의식
데이비드 차머스는 마음을 이해하는 데 있어 두 가지 문제를 식별하고, 이를 의식의 "어려운" 문제와 "쉬운" 문제로 명명했다. 쉬운 문제는 뇌가 어떻게 신호를 처리하고, 계획을 세우고, 행동을 제어하는지 이해하는 것이다. 어려운 문제는 이것이 어떻게 느껴지는지 또는 왜 무언가를 느끼는 것처럼 느껴져야 하는지를 설명하는 것으로, 그것이 진정으로 무언가를 느끼는 것이라고 우리가 생각하는 것이 맞다고 가정할 때의 문제이다(데닛의 의식 환상주의는 이것이 환상이라고 말한다). 인간의 정보 처리는 설명하기 쉽지만, 인간의 주관적 경험은 설명하기 어렵다. 예를 들어, 시야에 있는 어떤 물체가 빨간색인지 식별하는 법을 배운 색맹인 사람을 상상하는 것은 쉽지만, 그 사람이 빨간색이 어떻게 보이는지 알기 위해 무엇이 필요한지는 명확하지 않다.
계산주의와 기능주의
계산주의는 인간의 마음이 정보 처리 시스템이며 사고가 일종의 계산이라는 심리철학의 입장이다. 계산주의는 마음과 신체의 관계가 소프트웨어와 하드웨어의 관계와 유사하거나 동일하며, 따라서 심신 문제에 대한 해결책이 될 수 있다고 주장한다. 이 철학적 입장은 1960년대 인공지능 연구자들과 인지과학자들의 연구에서 영감을 받았으며, 철학자 제리 포더와 힐러리 퍼트넘이 최초로 제안했다.
철학자 존 설은 이 입장을 "강한 인공지능"으로 특징지었다: "적절히 프로그래밍된 컴퓨터가 올바른 입력과 출력을 갖추면 인간이 마음을 갖는 것과 정확히 같은 의미에서 마음을 갖게 될 것이다." 설은 이 주장에 중국어 방 논증으로 도전하며, 인간의 행동을 완벽하게 시뮬레이션할 수 있는 컴퓨터조차도 마음을 갖지 못할 것임을 보여주려 시도한다.[^249]
인공지능의 복지와 권리
고급 인공지능이 감각이 있는지(느끼는 능력이 있는지), 그렇다면 어느 정도인지를 신뢰성 있게 평가하는 것은 어렵거나 불가능하다.[^250] 그러나 주어진 기계가 느끼고 고통받을 수 있는 상당한 가능성이 있다면, 동물과 유사하게 특정 권리나 복지 보호 조치를 받을 자격이 있을 수 있다.[^17][^18] 지각(분별력이나 자기인식과 같은 높은 지능과 관련된 일련의 능력)은 인공지능 권리에 대한 또 다른 도덕적 근거를 제공할 수 있다.[^17] 로봇 권리는 또한 때때로 자율적 에이전트를 사회에 통합하는 실용적인 방법으로 제안된다.[^251]
2017년, 유럽연합은 가장 유능한 일부 인공지능 시스템에 "전자적 인격"을 부여하는 것을 검토했다. 기업의 법적 지위와 유사하게, 이는 권리뿐만 아니라 책임도 부여했을 것이다.[^252] 비평가들은 2018년에 인공지능 시스템에 권리를 부여하는 것이 인권의 중요성을 경시할 것이며, 입법은 추측적인 미래 시나리오보다 사용자 요구에 초점을 맞춰야 한다고 주장했다. 그들은 또한 로봇이 스스로 사회에 참여할 자율성이 부족하다고 지적했다.[^253][^254]
인공지능의 발전은 이 주제에 대한 관심을 높였다. 인공지능 복지와 권리의 지지자들은 인공지능의 감각이 출현한다면 특히 부정하기 쉬울 것이라고 자주 주장한다. 그들은 이것이 노예제나 공장식 축산과 유사한 도덕적 사각지대일 수 있으며, 감각이 있는 인공지능이 만들어져 부주의하게 착취될 경우 대규모 고통으로 이어질 수 있다고 경고한다.[^18][^17]
미래
초지능과 특이점
초지능이란 가장 뛰어나고 재능 있는 인간의 지능을 훨씬 뛰어넘는 지능을 갖춘 가상의 행위자를 말한다. 만약 범용 인공지능 연구가 충분히 지능적인 소프트웨어를 만들어낸다면, 그 소프트웨어는 스스로를 재프로그래밍하고 개선할 수 있을 것이다. 개선된 소프트웨어는 자기 자신을 더욱 잘 개선할 수 있게 되어, I. J. Good이 "지능 폭발"이라 부르고 Vernor Vinge가 "특이점"이라 부른 현상으로 이어질 수 있다.[^255]
그러나 기술은 무한히 기하급수적으로 발전할 수 없으며, 일반적으로 S자형 곡선을 따라 해당 기술이 할 수 있는 물리적 한계에 도달하면 둔화된다.
트랜스휴머니즘
로봇 설계자 Hans Moravec, 사이버네틱스 학자 Kevin Warwick, 발명가 Ray Kurzweil은 미래에 인간과 기계가 융합하여 어느 쪽보다도 더 뛰어나고 강력한 사이보그가 될 수 있다고 예측했다. 트랜스휴머니즘이라 불리는 이 개념은 Aldous Huxley와 Robert Ettinger의 저술에 그 뿌리를 두고 있다.[^256]
Edward Fredkin은 "인공지능은 진화의 다음 단계"라고 주장하는데, 이 개념은 1863년에 이미 Samuel Butler의 "기계들 사이의 다윈"에서 처음 제안되었으며, George Dyson이 1998년 저서 Darwin Among the Machines: The Evolution of Global Intelligence에서 이를 확장하였다.[^257]
허구 속의 인공지능
![The word "robot" itself was coined by [Karel Čapek in his 1921 play R.U.R., the title standing for "Rossum's Universal Robots".]]
{kind=link}
사고 능력을 갖춘 인공적 존재는 고대부터 이야기의 장치로 등장해 왔으며, 공상과학 소설에서 지속적인 주제가 되어 왔다.
이러한 작품들에서 흔히 나타나는 서사적 장치는 Mary Shelley의 프랑켄슈타인에서 시작되었는데, 인간이 만든 피조물이 창조자에게 위협이 되는 내용이다. 여기에는 Arthur C. Clarke와 Stanley Kubrick의 2001: 스페이스 오디세이 (둘 다 1968년)가 포함되며, 우주선 디스커버리 원호를 관리하는 살인적 컴퓨터 HAL 9000이 등장한다. 또한 블레이드 러너 (1882년), 터미네이터 (1984년), 매트릭스 (1999년)도 이에 해당한다. 반면, 지구가 멈추는 날 (1951년)의 고트나 에이리언 2 (1986년)의 비숍과 같이 드물게 등장하는 충성스러운 로봇들은 대중문화에서 덜 두드러진다.
Isaac Asimov는 많은 이야기에서 로봇 공학 3원칙을 도입했으며, 특히 "멀티백" 초지능 컴퓨터와 관련된 작품이 유명하다. Asimov의 법칙은 기계 윤리에 관한 일반인들의 논의에서 자주 언급된다. 거의 모든 인공지능 연구자들이 대중문화를 통해 Asimov의 법칙을 알고 있지만, 그 모호성을 비롯한 여러 이유로 일반적으로 이 법칙을 쓸모없는 것으로 간주한다.
여러 작품들은 인공지능을 통해 우리에게 인간을 인간답게 만드는 것이 무엇인지라는 근본적 질문에 직면하게 하며, 감정을 느끼고 따라서 고통받을 수 있는 인공적 존재를 보여준다. 이는 Karel Čapek의 R.U.R., 영화 *A.I.*와 엑스 마키나, 그리고 Philip K. Dick의 소설 *안드로이드는 전기양의 꿈을 꾸는가?*에 나타난다. Dick은 인공지능으로 만들어진 기술에 의해 인간의 주관성에 대한 우리의 이해가 변화한다는 개념을 탐구한다.
같이 보기
-
-
-
- 위키미디어 프로젝트에서의 인공지능 – 위키백과 및 기타 위키미디어 프로젝트 개발을 위한 인공지능 활용
-
-
- 인공지능 발전 협회 (AAAI)
-
-
-
-
- DARWIN EU – 유럽연합 전역의 의약품 평가 및 감독을 지원하기 위해 실세계 증거(RWE)를 생성하고 활용하는, 유럽의약품청(EMA)이 조율하는 유럽연합 이니셔티브
-
-
-
-
-
-
-
-
-
-
- 인공지능 서적 목록
-
-
-
-
-
-
- 인공지능 학술지 목록
- 인공지능 프로젝트 목록
-
- 오가노이드 지능 – 지능형 컴퓨팅을 위한 뇌세포 및 뇌 오가노이드 활용
-
-
-
-
설명 주석
-
-
-
교과서
-
-
- 이후 판:
-
-
-
- .
-
인공지능의 역사
-
-
-
기타 출처
-
-
- 핵융합에서의 AI & ML
- 핵융합에서의 AI & ML, 동영상 강의
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 인공지능 발전 협회 회장 연설.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 이후 다음으로 출판됨
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
외부 링크
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
참고 문헌
[^1]: 불확실한 추론을 위한 확률적 방법: Harvtxt Russell Norvig 2021 loc=chpt. 12–18, 20 , Harvtxt Poole Mackworth Goebel 1998 pp=345–395 , Harvtxt Luger Stubblefield 2004 pp=165–191, 333–3
[^2]: 생물정보학의 기계 학습에 관한 실증적 과학 연구. (2020년 2월)
[^3]: 의회조사국. 인공지능과 국가안보. 의회조사국
[^4]: Slyusar, Vadym. 미래 제어 네트워크의 기반으로서의 인공지능. (2019)
[^5]: Davies, Harry. '복음': 이스라엘이 가자지구 폭격 목표 선정에 AI를 사용하는 방법. (2023년 12월 1일)
[^6]: Bhattarai, Abha. 경제 향방을 보여주는 10가지 차트 / 3. AI 관련 투자. (2025년 12월 25일)
[^7]: 대만, 전력 부족을 이유로 북부 대형 데이터 센터 건설 중단. DatacenterDynamics. (2024년 8월 19일)
[^8]: Mochizuki, Takashi. エヌビディア出資の日本企業、原発近くでΑIデータセンター新設検討. (2024년 10월 18일)
[^9]: 원자력이 필요한 AI 캠퍼스, 빠르게 전력을 확보할 새로운 계획 필요. Bloomberg. (2024년 11월 5일)
[^10]: Samuel, Sigal. AI를 공정하고 편향 없게 만드는 것이 왜 그토록 어려운가. (2022년 4월 19일)
[^11]: cite web title=탄광의 카나리아? 인공지능의 최근 고용 효과에 대한 여섯 가지 사실 website=Stanford Digital Economy Lab date=2026 url=https://digitaleconomy.sta
[^12]: Buntz, Brian. 품질 대 수량: 2024년 글로벌 AI 특허 경쟁에서 미국과 중국이 선택한 다른 경로 / 2024년 AI 특허의 지역별 분포. R&D World. (2024년 11월 3일)
[^13]: 1960년대의 성공적인 프로그램들: Harvtxt McCorduck 2004 pp=243–252 , Harvtxt Crevier 1993 pp=52–107 , Harvtxt Moravec 1988 p=9 , Harvtxt Russell Norvig 2021 pp=19–21
[^14]: 1980년대 초 자금 지원 계획: [[Fifth Generation Project]] (일본), [[Alvey]] (영국), [[Microelectronics and Computer Technology Corporation]] (미국), [[Strategic Computing Initiative]] (미국):
[^15]: Jarow, Oshan. AI는 언젠가 의식을 갖게 될까? 그것은 생물학을 어떻게 바라보느냐에 달려 있다.. (2024년 6월 15일)
[^16]: [[튜링 테스트]]에 대한 Turing의 원본 출판물 "[[Computing machinery and intelligence]]": Harvtxt Turing 1950
역사적 영향과 철학적 함의: Harvtxt Haugeland 198
[^17]: Thomson, Jonny. 왜 로봇에게는 권리가 없는가?. (2022년 10월 31일)
[^18]: Kateman, Brian. AI는 인간을 두려워해야 한다. (2023년 7월 24일)
[^20]: Kaplan, Andreas. 시리야, 시리야, 내 손 안의 시리야: 이 땅에서 가장 공정한 것은 무엇인가? 인공지능의 해석, 도해 및 함의에 대하여. (2019)
[^21]: Harvtxt Russell Norvig 2021 loc=§1.2 .
[^22]: 기술 기업들이 범용 인공지능을 만들고자 한다. 그러나 AGI 달성 여부를 누가 결정하는가?. (2024년 4월 4일)
[^23]: 문제 해결, 퍼즐 풀기, 게임 플레이 및 연역: Harvtxt Russell Norvig 2021 loc=chpt. 3–5 , Harvtxt Russell Norvig 2021 loc=chpt. 6 ([[constraint satisfaction]]), Harvtxt Poole
[^24]: 불확실한 추론: Harvtxt Russell Norvig 2021 loc=chpt. 12–18 , Harvtxt Poole Mackworth Goebel 1998 pp=345–395 , Harvtxt Luger Stubblefield 2004 pp=333–381 , Harvtxt Nilsson 1998 loc=chp
[^25]: [[지식 표현]]과 [[지식 공학]]: Harvtxt Russell Norvig 2021 loc=chpt. 10 , Harvtxt Poole Mackworth Goebel 1998 pp=23–46, 69–81, 169–233, 235–277, 281–298, 319–345 ,
[^26]: 범주와 관계의 표현: [[의미 네트워크]], [[기술 논리]], [[상속 (객체 지향 프로그래밍) 상속]] ([[프레임 (인공지능) 프레임]] 포함),
[^27]: 사건과 시간의 표현: [[상황 미적분학]], [[사건 미적분학]], [[유동 미적분학]] ([[프레임 문제]] 해결 포함): Harvtxt Russell Norvig 2021 loc=§10.3 , Harvtxt Poole Mackw
[^28]: [[인과관계#인과 미적분학 인과 미적분학]]: Harvtxt Poole Mackworth Goebel 1998 pp=335–337
[^29]: 지식에 대한 지식의 표현: 믿음 미적분학, [[양상 논리]]: Harvtxt Russell Norvig 2021 loc=§10.4 , Harvtxt Poole Mackworth Goebel 1998 pp=275–277
[^30]: [[자동화된 계획수립]]: Harvtxt Russell Norvig 2021 loc=chpt. 11 .
[^31]: [[자동화된 의사결정]], [[결정 이론]]: Harvtxt Russell Norvig 2021 loc=chpt. 16–18 .
[^32]: [[자동화된 계획수립 및 스케줄링#고전적 계획수립 고전적 계획수립]]: Harvtxt Russell Norvig 2021 loc=Section 11.2 .
[^33]: 무감각 또는 "순응적" 계획수립, 우발적 계획수립, 재계획수립 (온라인 계획수립이라고도 함): Harvtxt Russell Norvig 2021 loc=Section 11.5 .
[^34]: 신뢰, 해석 가능성 및 설명 가능성: Harvtxt Russell Norvig 2021 loc=Section 19.9.4 .
[^35]: 불확실한 선호: Harvtxt Russell Norvig 2021 loc=Section 16.7
[[역강화학습]]: Harvtxt Russell Norvig 2021 loc=Section 22.6
[^36]: [[정보 가치 이론]]: Harvtxt Russell Norvig 2021 loc=Section 16.6 .
[^37]: [[마르코프 결정 과정]]: Harvtxt Russell Norvig 2021 loc=chpt. 17 .
[^38]: [[게임 이론]]과 다중 에이전트 결정 이론: Harvtxt Russell Norvig 2021 loc=chpt. 18 .
[^39]: [[기계 학습 학습]]: Harvtxt Russell Norvig 2021 loc=chpt. 19–22 , Harvtxt Poole Mackworth Goebel 1998 pp=397–438 , Harvtxt Luger Stubblefield 2004 pp=385–542 , Harvtxt Nilsson 19
[^40]: [[비지도 학습]]: Harvtxt Russell Norvig 2021 pp=653 (정의), Harvtxt Russell Norvig 2021 pp=738–740 ([[군집 분석]]), Harvtxt Russell Norvig 2021 pp=846–860 ([[단어 임
[^41]: [[강화학습]]: Harvtxt Russell Norvig 2021 loc=chpt. 22 , Harvtxt Luger Stubblefield 2004 pp=442–449
[^42]: [[전이 학습]]: Harvtxt Russell Norvig 2021 pp=281 , Harvtxt The Economist 2016
[^43]: 인공지능(AI): AI란 무엇이며 어떻게 작동하는가?
[^44]: [[계산 학습 이론]]: Harvtxt Russell Norvig 2021 pp=672–674 , Harvtxt Jordan Mitchell 2015
[^45]: [[자연어 처리]] (NLP): Harvtxt Russell Norvig 2021 loc=chpt. 23–24 , Harvtxt Poole Mackworth Goebel 1998 pp=91–104 , Harvtxt Luger Stubblefield 2004 pp=591–632
[^46]: [[자연어 처리 NLP]]의 하위 문제들: Harvtxt Russell Norvig 2021 pp=849–850
[^47]: [[자연어 처리 NLP]]에 대한 현대 통계 및 딥러닝 접근법: Harvtxt Russell Norvig 2021 loc=chpt. 24 , Harvtxt Cambria White 2014
[^48]: [[컴퓨터 비전]]: Harvtxt Russell Norvig 2021 loc=chpt. 25 , Harvtxt Nilsson 1998 loc=chpt. 6
[^49]: [[감성 컴퓨팅]]: Harvtxt Thro 1993 , Harvtxt Edelson 1991 , Harvtxt Tao Tan 2005 , Harvtxt Scassellati 2002
[^50]: [[상태 공간 탐색]]: Harvtxt Russell Norvig 2021 loc=chpt. 3
[^51]: [[비정보 탐색]] ([[너비 우선 탐색]], [[깊이 우선 탐색]] 및 일반 [[상태 공간 탐색]]): Harvtxt Russell Norvig 2021 loc=sect. 3.4 , Harvtxt Poole Mackworth Goebel 1998 pp=1
[^52]: [[휴리스틱]] 또는 정보 기반 탐색 (예: 탐욕적 [[최선 우선 탐색 최선 우선]] 및 [[A* 탐색 알고리즘 A*]]): Harvtxt Russell Norvig 2021 loc=sect. 3.5 , Harvtxt Poole Mackworth Goebel 1998
[^53]: [[적대적 탐색]]: Harvtxt Russell Norvig 2021 loc=chpt. 5
[^54]: [[지역 탐색 (최적화) 지역]] 또는 "[[최적화]]" 탐색: Harvtxt Russell Norvig 2021 loc=chpt. 4
[^55]: Singh Chauhan, Nagesh. 신경망의 최적화 알고리즘. (2020년 12월 18일)
[^56]: [[진화 연산]]: Harvtxt Russell Norvig 2021 loc=sect. 4.1.2
[^57]: [[논리]]: Harvtxt Russell Norvig 2021 loc=chpts. 6–9 , Harvtxt Luger Stubblefield 2004 pp=35–77 , Harvtxt Nilsson 1998 loc=chpt. 13–16
[^58]: [[명제 논리]]: Harvtxt Russell Norvig 2021 loc=chpt. 6 , Harvtxt Luger Stubblefield 2004 pp=45–50 , Harvtxt Nilsson 1998 loc=chpt. 13
[^59]: [[1차 논리]] 및 [[등식 (수학) 등식]] 등의 기능: Harvtxt Russell Norvig 2021 loc=chpt. 7 , Harvtxt Poole Mackworth Goebel 1998 pp=268–275 , Harvtxt Luger Stubble
[^60]: [[논리적 추론]]: Harvtxt Russell Norvig 2021 loc=chpt. 10
[^61]: 탐색으로서의 논리적 연역: Harvtxt Russell Norvig 2021 loc=sects. 9.3, 9.4 , Harvtxt Poole Mackworth Goebel 1998 pp=~46–52 , Harvtxt Luger Stubblefield 2004 pp=62–73 , Harvtxt Nilsson 199
[^62]: [[분해능 (논리) 분해능]] 및 [[통합 (컴퓨터 과학) 통합]]: Harvtxt Russell Norvig 2021 loc= sections 7.5.2, 9.2, 9.5
[^63]: Warren, D.H.. Prolog - Lisp과 비교한 언어와 그 구현. (1977)
[^64]: 퍼지 논리: Harvtxt Russell Norvig 2021 pp=214, 255, 459 , Harvtxt Scientific American 1999
[^65]: [[결정 이론]]과 [[결정 분석]]: Harvtxt Russell Norvig 2021 loc=chpt. 16–18 , Harvtxt Poole Mackworth Goebel 1998 pp=381–394
[^66]: [[정보 가치 이론]]: Harvtxt Russell Norvig 2021 loc=sect. 16.6
[^67]: [[마르코프 결정 과정]]과 동적 [[결정 네트워크]]: Harvtxt Russell Norvig 2021 loc=chpt. 17
[^68]: [[게임 이론]]과 [[메커니즘 설계]]: Harvtxt Russell Norvig 2021 loc=chpt. 18
[^69]: [[베이지안 네트워크]]: Harvtxt Russell Norvig 2021 loc=sects. 12.5–12.6, 13.4–13.5, 14.3–14.5, 16.5, 20.2–20.3 , Harvtxt Poole Mackworth Goebel 1998 pp=361–381 , Harvtxt Luger Stubblefield 200
[^70]: [[베이지안 추론]] 알고리즘: Harvtxt Russell Norvig 2021 loc=sect. 13.3–13.5 , Harvtxt Poole Mackworth Goebel 1998 pp=361–381 , Harvtxt Luger Stubblefield 2004 pp=~363–379 , Harvtxt Ni
[^71]: [[베이지안 학습]]과 [[기댓값 최대화 알고리즘]]: Harvtxt Russell Norvig 2021 loc=chpt. 20 , Harvtxt Poole Mackworth Goebel 1998 pp=424–433 , Harvtxt Nilsson 1998 loc=chpt.
[^72]: [[베이지안 결정 이론]]과 베이지안 [[결정 네트워크]]: Harvtxt Russell Norvig 2021 loc=sect. 16.5
[^73]: 통계적 학습 방법과 [[분류기 (수학) 분류기]]: Harvtxt Russell Norvig 2021 loc=chpt. 20 ,
[^74]: Ciaramella, Alberto. 인공지능 입문: 데이터 분석에서 생성형 AI까지. Intellisemantic Editions. (2024)
[^75]: [[교대 결정 트리 결정 트리]]: Harvtxt Russell Norvig 2021 loc=sect. 19.3 , Harvtxt Domingos 2015 p=88
[^76]: [[비모수 통계 비모수]] 학습 모델 예: [[K-최근접 이웃]]과 [[서포트 벡터 머신]]: Harvtxt Russell Norvig 2021 loc=sect. 19.7 , Harvtxt Domingos 2015 p=1
[^77]: [[나이브 베이즈 분류기]]: Harvtxt Russell Norvig 2021 loc=sect. 12.6 , Harvtxt Domingos 2015 p=152
[^78]: 계산 그래프에서의 기울기 계산, [[역전파]], [[자동 미분]]: Harvtxt Russell Norvig 2021 loc=sect. 21.2 , Harvtxt Luger Stubblefield 2004 pp=467–474 , Harv
[^79]: [[범용 근사 정리]]: Harvtxt Russell Norvig 2021 p=752
해당 정리: Harvtxt Cybenko 1988 , Harvtxt Hornik Stinchcombe White 1989
[^80]: [[순방향 신경망]]: Harvtxt Russell Norvig 2021 loc=sect. 21.1
[^81]: [[퍼셉트론]]: Harvtxt Russell Norvig 2021 pp=21, 22, 683, 22
[^82]: [[순환 신경망]]: Harvtxt Russell Norvig 2021 loc=sect. 21.6
[^83]: [[합성곱 신경망]]: Harvtxt Russell Norvig 2021 loc=sect. 21.3
[^84]: 인용: Harvtxt Christian 2020 p=22
[^85]: Metz, Cade. 새로운 시스템이 더 강력해지는데도 AI 환각은 더 심해지고 있다. (2025년 5월 5일)
[^86]: 해설: 생성형 AI. (2023년 11월 9일)
[^87]: AI 글쓰기 및 콘텐츠 생성 도구
[^88]: Thomason, James. 모조의 부상: AI 우선 프로그래밍 언어의 부활. (2024년 5월 21일)
[^89]: Wodecki, Ben. 알아야 할 7가지 AI 프로그래밍 언어. (2023년 5월 5일)
[^90]: Plumb, Taryn. 젠슨 황과 마크 베니오프가 에이전틱 AI에서 '거대한' 기회를 보는 이유. (2024년 9월 18일)
[^91]: Mims, Christopher. 황의 법칙은 새로운 무어의 법칙이며, 엔비디아가 Arm을 원하는 이유를 설명한다. (2020년 9월 19일)
[^92]: Dankwa-Mullan, Irene. 공중보건 및 의학에서 인공지능 사용의 건강 형평성과 윤리적 고려사항. (2024)
[^93]: Jumper, J. AlphaFold를 이용한 매우 정확한 단백질 구조 예측. (2021)
[^94]: AI, 약물 내성 박테리아를 죽이는 새로운 종류의 항생제 발견. (2023년 12월 20일)
[^95]: AI, 파킨슨병 약물 설계 속도 10배 향상. 케임브리지 대학교. (2024년 4월 17일)
[^96]: Horne, Robert I.. 구조 기반 반복 학습을 사용한 α-시누클레인 응집의 강력한 억제제 발견. Nature. (2024년 4월 17일)
[^97]: Grant, Eugene F.. 시내 화제 – 그것. (1952년 7월 25일)
[^98]: Anderson, Mark Robert. 딥 블루 대 카스파로프 20주년: 한 체스 경기가 빅데이터 혁명을 시작한 방법. (2017년 5월 11일)
[^99]: Markoff, John. 컴퓨터, '제퍼디!'에서 승리: 사소한 것이 아니다. (2011년 2월 16일)
[^100]: Byford, Sam. AlphaGo, 세계 1위를 3-0으로 꺾은 후 프로 바둑에서 은퇴. (2017년 5월 27일)
[^101]: Brown, Noam. 멀티플레이어 포커에서의 초인적 AI. (2019년 8월 30일)
[^102]: MuZero: 규칙 없이 바둑, 체스, 장기, 아타리 마스터하기. (2020년 12월 23일)
[^103]: Sample, Ian. AI, '극도로 복잡한' 스타크래프트 II에서 그랜드마스터 달성. (2019년 10월 30일)
[^104]: Wurman, P. R.. 심층 강화학습으로 그란 투리스모 챔피언 드라이버를 능가하다. (2022)
[^105]: Wilkins, Alex. 구글 AI, 오픈 월드 비디오 게임을 시청하며 플레이하는 법 학습. (2024년 3월 13일)
[^106]: Franzen, Carl. 마이크로소프트의 새로운 rStar-Math 기법, 소형 모델을 OpenAI의 o1-preview를 능가하는 수학 문제 풀이 수준으로 업그레이드. (2025년 1월 9일)
[^107]: AlphaEvolve, 키싱 문제 등에 도전 {{!. (2025년 5월 14일)
[^108]: Roberts, Siobhan. AI, 국제 수학 올림피아드 문제 풀이에서 은메달 수준 달성. (2024년 7월 25일)
[^109]: Metz, Cade. 구글 AI 시스템, 국제 수학 올림피아드에서 금메달 획득. (2025년 7월 21일)
[^111]: Iraqi, Amjad. '라벤더': 가자지구에서 이스라엘의 폭격을 지휘하는 AI 기계. (2024년 4월 3일)
[^112]: Marti, J Werner. 드론이 우크라이나 전쟁을 혁신했지만, 전파 교란에 취약하다 – 그래서 이제 자율 운용을 목표로 한다. (2024년 8월 10일)
[^113]: Poole, David. 인공지능, 계산 에이전트의 기초. Cambridge University Press. (2023)
[^114]: Russell, Stuart. [[인공지능: 현대적 접근법]]. Pearson. (2020)
[^115]: 에이전트가 생성형 AI의 다음 프론티어인 이유. (2024년 7월 24일)
[^116]: Peters, Jay. Bing AI 봇은 비밀리에 GPT-4를 구동하고 있었다. (2023년 3월 14일)
[^117]: Wiggers, Kyle. 구글 I/O 2025: 올해 개발자 컨퍼런스에서 발표된 모든 것. (2025년 5월 20일)
[^118]: Figueiredo, Mayara Costa. AI 기반: AI 설명이 가임기 추적 애플리케이션에 대한 인식에 미치는 영향 분석. (2024년 1월 12일)
[^119]: Power, Jennifer. 스마트 섹스 토이: 문화적, 건강 및 안전 고려사항에 관한 서술적 검토. (2024년 7월 5일)
[^120]: Marcantonio, Tiffany L.. 앱 속의 대규모 언어 모델: 스냅챗의 'My AI'가 성적 동의, 성적 거부, 성폭행 및 섹스팅에 관한 질문에 응답하는 방식에 대한 정성적 합성 데이터 분석. (2024년 9월 10일)
[^121]: Hanson, Kenneth R.. "레플리카에서 성적 역할극을 제거하는 것은 GTA에서 총이나 차를 제거하는 것과 같다": 인공지능 챗봇과 성적 기술에 대한 레딧 담론. (2024)
[^122]: Mania, Karolina. 유럽연합에서의 리벤지 포르노 및 딥페이크 포르노 피해자의 법적 보호: 비교 법률 연구 결과. (2024)
[^123]: Singh, Suyesha. 온라인 아동 성적 학대 방지에서 인공지능의 역할: 체계적 문헌 검토. (2024)
[^124]: Razi, Afsaneh. 온라인 성적 위험 탐지를 위한 계산적 접근법의 인간 중심 체계적 문헌 검토. (2021년 10월 13일)
[^125]: Ransbotham, Sam. 인공지능으로 비즈니스 재편하기. (2017년 9월 6일)
[^126]: Sun, Yuran. 토목 인프라의 분석, 설계, 평가 및 의사결정을 위한 해석 가능한 기계 학습. (2024)
[^127]: Gomaa, Islam. 지능형 화재 감지 및 대피 시스템 프레임워크. (2021년 11월 1일)
[^128]: Zhao, Xilei. 기계 학습을 이용한 대피 전 의사결정 모델링 및 해석. (2020년 5월 1일)
[^129]: 인도의 최근 선거는 AI 기술을 수용했다. 건설적으로 활용된 몇 가지 사례. (2024년 6월 12일)
[^130]: 경제학자 Daron Acemoglu가 인공지능의 위협에 관한 책을 썼다 — 그리고 올바른 관리가 어떻게 인류에게 이로울 수 있는지에 대해
[^131]: AI 시대의 학습, 사고, 예술적 협업 및 기타 인간적 활동. (2023년 6월 2일)
[^132]: Müller, Vincent C.. 인공지능과 로봇공학의 윤리. (2020년 4월 30일)
[^133]: 잠재적 미래 인공지능 위험, 이익 및 정책 과제 평가. (2024년 11월 14일)
[^134]: Kopel, Matthew. 저작권 서비스: 공정 이용
[^135]: Burgess, Matt. AI 학습에 데이터가 사용되는 것을 막는 방법
[^136]: 독점: 여러 AI 기업들이 웹 표준을 우회하여 출판사 사이트를 스크래핑하고 있다고 라이선싱 회사 밝혀
[^137]: Shilov, Anton. 여러 AI 기업들이 robots.txt 차단을 무시하고 허가 없이 콘텐츠를 스크래핑하고 있다는 보도. (2024년 6월 21일)
[^138]: AI를 위한 혁신 생태계 준비. IP 정책 도구 모음
[^139]: Hammond, George. 빅테크, AI 스타트업에 VC보다 더 많이 투자. (2023년 12월 27일)
[^140]: Wong, Matteo. AI의 미래는 GOMA이다. (2023년 10월 24일)
[^141]: 빅테크와 AI 패권 추구. (2023년 3월 26일)
[^142]: Fung, Brian. AI 패권 전쟁의 승부처. (2023년 12월 19일)
[^143]: Metz, Cade. AI 시대, 기술 업계의 소기업들에게는 큰 우군이 필요하다. (2023년 7월 5일)
[^144]: 전력 2024 – 분석. (2024년 1월 24일)
[^145]: Calvert, Brian. AI는 이미 소규모 국가만큼의 에너지를 사용한다. 이것은 시작에 불과하다.. (2024년 3월 28일)
[^146]: Halper, Evan. AI가 전력망을 고갈시키고 있다. 기술 기업들은 기적의 해결책을 찾고 있다.. (2024년 6월 21일)
[^147]: Davenport, Carly. AI 데이터 센터와 다가오는 미국 전력 수요 급증
[^148]: Ryan, Carol. 에너지 다소비 AI는 에너지 절약의 미래이기도 하다. Dow Jones. (2024년 4월 12일)
[^149]: Hiller, Jennifer. 기술 업계, AI를 위해 원자력 에너지 확보 경쟁. Dow Jones. (2024년 7월 1일)
[^150]: Kendall, Tyler. 엔비디아의 황, 데이터 센터 전력 공급을 위해 원자력도 선택지라고 밝혀. (2024년 9월 28일)
[^151]: Halper, Evan. 마이크로소프트 계약으로 스리마일 아일랜드 원전 재가동, AI 전력 공급. (2024년 9월 20일)
[^152]: Hiller, Jennifer. 스리마일 아일랜드 원전 재가동, 마이크로소프트 AI 센터에 전력 공급 예정. Dow Jones. (2024년 9월 20일)
[^153]: 에너지와 AI 요약
[^154]: Rainie, Lee. 미국의 신뢰와 불신. (2019년 7월 22일)
[^155]: Kosoff, Maya. 유튜브, 음모론 문제 해결에 고전. (2018년 2월 8일)
[^156]: Berry, David M.. 합성 미디어와 계산 자본주의: 인공지능의 비판 이론을 향하여. (2025년 3월 19일)
[^157]: , . 비현실: AI 비디오의 양자적 도약. (2025년 6월 17일)
[^158]: Snow, Jackie. AI 비디오가 실제에 가까워지고 있다. 다음에 올 것을 경계하라. (2025년 6월 16일)
[^159]: Chow, Andrew R.. 구글의 새 AI 도구, 폭동·분쟁·선거 부정 등의 설득력 있는 딥페이크 생성. (2025년 6월 3일)
[^160]: Olanipekun, Samson Olufemi. 계산적 선전과 허위정보: 미디어 조작 도구로서의 AI 기술. (2025)
[^161]: Lin, Hause. 인간-인공지능 대화를 통한 유권자 설득. (2025)
[^162]: AI에 대항하려면 '개인 신원 자격증'이 필요하다고 AI 기업들이 주장. (2024년 9월 3일)
[^163]: Mazeika, Mantas. 유틸리티 공학: AI에서 창발적 가치 체계의 분석과 제어. (2025)
[^164]: Harvtxt Berdahl Baker Mann Osoba 2023 ; Harvtxt Goffrey 2008 p=17 ; Harvtxt Rose 2023 ; Harvtxt Russell Norvig 2021 p=995
[^165]: Harvtxt Christian 2020 pp=67–70 ; Harvtxt Russell Norvig 2021 pp=993–994
[^166]: Harvtxt Russell Norvig 2021 p=995 ; Harvtxt Lipartito 2011 p=36 ; Harvtxt Goodman Flaxman 2017 p=6 ; Harvtxt Christian 2020 pp=39–40, 65
[^167]: 인용: Harvtxt Christian 2020 p=65 .
[^168]: Harvtxt Russell Norvig 2021 p=994 ; Harvtxt Christian 2020 pp=40, 80–81
[^169]: 인용: Harvtxt Christian 2020 p=80
[^170]: Hundt, Andrew. 로봇이 악의적 고정관념을 실행한다. Association for Computing Machinery. (2022년 6월 21–24일)
[^171]: 결함 있는 AI가 로봇을 인종차별적, 성차별적으로 만든다. (2022년 6월 23일)
[^172]: 연구 결과, 결함 있는 AI로 인해 로봇이 인종차별적·성차별적으로 변한다. (2022년 6월 21일)
[^173]: 블랙박스 AI. (2023년 6월 16일)
[^174]: Harvtxt Christian 2020 p=83 ; Harvtxt Russell Norvig 2021 p=997
[^175]: Ropek, Lucas. 새로운 Anthropic 연구가 AI의 '블랙박스'에 빛을 비추다. (2024년 5월 21일)
[^176]: Harvtxt Robitzski 2018 ; Harvtxt Sainato 2015
[^177]: Buckley, Chris. 중국이 첨단 기술 감시로 소수민족을 억압하는 방법. (2019년 5월 22일)
[^178]: Whittaker, Zack. 보안 결함으로 중국 스마트 시티 감시 시스템 노출. (2019년 5월 3일)
[^179]: Harvtxt Ford Colvin 2015 ; Harvtxt McGaughey 2022
[^180]: Harvtxt Lohr 2017 ; Harvtxt Frey Osborne 2017 ; Harvtxt Arntz Gregory Zierahn 2016 p=33
[^181]: Zhou, Viola. AI가 이미 중국 비디오 게임 일러스트레이터의 일자리를 빼앗고 있다. (2023년 4월 11일)
[^182]: Carter, Justin. 중국 게임 아트 산업, 늘어나는 AI 사용으로 심각한 타격. (2023년 4월 11일)
[^183]: Harvtxt Mahdawi 2017 ; Harvtxt Thompson 2014
[^184]: Ma, Jason. 포드 CEO 짐 팔리, AI가 사무직 일자리의 절반을 없앨 것이라 경고하나 '필수 경제'에는 인력 부족 심각. (2025년 7월 5일)
[^185]: Tarnoff, Ben. 엘리자에서 얻은 교훈. (2023년 8월 4일)
[^186]: Harvtxt Bostrom 2014 ; Harvtxt Müller Bostrom 2014 ; Harvtxt Bostrom 2015 .
[^187]: 2015년경 AI의 실존적 위험에 대한 지도자들의 우려: Harvtxt Rawlinson 2015 , Harvtxt Holley 2015 , Harvtxt Gibbs 2014 , Harvtxt Sainato 2015
[^188]: "인공지능의 대부"가 새로운 AI의 영향과 잠재력에 대해 이야기하다. (2023년 3월 25일)
[^189]: Pittis, Don. 캐나다 인공지능 선구자 제프리 힌턴, 컴퓨터 지배에 대한 우려 가중. (2023년 5월 4일)
[^190]: AI가 인류를 능가할 확률 '50대 50'이라고 제프리 힌턴 밝혀. (2024년 6월 14일)
[^191]: Taylor, Josh. 인공지능의 부상은 불가피하지만 두려워할 필요는 없다고 'AI의 아버지' 밝혀. (2023년 5월 7일)
[^192]: Colton, Emma. 'AI의 아버지', 기술에 대한 두려움은 잘못된 것: '멈출 수 없다'. (2023년 5월 7일)
[^193]: Jones, Hessie. 저명한 '현대 AI의 아버지' 위르겐 슈미트후버, 자신의 평생 연구가 디스토피아로 이어지지 않을 것이라고 밝혀. (2023년 5월 23일)
[^194]: McMorrow, Ryan. 앤드류 응: '세계는 더 많은 지능이 있는 것이 나은가, 적은 것이 나은가?'. (2023년 12월 19일)
[^195]: 제프리 힌턴이 자신이 만드는 데 기여한 기술을 왜 이제 두려워하는지 이야기하다. (2023년 5월 2일)
[^196]: Levy, Steven. 얀 르쿤과 함께하는, AI에 대해 어리석어지지 않는 법. (2023년 12월 22일)
[^197]: AI가 임박한 위험이 아니라는 주장: Harvtxt Brooks 2014 , Harvtxt Geist 2015 , Harvtxt Madrigal 2015 , Harvtxt Lee 2014
[^198]: Stewart, Ashley. 허깅페이스 CEO, 45억 달러 규모의 오픈소스 AI 스타트업을 위한 '지속 가능한 모델' 구축에 집중한다고 밝혀
[^199]: Wiggers, Kyle. 구글, AI 모델 개발 지원 도구를 오픈소스로 공개. (2024년 4월 9일)
[^200]: Heaven, Will Douglas. 오픈소스 AI 붐은 빅테크의 지원 위에 세워졌다. 얼마나 오래 지속될까?. (2023년 5월 12일)
[^201]: Brodsky, Sascha. Mistral AI의 새로운 언어 모델, 오픈소스 최강을 목표로. (2023년 12월 19일)
[^202]: Edwards, Benj. Stability, 차세대 AI 이미지 생성기 Stable Diffusion 3 발표. (2024년 2월 22일)
[^203]: Marshall, Matt. 기업들이 오픈소스 LLM을 활용하는 방법: 16가지 사례. (2024년 1월 29일)
[^204]: Piper, Kelsey. 가장 강력한 AI 모델을 모두에게 오픈소스로 공개해야 하는가?. (2024년 2월 2일)
[^205]: 인공지능 윤리 및 안전 이해. (2019)
[^206]: 실천적 AI 윤리와 거버넌스. (2023)
[^207]: Floridi, Luciano. 사회에서의 AI를 위한 5가지 원칙의 통합 프레임워크. (2019년 6월 23일)
[^208]: Buruk, Banu. 책임 있고 신뢰할 수 있는 인공지능을 위한 지침에 대한 비판적 관점. (2020년 9월 1일)
[^209]: Kamila, Manoj Kumar. 인공지능 개발의 윤리적 문제: 위험 인식. (2023년 1월 1일)
[^210]: AI 안전 연구소, 새로운 AI 안전 평가 플랫폼 공개. 영국 정부. (2024년 5월 10일)
[^211]: 위험 완화를 위한 AI 규제: Harvtxt Berryhill Heang Clogher McBride 2019 , Harvtxt Barfield Pagallo 2018 , Harvtxt Iphofen Kritikos 2019 , Harvtxt Wirtz Weyerer Geyer 2018 , Harv
[^212]: n.a.. 유엔, 인공지능 자문기구 설립 발표. (2023년 10월 25일)
[^213]: AI법 발효
[^214]: 유럽평의회, 사상 최초의 AI 관련 글로벌 조약 서명 개방. (2024년 9월 5일)
[^215]: Milmo, Dan. 희망인가 공포인가? 선구자들을 갈라놓는 AI 대논쟁. (2023년 11월 3일)
[^216]: 2023년 11월 1–2일 AI 안전 정상회의 참석국들의 블레츨리 선언. (2023년 11월 1일)
[^217]: 각국, 역사적인 블레츨리 선언으로 최첨단 AI의 안전하고 책임 있는 개발에 합의
[^218]: 제2차 글로벌 AI 정상회의, 기업들로부터 안전 약속 확보. Reuters. (2024년 5월 21일)
[^219]: 최첨단 AI 안전 약속, 2024 AI 서울 정상회의. gov.uk. (2024년 5월 21일)
[^220]: cite web url = https://news.un.org/en/story/2026/03/1167075 title = 유엔, 인공지능에 관한 독립 과학 패널 출범 publisher = [[UN News]] date = 20
[^221]: 구글 북스 엔그램
[^222]: AI의 직접적 선구자들: Harvtxt McCorduck 2004 pp=51–107 , Harvtxt Crevier 1993 pp=27–32 , Harvtxt Russell Norvig 2021 pp=8–17 , Harvtxt Moravec 1988 p=3
[^223]: Harvtxt Simon 1965 p=96 인용: Harvtxt Crevier 1993 p=109
[^224]: Harvtxt Minsky 1967 p=2 인용: Harvtxt Crevier 1993 p=109
[^225]: [[전문가 시스템]]: Harvtxt Russell Norvig 2021 pp=23, 292 , Harvtxt Luger Stubblefield 2004 pp=227–331 , Harvtxt Nilsson 1998 loc=chpt. 17.4 , Harvtxt McCorduck 2004 pp=327–335, 434–435 ,
[^226]: [[발달 로봇공학]]: Harvtxt Weng McClelland Pentland Sporns 2001 , Harvtxt Lungarella Metta Pfeifer Sandini 2003 , Harvtxt Asada Hosoda Kuniyoshi Ishiguro 2009 , Harvtxt Oudeyer 201
[^227]: Harvtxt Crevier 1993 pp=214–215 , Harvtxt Russell Norvig 2021 pp=24, 26
[^228]: 1990년대 후반 AI의 광범위한 활용: Harvtxt Kurzweil 2005 p=265 , Harvtxt NRC 1999 pp=216–222 , Harvtxt Newquist 1994 pp=189–201
[^229]: [[무어의 법칙]]과 AI: Harvtxt Russell Norvig 2021 pp=14, 27
[^230]: [[빅데이터]]: Harvtxt Russell Norvig 2021 p=26
[^231]: Sagar, Ram. OpenAI, 역대 최대 모델 GPT-3 공개. (2020년 6월 3일)
[^232]: Milmo, Dan. ChatGPT, 출시 2개월 만에 1억 사용자 돌파. (2023년 2월 2일)
[^233]: Gorichanaz, Tim. ChatGPT 1주년: AI 챗봇의 성공은 기술만큼이나 인간에 대해 많은 것을 말해준다. (2023년 11월 29일)
[^234]: 신규 스타트업 4개 중 1개가 AI 기업. (2024년 12월 24일)
[^235]: Grayling, Anthony. AI 시대에 철학은 필수적이다. (2024년 8월 1일)
[^236]: McCarthy, John. AI의 철학과 철학의 AI
[^237]: Kirk-Giannini, Cameron Domenico. AI가 '지능'에 대한 튜링 테스트 통과에 그 어느 때보다 가까워졌다. 통과하면 어떻게 되는가?. (2023년 10월 16일)
[^238]: Suchman, Lucy. AI의 논쟁의 여지 없는 '사물성'
[^239]: Rehak, Rainer. 2025 ACM 공정성, 책임성, 투명성 컨퍼런스 논문집. (2025)
[^240]: Musser, George. AI는 어떻게 아무도 가르쳐주지 않은 것을 아는가. (2023년 9월 1일)
[^241]: AI인가 허풍인가? 마케팅 도구가 진짜 인공지능을 사용하는지 구별하는 방법. (2023년 3월 30일)
[^242]: 정보기술 - 인공지능 - 인공지능 개념 및 용어. BSI 영국 표준
[^243]: 규정 - EU - 2024/1689 - EN
[^244]: Tabassi, Elham. 인공지능 위험 관리 프레임워크 (AI RMF 1.0). 미국 국립표준기술연구소(NIST). (2023년 1월 26일)
[^245]: 물리적 기호 시스템 가설: Harvtxt Newell Simon 1976 p=116
역사적 의의: Harvtxt McCorduck 2004 p=153 , Harvtxt Russell Norvig 2021 p=19
[^246]: [[모라벡의 역설]]: Harvtxt Moravec 1988 pp=15–16 , Harvtxt Minsky 1986 p=29 , Harvtxt Pinker 2007 pp=190–191
[^247]: [[드레이퍼스의 AI 비판]]: Harvtxt Dreyfus 1972 , Harvtxt Dreyfus Dreyfus 1986
역사적 의의와 철학적 함의: Harvtxt Crevier 1993 pp=120–132 , Harvtxt McCorduck
[^248]: [[깔끔파 대 지저분파]], 역사적 논쟁: Harvtxt McCorduck 2004 pp=421–424, 486–489 , Harvtxt Crevier 1993 p=168 , Harvtxt Nilsson 1983 pp=10–11 , Harvtxt Russell Norvig 2021 p=24
A
[^249]: Searle의 [[중국어 방]] 논증: Harvtxt Searle 1980 . Searle의 사고 실험 원본 제시., Harvtxt Searle 1999 . 논의: Harvtxt Russell Norvig 2021 pp=985 , H
[^250]: Leith, Sam. 닉 보스트롬: 기계가 의식이 없다고 어떻게 확신할 수 있는가?. (2022년 7월 7일)
[^251]: Wong, Jeff. 리더들이 로봇 권리에 대해 알아야 할 것. (2023년 7월 10일)
[^252]: Hern, Alex. 로봇에게 '법적 인격' 지위를 부여하라고 EU 위원회 주장. (2017년 1월 12일)
[^253]: Dovey, Dana. 전문가들, 로봇에게 권리를 부여해서는 안 된다고 주장. (2018년 4월 14일)
[^254]: Cuddy, Alice. 로봇 권리는 인권을 침해한다고 전문가들이 EU에 경고. (2018년 4월 13일)
[^255]: [[지능 폭발]]과 [[기술적 특이점]]: Harvtxt Russell Norvig 2021 pp=1004–1005 , Harvtxt Omohundro 2008 , Harvtxt Kurzweil 2005
[[I. J. Good]]의 "지능 폭
[^256]: [[트랜스휴머니즘]]: Harvtxt Moravec 1988 , Harvtxt Kurzweil 2005 , Harvtxt Russell Norvig 2021 p=1005
[^257]: 진화로서의 AI: [[Edward Fredkin]]의 인용: Harvtxt McCorduck 2004 p=401 , Harvtxt Butler 1863 , Harvtxt Dyson 1998