역전파
기계 학습에서 역전파(backpropagation)는 매개변수 갱신을 계산할 때 신경망을 훈련시키는 데 흔히 사용되는 기울기 계산 방법이다.
이는 연쇄 법칙을 신경망에 효율적으로 적용한 것이다. 역전파는 단일 입력-출력 예시에 대해 네트워크의 가중치에 관한 손실 함수의 기울기를 계산하며, 이를 효율적으로 수행한다. 기울기를 한 번에 한 층씩 계산하면서 마지막 층에서부터 역방향으로 반복하여 연쇄 법칙의 중간 항에 대한 중복 계산을 피하는데, 이는 동적 프로그래밍을 통해 유도할 수 있다.[^1][^2]
엄밀히 말하면, 역전파라는 용어는 기울기를 효율적으로 계산하는 알고리즘만을 가리키며, 기울기가 어떻게 사용되는지는 포함하지 않는다. 그러나 이 용어는 흔히 전체 학습 알고리즘을 가리키는 데 느슨하게 사용된다. 여기에는 확률적 경사 하강법과 같이 기울기의 음의 방향으로 모델 매개변수를 변경하는 것이나, 적응적 모멘트 추정과 같은 더 복잡한 최적화기의 중간 단계로 사용하는 것이 포함된다.[^26]
역전파는 여러 차례 발견 및 부분적 발견이 이루어졌으며, 복잡하게 얽힌 역사와 용어를 가지고 있다. 자세한 내용은 역사 항목을 참조하라. 이 기법의 다른 명칭으로는 "자동 미분의 역방향 모드" 또는 "역방향 누적"이 있다.[^3]
개요
역전파는 손실 함수에 대한 순방향 신경망의 가중치 공간에서의 기울기를 계산한다. 다음과 같이 표기한다:
- x: 입력 (특성 벡터)
- y: 목표 출력 *:분류의 경우, 출력은 클래스 확률의 벡터(예: (0.1, 0.7, 0.2))이며, 목표 출력은 원-핫/더미 변수로 인코딩된 특정 클래스이다(예: (0, 1, 0)).
- C: 손실 함수 또는 "비용 함수" *:분류의 경우 일반적으로 교차 엔트로피(XC, 로그 손실)를 사용하며, 회귀의 경우 일반적으로 제곱 오차 손실(SEL)을 사용한다.
- L: 층의 수
- W^l = (w^l_{jk}): 층 l - 1과 l 사이의 가중치, 여기서 w^l_{jk}는 층 l - 1의 k번째 노드와 층 l의 j번째 노드 사이의 가중치이다
- f^l: 층 l에서의 활성화 함수 *:분류의 경우 마지막 층은 일반적으로 이진 분류에서는 로지스틱 함수를, 다중 클래스 분류에서는 소프트맥스(소프트아그맥스)를 사용하며, 은닉층의 경우 전통적으로 각 노드(좌표)에 대해 시그모이드 함수(로지스틱 함수 또는 기타)를 사용했으나, 오늘날에는 더 다양하며 정류기(램프, ReLU)가 흔히 사용된다.
- a^l_j: 층 l에서 j번째 노드의 활성화.
역전파의 유도에서는 아래에서 필요에 따라 도입하는 다른 중간 변수들이 사용된다. 편향 항은 고정 입력 1을 갖는 가중치에 해당하므로 특별히 취급하지 않는다. 역전파에서 특정 손실 함수와 활성화 함수는 해당 함수와 그 도함수를 효율적으로 계산할 수 있는 한 중요하지 않다. 전통적인 활성화 함수로는 시그모이드, tanh, ReLU가 있다. Swish,[^27] Mish,[^28] 및 기타 다수가 있다.
전체 네트워크는 함수 합성과 행렬 곱셈의 조합이다: g(x) := f^L(W^L f^{L-1}(W^{L-1} \cdots f^1(W^1 x)\cdots))
훈련 집합에는 입력-출력 쌍의 집합 \left{(x_i, y_i)\right}이 있다. 훈련 집합의 각 입력-출력 쌍 (x_i, y_i)에 대해, 해당 쌍에서의 모델 손실은 예측 출력 g(x_i)과 목표 출력 y_i 사이의 차이에 대한 비용이다: C(y_i, g(x_i))
구분에 유의해야 한다: 모델 평가 시에는 가중치가 고정되고 입력이 변하며(목표 출력은 알 수 없을 수 있음), 네트워크는 출력층에서 끝난다(손실 함수를 포함하지 않는다). 모델 훈련 시에는 입력-출력 쌍이 고정되고 가중치가 변하며, 네트워크는 손실 함수에서 끝난다.
역전파는 고정된 입력-출력 쌍 (x_i, y_i)에 대한 기울기를 계산하며, 여기서 가중치 w^l_{jk}는 변할 수 있다. 기울기의 각 개별 성분 \partial C/\partial w^l_{jk},은 연쇄 법칙으로 계산할 수 있지만, 각 가중치에 대해 이를 개별적으로 수행하는 것은 비효율적이다. 역전파는 중복 계산을 피하고 불필요한 중간값을 계산하지 않음으로써 기울기를 효율적으로 계산하며, 각 층의 기울기 — 구체적으로 각 층의 가중 입력의 기울기로 \delta^l로 표기 — 를 뒤에서 앞으로 계산한다.
비공식적으로 핵심은, W^l의 가중치가 손실에 영향을 미치는 유일한 경로가 다음 층을 통해서이며 그것이 선형적으로 이루어지므로, \delta^l이 층 l에서 가중치의 기울기를 계산하는 데 필요한 유일한 데이터이고, 그다음 이전 층의 가중치 기울기는 \delta^{l-1}로 계산할 수 있으며 이를 재귀적으로 반복할 수 있다는 것이다. 이는 두 가지 측면에서 비효율을 방지한다. 첫째, 층 l에서의 기울기를 계산할 때 매번 이후 층 l+1, l+2, \ldots의 모든 도함수를 다시 계산할 필요가 없으므로 중복을 방지한다. 둘째, 각 단계에서 은닉층 값의 가중치 변화에 대한 도함수 \partial a^{l'}{j'}/\partial w^l{jk}를 불필요하게 계산하지 않고, 최종 출력(손실)에 대한 가중치의 기울기를 직접 계산하므로 불필요한 중간 계산을 방지한다.
역전파는 단순 순방향 네트워크의 경우 행렬 곱셈으로, 또는 보다 일반적으로 수반 그래프의 관점에서 표현할 수 있다.
행렬 곱셈
각 층의 노드가 바로 다음 층의 노드에만 연결되고(어떤 층도 건너뛰지 않는), 최종 출력에 대해 스칼라 손실을 계산하는 손실 함수가 있는 순방향 신경망의 기본적인 경우, 역전파는 단순히 행렬 곱셈으로 이해할 수 있다. 본질적으로 역전파는 비용 함수의 도함수에 대한 표현식을 각 층 사이의 도함수의 곱으로 오른쪽에서 왼쪽으로 – "역방향으로" – 평가하며, 각 층 사이의 가중치의 기울기는 부분곱("역방향으로 전파된 오차")의 간단한 변형이다.
입력-출력 쌍 (x, y)가 주어졌을 때, 손실은 다음과 같다:
C(y, f^L(W^L f^{L-1}(W^{L-1} \cdots f^2(W^2 f^1(W^1 x))\cdots)))
이를 계산하기 위해, 입력 x에서 시작하여 순방향으로 진행한다; 각 은닉층의 가중 입력을 z^l로, 은닉층 l의 출력을 활성화 a^l로 표기한다. 역전파를 위해, 활성화 a^l과 도함수 (f^l)'(z^l에서 평가된)은 역방향 전달 중에 사용하기 위해 캐시에 저장되어야 한다.
입력에 대한 손실의 도함수는 연쇄 법칙에 의해 주어진다; 각 항은 입력 x에 대한 신경망의 값(각 노드에서)에서 평가된 전미분임에 주의하라:
\frac{d C}{d a^L}\cdot \frac{d a^L}{d z^L} \cdot \frac{d z^L}{d a^{L-1}} \cdot \frac{d a^{L-1}}{d z^{L-1}}\cdot \frac{d z^{L-1}}{d a^{L-2}} \cdot \ldots \cdot \frac{d a^1}{d z^1} \cdot \frac{\partial z^1}{\partial x}, 여기서 \frac{d a^L}{d z^L}는 대각 행렬이다.
이 항들은 다음과 같다: 손실 함수의 도함수; 활성화 함수의 도함수; 그리고 가중치 행렬: \frac{d C}{d a^L}\circ (f^L)' \cdot W^L \circ (f^{L-1})' \cdot W^{L-1} \circ \cdots \circ (f^1)' \cdot W^1.
기울기 \nabla는 입력에 대한 출력의 도함수의 전치이므로, 행렬은 전치되고 곱셈 순서는 역전되지만, 항목들은 동일하다: \nabla_x C = (W^1)^T \cdot (f^1)' \circ \ldots \circ (W^{L-1})^T \cdot (f^{L-1})' \circ (W^L)^T \cdot (f^L)' \circ \nabla_{a^L} C.
역전파는 본질적으로 이 표현식을 오른쪽에서 왼쪽으로 평가하는 것(동등하게, 도함수에 대한 앞선 표현식을 왼쪽에서 오른쪽으로 곱하는 것)으로 구성되며, 진행하면서 각 층에서 기울기를 계산한다; 가중치의 기울기는 단순한 부분 표현식이 아니라 추가적인 곱셈이 있기 때문에 추가 단계가 있다.
부분곱(오른쪽에서 왼쪽으로 곱한 것)에 대한 보조 변수 \delta^l을 도입하면, 이는 "층 l에서의 오차"로 해석되며 층 l에서의 입력 값의 기울기로 정의된다: \delta^l := (f^l)' \circ (W^{l+1})^T\cdot(f^{l+1})' \circ \cdots \circ (W^{L-1})^T \cdot (f^{L-1})' \circ (W^L)^T \cdot (f^L)' \circ \nabla_{a^L} C. \delta^l은 층 l의 노드 수와 같은 길이의 벡터임에 주의하라; 각 성분은 "해당 노드의 (값에) 귀속되는 비용"으로 해석된다.
층 l에서 가중치의 기울기는 다음과 같다: \nabla_{W^l} C = \delta^l(a^{l-1})^T. a^{l-1} 인수가 존재하는 이유는 층 l - 1과 l 사이의 가중치 W^l이 입력(활성화)에 비례하여 층 l에 영향을 미치기 때문이다: 입력은 고정되어 있고, 가중치가 변한다.
\delta^l은 오른쪽에서 왼쪽으로 진행하며 다음과 같이 쉽게 재귀적으로 계산할 수 있다: \delta^{l-1} := (f^{l-1})' \circ (W^l)^T \cdot \delta^l.
따라서 가중치의 기울기는 각 층에 대해 몇 번의 행렬 곱셈으로 계산할 수 있다; 이것이 역전파이다.
순진하게 순방향으로 계산하는 것과 비교하면(설명을 위해 \delta^l을 사용):
\begin{align} \delta^1 &= (f^1)' \circ (W^2)^T \cdot (f^2)' \circ \cdots \circ (W^{L-1})^T \cdot (f^{L-1})' \circ (W^L)^T \cdot (f^L)' \circ \nabla_{a^L} C\ \delta^2 &= (f^2)' \circ \cdots \circ (W^{L-1})^T \cdot (f^{L-1})' \circ (W^L)^T \cdot (f^L)' \circ \nabla_{a^L} C\ &\vdots\ \delta^{L-1} &= (f^{L-1})' \circ (W^L)^T \cdot (f^L)' \circ \nabla_{a^L} C\ \delta^L &= (f^L)' \circ \nabla_{a^L} C, \end{align}
역전파와의 두 가지 핵심적인 차이점이 있다:
- \delta^l을 이용하여 \delta^{l-1}을 계산하면 층 l 이후의 명백한 중복 곱셈을 피할 수 있다.
- \nabla_{a^L} C에서 시작하여 곱하는 것 – 오차를 역방향으로 전파하는 것 – 은 각 단계가 단순히 벡터(\delta^l)에 가중치 행렬 (W^l)^T과 활성화의 도함수 (f^{l-1})'를 곱하는 것을 의미한다. 반면에, 이전 층의 변화에서 시작하여 순방향으로 곱하는 것은 각 곱셈이 행렬에 행렬을 곱하는 것을 의미한다. 이는 훨씬 더 비용이 크며, 한 층 l에서의 변화가 층 l+2의 변화로 이어지는 모든 가능한 경로를 추적하는 것에 해당한다(W^{l+1}에 W^{l+2}를 곱하는 것과, 활성화의 도함수에 대한 추가 곱셈을 포함하며), 이는 가중치 변화가 은닉 노드의 값에 어떻게 영향을 미치는지에 대한 중간 양을 불필요하게 계산하는 것이다.
수반 그래프
보다 일반적인 그래프 및 기타 고급 변형의 경우, 역전파는 자동 미분의 관점에서 이해할 수 있으며, 역전파는 역방향 누적(또는 "역방향 모드")의 특수한 경우이다.[^3]
직관
동기
지도 학습 알고리즘의 목표는 입력 집합을 올바른 출력에 가장 잘 매핑하는 함수를 찾는 것이다. 역전파의 동기는 다층 신경망을 훈련시켜 입력에서 출력으로의 임의의 매핑을 학습할 수 있도록 적절한 내부 표현을 학습하게 하는 것이다.[^4]
최적화 문제로서의 학습
역전파 알고리즘의 수학적 유도를 이해하려면, 먼저 뉴런의 실제 출력과 특정 훈련 예제에 대한 올바른 출력 사이의 관계에 대한 직관을 발전시키는 것이 도움이 된다. 두 개의 입력 유닛, 하나의 출력 유닛, 그리고 은닉 유닛이 없는 간단한 신경망을 생각해 보자. 이 신경망에서 각 뉴런은 입력의 가중합인 선형 출력을 사용한다(입력에서 출력으로의 매핑이 비선형인 대부분의 신경망 연구와는 다르다).
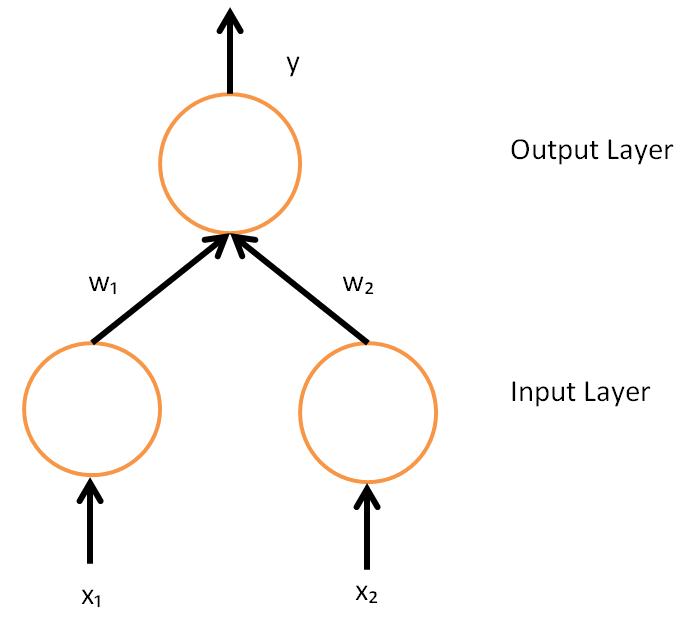
초기에는 훈련 전에 가중치가 무작위로 설정된다. 그런 다음 뉴런은 훈련 예제로부터 학습하는데, 이 경우 훈련 예제는 튜플 (x_1, x_2, t)의 집합으로 구성되며, 여기서 x_1과 x_2는 네트워크의 입력이고 는 올바른 출력(훈련이 완료되었을 때 해당 입력이 주어지면 네트워크가 생성해야 하는 출력)이다. 초기 네트워크는 x_1과 x_2가 주어지면 (무작위 가중치를 고려할 때) 와 다를 가능성이 높은 출력 를 계산한다. 손실 함수 L(t, y) 는 목표 출력 와 계산된 출력 사이의 불일치를 측정하는 데 사용된다. 회귀 분석 문제에는 제곱 오차를 손실 함수로 사용할 수 있고, 분류에는 범주형 교차 엔트로피를 사용할 수 있다.
예를 들어, 제곱 오차를 손실로 사용하는 회귀 문제를 생각해 보자: L(t, y)= (t-y)^2 = E,
여기서 는 불일치 또는 오차이다.
단일 훈련 사례 (1, 1, 0)에서의 네트워크를 생각해 보자. 따라서 입력 x_1과 x_2는 각각 1과 1이며, 올바른 출력 는 0이다. 이제 수평축에 네트워크의 출력 를, 수직축에 오차 를 놓고 그 관계를 그래프로 나타내면, 결과는 포물선이 된다. 포물선의 최솟값은 오차 를 최소화하는 출력 에 해당한다. 단일 훈련 사례의 경우, 최솟값은 수평축에도 접하는데, 이는 오차가 0이 되고 네트워크가 목표 출력 와 정확히 일치하는 출력 를 생성할 수 있음을 의미한다. 따라서 입력을 출력으로 매핑하는 문제는 최소 오차를 생성하는 함수를 찾는 최적화 문제로 축소될 수 있다.

그러나 뉴런의 출력은 모든 입력의 가중합에 의존한다:
y=x_1w_1 + x_2w_2,
여기서 w_1과 w_2는 입력 유닛에서 출력 유닛으로의 연결에 대한 가중치이다. 따라서 오차도 뉴런으로 들어오는 가중치에 의존하며, 이것이 궁극적으로 학습을 가능하게 하기 위해 네트워크에서 변경되어야 하는 것이다.
이 예에서 훈련 데이터 (1, 1, 0)를 주입하면 손실 함수는 다음과 같이 된다:
E = (t-y)^2 = y^2 = (x_1w_1 + x_2w_2)^2 = (w_1 + w_2)^2.
그러면 손실 함수 E는 밑면이 w_1 = -w_2 방향을 따르는 포물선 기둥의 형태를 취한다. w_1 = -w_2를 만족하는 모든 가중치 집합이 손실 함수를 최소화하므로, 이 경우 유일한 해에 수렴하려면 추가적인 제약 조건이 필요하다. 추가 제약 조건은 가중치에 특정 조건을 설정하거나 추가 훈련 데이터를 주입하여 생성할 수 있다.
오차를 최소화하는 가중치 집합을 찾기 위해 일반적으로 사용되는 알고리즘 중 하나는 경사 하강법이다. 역전파를 통해 현재 시냅스 가중치에 대한 손실 함수의 최급강하 방향이 계산된다. 그런 다음 최급강하 방향을 따라 가중치를 수정할 수 있으며, 이를 통해 오차가 효율적으로 최소화된다.
유도
경사 하강법은 네트워크의 가중치에 대한 손실 함수의 도함수를 계산하는 것을 포함한다. 이는 일반적으로 역전파를 사용하여 수행된다. 하나의 출력 뉴런을 가정하면, 제곱 오차 함수는 다음과 같다.
E = L(t, y)
여기서 L은 출력 y와 목표값 t에 대한 손실이고, t는 훈련 샘플에 대한 목표 출력이며, y는 출력 뉴런의 실제 출력이다.
이 절에서 가중치 인덱스의 순서는 이전 절과 반대이다: w_{ij}는 i번째 유닛에서 j번째 유닛으로의 가중치이다. 각 뉴런 j에 대해, 그 출력 o_j는 다음과 같이 정의된다.
o_j = \varphi(\text{net}j) = \varphi\left(\sum{k=1}^n w_{kj}x_k\right),
여기서 활성화 함수 \varphi는 비선형이고 활성화 영역에서 미분 가능하다(ReLU는 한 점에서 미분 불가능하다). 역사적으로 사용된 활성화 함수는 로지스틱 함수이다:
\varphi(z) = \frac 1 {1+e^{-z}}
이 함수의 도함수는 다음과 같은 편리한 형태를 가진다:
\frac {d \varphi}{d z} = \varphi(z)(1-\varphi(z))
뉴런의 입력 \text{net}j는 이전 뉴런들의 출력 o_k의 가중합이다. 뉴런이 입력층 바로 다음의 첫 번째 층에 있다면, 입력층의 o_k는 단순히 네트워크에 대한 입력 x_k이다. 뉴런에 대한 입력 유닛의 수는 n이다. 변수 w{kj}는 이전 층의 뉴런 k와 현재 층의 뉴런 j 사이의 가중치를 나타낸다.
오차의 도함수 구하기

가중치 w_{ij}에 대한 오차의 편도함수를 계산하는 것은 연쇄 법칙을 두 번 사용하여 수행된다:
위 식의 우변의 마지막 인수에서, 합 \text{net}j의 항 중 w{ij}에 의존하는 것은 하나뿐이므로
뉴런이 입력층 바로 다음의 첫 번째 층에 있다면, o_i는 단순히 x_i이다.
뉴런 j의 출력을 그 입력에 대해 미분한 것은 단순히 활성화 함수의 편도함수이다:
로지스틱 활성화 함수의 경우 \frac{\partial o_j}{\partial\text{net}_j} = \frac {\partial}{\partial \text{net}_j} \varphi(\text{net}_j) = \varphi(\text{net}_j)(1-\varphi(\text{net}_j)) = o_j(1-o_j)
이것이 역전파가 활성화 함수의 미분 가능성을 요구하는 이유이다. (그럼에도 불구하고, 0에서 미분 불가능한 ReLU 활성화 함수가 AlexNet 등에서 상당히 널리 사용되고 있다)
뉴런이 출력층에 있는 경우 첫 번째 인수는 간단히 계산할 수 있는데, 이때 o_j = y이고
손실 함수로 제곱 오차의 절반을 사용하면 다음과 같이 다시 쓸 수 있다.
\frac{\partial E}{\partial o_j} = \frac{\partial E}{\partial y} = \frac{\partial}{\partial y} \frac{1}{2}(t - y)^2 = y - t
그러나 j가 네트워크의 임의의 내부 층에 있다면, o_j에 대한 E의 도함수를 구하는 것은 덜 명확하다.
E를 뉴런 j로부터 입력을 받는 모든 뉴런 L = {u, v, \dots, w}을 입력으로 하는 함수로 간주하면,
\frac{\partial E(o_j)}{\partial o_j} = \frac{\partial E(\mathrm{net}_u, \text{net}_v, \dots, \mathrm{net}_w)}{\partial o_j}
o_j에 대한 전미분을 취하면, 도함수에 대한 재귀적 표현을 얻는다:
따라서 o_j에 대한 도함수는 다음 층 — 출력 뉴런에 더 가까운 층 — 의 출력 o_\ell에 대한 모든 도함수가 알려져 있으면 계산할 수 있다. [참고로, 집합 L의 뉴런 중 뉴런 j에 연결되지 않은 것이 있다면, 이들은 w_{ij}와 독립적이므로 합산 아래의 해당 편도함수는 0으로 소멸한다.]
, 그리고 을 에 대입하면 다음을 얻는다:
\frac{\partial E}{\partial w_{ij}} = \frac{\partial E}{\partial o_{j}} \frac{\partial o_{j}}{\partial \text{net}{j}} \frac{\partial \text{net}{j}}{\partial w_{ij}}
= \frac{\partial E}{\partial o_{j}} \frac{\partial o_{j}}{\partial \text{net}{j}} o_i \frac{\partial E}{\partial w{ij}} = o_i \delta_j
여기서
\delta_j = \frac{\partial E}{\partial o_j} \frac{\partial o_j}{\partial\text{net}j} = \begin{cases} \frac{\partial L(t, o_j)}{\partial o_j} \frac {d \varphi(\text{net}j)}{d \text{net}j} & \text{if } j \text{ 가 출력 뉴런인 경우,}\ (\sum{\ell\in L} w{j \ell} \delta\ell)\frac {d \varphi(\text{net}_j)}{d \text{net}_j} & \text{if } j \text{ 가 내부 뉴런인 경우.} \end{cases}
\varphi가 로지스틱 함수이고 오차가 제곱 오차인 경우:
\delta_j = \frac{\partial E}{\partial o_j} \frac{\partial o_j}{\partial\text{net}j} = \begin{cases} (o_j-t_j)o_j(1-o{j}) & \text{if } j \text{ 가 출력 뉴런인 경우,}\ (\sum_{\ell\in L} w_{j \ell} \delta_\ell)o_j(1-o_j) & \text{if } j \text{ 가 내부 뉴런인 경우.} \end{cases}
경사 하강법을 사용하여 가중치 w_{ij}를 갱신하려면, 학습률 \eta >0을 선택해야 한다. 가중치의 변화는 w_{ij}의 증가 또는 감소가 E에 미치는 영향을 반영해야 한다. \frac{\partial E}{\partial w_{ij}} > 0이면, w_{ij}의 증가는 E를 증가시킨다; 반대로, \frac{\partial E}{\partial w_{ij}} < 0이면, w_{ij}의 증가는 E를 감소시킨다. 새로운 \Delta w_{ij}는 이전 가중치에 더해지며, 학습률과 기울기의 곱에 -1을 곱하면 w_{ij}가 항상 E를 감소시키는 방향으로 변하도록 보장한다. 다시 말해, 바로 아래 수식에서 - \eta \frac{\partial E}{\partial w_{ij}}는 항상 w_{ij}를 E가 감소하는 방향으로 변화시킨다:
\Delta w_{ij} = - \eta \frac{\partial E}{\partial w_{ij}} = - \eta o_i \delta_j
2차 경사 하강법
오차 함수의 2차 도함수로 구성된 헤세 행렬을 사용하는 레벤버그-마쿼트 알고리즘은, 특히 오차 함수의 위상이 복잡한 경우 1차 경사 하강법보다 빠르게 수렴하는 경우가 많다.[^5][^6] 또한 다른 방법으로는 수렴하지 못할 수 있는 더 적은 노드 수에서도 해를 찾을 수 있다.[^6] 헤세 행렬은 피셔 정보 행렬로 근사할 수 있다.[^7]
예를 들어, 단순한 순방향 신경망을 생각해 보자. l번째 층에서 다음이 성립한다.x^{(l)}i, \quad a^{(l)}i = f(x^{(l)}i), \quad x^{(l+1)}i = \sum_j W{ij} a^{(l)}j여기서 x는 활성화 전 값, a는 활성화 값, W는 가중치 행렬이다. 손실 함수 L이 주어졌을 때, 1차 역전파는 다음과 같이 표현된다.\frac{\partial L}{\partial a_j^{(l)}} = \sum_j W{ij}\frac{\partial L}{\partial x_i^{(l+1)}}, \quad \frac{\partial L}{\partial x_j^{(l)}} = f'(x_j^{(l)})\frac{\partial L}{\partial a_j^{(l)}}그리고 2차 역전파는 다음과 같이 표현된다.\frac{\partial^2 L}{\partial a{j_1}^{(l)}\partial a{j_2}^{(l)}} = \sum{j_1j_2} W_{i_1j_1}W_{i_2j_2}\frac{\partial^2 L}{\partial x_{i_1}^{(l+1)}\partial x_{i_2}^{(l+1)}}, \quad \frac{\partial^2 L}{\partial x_{j_1}^{(l)}\partial x_{j_2}^{(l)}} = f'(x_{j_1}^{(l)}) f'(x_{j_2}^{(l)}) \frac{\partial^2 L}{\partial a_{j_1}^{(l)}\partial a_{j_2}^{(l)}} + \delta_{j_1 j_2} f''(x^{(l)}{j_1} ) \frac{\partial L}{\partial a{j_1}^{(l)}}여기서 \delta는 디랙 델타 기호이다.
임의의 계산 그래프에서 임의 차수의 도함수를 역전파로 계산할 수 있지만, 고차의 경우 수식이 더 복잡해진다.
손실 함수
손실 함수는 하나 이상의 변수 값을 해당 값과 관련된 일종의 "비용"을 직관적으로 나타내는 실수로 대응시키는 함수이다. 역전파에서 손실 함수는 훈련 예제가 신경망을 통해 전파된 후, 신경망의 출력과 기대 출력 사이의 차이를 계산한다.
가정
손실 함수의 수학적 표현이 역전파에 사용되려면 두 가지 조건을 충족해야 한다.[^29] 첫 번째는 n개의 개별 훈련 예제 x에 대한 오차 함수 E_x의 평균 E=\frac{1}{n}\sum_xE_x으로 쓸 수 있어야 한다는 것이다. 이 가정이 필요한 이유는 역전파 알고리즘이 단일 훈련 예제에 대한 오차 함수의 기울기를 계산하며, 이를 전체 오차 함수로 일반화해야 하기 때문이다. 두 번째 가정은 신경망의 출력값의 함수로 쓸 수 있어야 한다는 것이다.
손실 함수의 예
y,y'를 \mathbb{R}^n 공간의 벡터라 하자.
두 출력 간의 차이를 측정하는 오차 함수 E(y,y')를 선택한다. 표준적인 선택은 벡터 y와 y' 사이의 유클리드 거리의 제곱이다.E(y,y') = \tfrac{1}{2} \lVert y-y'\rVert^2n개의 훈련 예제에 대한 오차 함수는 개별 예제에 대한 손실의 평균으로 다음과 같이 쓸 수 있다.E=\frac{1}{2n}\sum_x\lVert (y(x)-y'(x)) \rVert^2
한계점

- 역전파를 이용한 경사 하강법은 오차 함수의 전역 최솟값을 찾는 것을 보장하지 않으며, 지역 최솟값만을 찾을 수 있다. 또한 오차 함수 지형의 평탄 구간을 횡단하는 데 어려움이 있다. 신경망에서 오차 함수의 비볼록성으로 인해 발생하는 이 문제는 오랫동안 주요 단점으로 여겨져 왔으나, Yann LeCun 등은 많은 실제 문제에서 이것이 큰 문제가 되지 않는다고 주장한다.[^30]
- 역전파 학습은 입력 벡터의 정규화를 필요로 하지 않지만, 정규화는 성능을 향상시킬 수 있다.[^31]
- 역전파는 네트워크 설계 시점에 활성화 함수의 도함수가 알려져 있어야 한다.
역사
선행 연구
역전파는 본질적으로 신경망에 연쇄 법칙(1676년 고트프리트 빌헬름 라이프니츠가 최초로 기술)[^8][^32]을 효율적으로 적용한 것이므로, 여러 차례 반복적으로 유도되었다.
"오류 역전파 보정"이라는 용어는 1962년 프랭크 로젠블랫에 의해 도입되었으나, 그는 이를 구현하는 방법을 알지 못했다.[^33] 어쨌든 그는 출력이 이산적 수준인 뉴런만을 연구했는데, 이러한 뉴런은 도함수가 0이므로 역전파가 불가능했다.
역전파의 선행 연구는 1950년대부터 최적 제어 이론에서 나타났다. 얀 르쿤 등은 최적 제어 이론에서의 1950년대 폰트랴긴 등의 연구, 특히 수반 상태 방법이 역전파의 연속 시간 버전이라고 평가하였다.[^34] 헤흐트닐센[^35]은 로빈스-먼로 알고리즘(1951)[^9]과 아서 브라이슨 및 유치 호의 응용 최적 제어(1969)를 역전파의 선구적 연구로 꼽았다. 그 밖의 선행 연구로는 헨리 J. 켈리(1960)[^1], 아서 E. 브라이슨(1961)이 있다.[^2] 1962년 스튜어트 드레이퍼스는 연쇄 법칙만을 기반으로 한 더 간단한 유도를 발표하였다.[^36][^10][^37] 1973년에 그는 오류 기울기에 비례하여 제어기의 매개변수를 조정하였다.[^11] 현대의 역전파와 달리, 이러한 선행 연구들은 한 단계에서 이전 단계로의 표준 야코비 행렬 계산을 사용하였으며, 여러 단계에 걸친 직접 연결이나 네트워크 희소성으로 인한 추가적인 효율성 향상은 다루지 않았다.[^12]
ADALINE(1960)의 학습 알고리즘은 단일 계층에 대한 제곱 오차 손실을 이용한 경사 하강법이었다. 확률적 경사 하강법[^9]으로 훈련된 최초의 다층 퍼셉트론(MLP)은 1967년 아마리 슌이치에 의해 발표되었다.[^13] 이 MLP는 5개의 계층과 2개의 학습 가능한 계층을 가졌으며, 선형 분리가 불가능한 패턴을 분류하는 법을 학습하였다.[^12]
현대의 역전파
현대의 역전파는 1970년 세포 린나인마에 의해 이산적으로 연결된 중첩 미분 가능 함수 네트워크에 대한 "자동 미분의 역방향 모드"로 최초 발표되었다.[^14][^15][^16][^17]
1982년 폴 워보스는 오늘날 표준이 된 방식으로 역전파를 MLP에 적용하였다.[^18][^19] 워보스는 인터뷰에서 역전파를 개발한 과정을 설명하였다. 1971년 박사 과정 중에 그는 프로이트의 "정신 에너지의 흐름"을 수학적으로 모형화하기 위해 역전파를 개발하였다. 그는 이 연구를 출판하는 데 반복적인 어려움을 겪었으며, 1981년에야 비로소 출판에 성공하였다.[^20] 그는 또한 "역전파의 최초 실용적 적용은 1974년 자신에 의해 민족주의와 사회적 소통을 예측하는 동적 모형을 추정한 것"이라고 주장하였다.[^38]
1982년경,[^20] 데이비드 E. 루멜하트는 독자적으로 역전파를 개발하고[^39] 자신의 연구 집단에 이 알고리즘을 가르쳤다. 그는 이전 연구를 알지 못했기 때문에 인용하지 않았다. 그는 1985년 논문에서 이 알고리즘을 처음 발표하였고, 이어 1986년 Nature 논문에서 이 기법의 실험적 분석을 발표하였다.[^21] 이 논문들은 높은 피인용 수를 기록하였으며, 역전파의 대중화에 기여하였고, 1980년대 신경망에 대한 연구 관심이 다시 높아지던 시기와 맞물렸다.[^4][^22][^40]
1985년에 데이비드 파커도 이 방법을 기술하였다.[^41][^23] 얀 르쿤은 1987년 박사 논문에서 신경망을 위한 역전파의 대안적 형태를 제안하였다.[^42]
경사 하강법이 수용되기까지는 상당한 시간이 걸렸다. 초기의 반대 의견으로는 다음과 같은 것들이 있었다: 경사 하강법이 전역 최솟값이 아닌 지역 최솟값에만 도달할 수 있다는 보장 문제, 생리학자들에 의해 뉴런은 연속적 신호가 아닌 이산적 신호(0/1)를 생성하는 것으로 "알려져" 있었으며 이산적 신호에서는 기울기를 구할 수 없다는 점이었다. 이 분야에 대한 공헌으로 2024년 노벨 물리학상을 수상한[^43] 제프리 힌턴의 인터뷰를 참조하라.[^20]
초기 성공 사례
역전파를 통한 신경망 훈련의 여러 응용 사례가 수용에 기여하였으며, 때로는 연구계를 넘어 대중적 인기를 얻기도 하였다.
1987년, NETtalk은 영어 텍스트를 발음으로 변환하는 법을 학습하였다. 세즈노프스키는 역전파와 볼츠만 머신 두 가지로 훈련을 시도하였으나, 역전파가 현저히 빠르다는 것을 발견하여 최종 NETtalk에 이를 사용하였다.[^20] NETtalk 프로그램은 투데이 쇼에 출연하는 등 대중적 성공을 거두었다.[^24]
1989년, 딘 A. 포머로는 역전파를 사용하여 훈련된 자율 주행 신경망인 ALVINN을 발표하였다.[^44]
LeNet은 1989년 손으로 쓴 우편번호를 인식하기 위해 발표되었다.
1992년, TD-Gammon은 백개먼에서 최고 수준의 인간 실력을 달성하였다. 이것은 역전파로 훈련된 2개의 계층을 가진 신경망을 사용한 강화 학습 에이전트였다.[^45]
1993년, 에릭 완은 역전파를 통해 국제 패턴 인식 대회에서 우승하였다.[^25][^46]
역전파 이후
2000년대에는 관심에서 멀어졌으나, 2010년대에 저렴하고 강력한 GPU 기반 컴퓨팅 시스템의 혜택을 받아 다시 부상하였다. 이는 특히 음성 인식, 기계 시각, 자연어 처리, 그리고 언어 구조 학습 연구에서 두드러졌다(이 분야에서 역전파는 제1언어[^47] 및 제2언어 학습[^48]과 관련된 다양한 현상을 설명하는 데 사용되었다).[^49]
오류 역전파는 N400 및 P600과 같은 인간 뇌의 사건 관련 전위(ERP) 성분을 설명하는 데에도 제안되었다.[^50]
2023년, 스탠퍼드 대학교의 연구팀이 광자 프로세서에서 역전파 알고리즘을 구현하였다.[^51]
같이 보기
- 인공 신경망
- 신경 회로
- 파국적 간섭
- 앙상블 학습
- 에이다부스트
- 과적합
- 신경 역전파
- 시간에 따른 역전파
- 구조를 통한 역전파
- 삼요인 학습
주석
더 읽을거리
-
-
-
-
외부 링크
-
-
-
- 위키배움터의 역전파 신경망 튜토리얼
참고 문헌
[^1]: Kelley, Henry J.. 최적 비행 경로의 경사 이론
[^2]: Bryson, Arthur E.. 하버드 대학교 디지털 컴퓨터 및 그 응용에 관한 심포지엄 회의록, 1961년 4월 3–6일. Harvard University Press
[^3]: harvtxt Goodfellow Bengio Courville 2016 p=[https://www.deeplearningbook.org/contents/mlp.html#pf36 217]–218 , "여기서 설명하는 역전파 알고리즘은 자동 미분에 대한 하나의 접근 방식일 뿐이다"
[^4]: Rumelhart, David E.. 오류 역전파를 통한 표현 학습. (1986a)
[^5]: Tan, Hong Hui. 인공 신경망 역전파에서의 2차 최적화 기법 검토
[^6]: Wiliamowski, Bogdan. 레벤버그-마쿼트 훈련의 개선된 계산. (2010년 6월)
[^7]: Martens, James. 자연 경사법에 대한 새로운 통찰과 관점. (2020년 8월)
[^8]: Leibniz, Gottfried Wilhelm Freiherr von. 라이프니츠의 초기 수학 원고: 카를 임마누엘 게르하르트가 출판한 라틴어 원문에서 번역, 비평 및 역사적 주석 포함 (라이프니츠는 1676년 논문에서 연쇄 법칙을 발표하였다). Open court publishing Company. (1920)
[^9]: Robbins, H.. 확률적 근사 방법
[^10]: Dreyfus, Stuart E.. 인공 신경망, 역전파, 그리고 켈리-브라이슨 경사 절차. (1990)
[^11]: Dreyfus, Stuart. 시간 지연이 있는 최적 제어 문제의 계산적 해법
[^12]: Schmidhuber, Jürgen. 현대 AI 및 딥러닝의 주석이 달린 역사. (2022)
[^13]: Amari, Shun'ichi. 적응형 패턴 분류기 이론. (1967)
[^14]: Linnainmaa, Seppo. 알고리즘의 누적 반올림 오차를 국소 반올림 오차의 테일러 전개로 표현. University of Helsinki
[^15]: Linnainmaa, Seppo. 누적 반올림 오차의 테일러 전개
[^16]: Griewank, Andreas. 최적화 이야기
[^17]: Griewank, Andreas. 도함수 평가: 알고리즘적 미분의 원리와 기법, 제2판. SIAM
[^18]: Werbos, Paul. 시스템 모델링과 최적화. Springer
[^19]: Werbos, Paul J.. 역전파의 뿌리: 순서 도함수에서 신경망 및 정치적 예측까지. John Wiley & Sons
[^20]: 대화하는 네트워크: 신경망의 구술 역사. The MIT Press. (2000)
[^21]: cite journal last1 = Rumelhart last2 = Hinton last3 = Williams title=오류 역전파를 통한 표현 학습 journal = Nature volume = 323 issue = 6088 pages = 533–536 ur
[^22]: Rumelhart, David E.. 병렬 분산 처리: 인지의 미세 구조 탐구. MIT Press
[^23]: Hertz, John. 신경 계산 이론 입문. Addison-Wesley. (1991)
[^24]: Sejnowski, Terrence J.. 딥러닝 혁명. The MIT Press. (2018)
[^25]: Schmidhuber, Jürgen. 신경망에서의 딥러닝: 개요
[^26]: harvnb Goodfellow Bengio Courville 2016 p=[https://www.deeplearningbook.org/contents/mlp.html#pf25 200] , "역전파라는 용어는 종종 전체 학습 알고리즘을 의미하는 것으로 오해된다"
[^27]: Ramachandran, Prajit. 활성화 함수 탐색. (2017-10-27)
[^28]: Misra, Diganta. Mish: 자기 정규화 비단조 활성화 함수. (2019-08-23)
[^29]: harvtxt Nielsen 2015 , "[역]전파가 적용되기 위해 비용 함수에 대해 어떤 가정이 필요한가? 첫 번째 가정은 비용 함수가 다음과 같이 쓸 수 있어야 한다는 것이다"
[^30]: LeCun, Yann. 딥러닝
[^31]: Buckland, Matt. 게임 프로그래밍을 위한 AI 기법. Premier Press
[^32]: Rodríguez, Omar Hernández. 연쇄 법칙 교수법에 대한 기호학적 고찰
[^33]: Rosenblatt, Frank. 신경 역학의 원리. Spartan, New York
[^34]: LeCun, Yann, et al. "역전파를 위한 이론적 프레임워크." ''1988년 커넥셔니스트 모델 여름 학교 회의록''. Vol. 1. 1988.
[^35]: Hecht-Nielsen, Robert. 신경 컴퓨팅. Reading, Mass. : Addison-Wesley Pub. Co.. (1990)
[^36]: Dreyfus, Stuart. 변분 문제의 수치적 해법
[^37]: Mizutani, Eiji. 켈리-브라이슨 최적 제어 경사 공식으로부터의 MLP 역전파 유도 및 그 응용. IEEE 국제 신경망 합동 학회 회의록. (2000년 7월)
[^38]: P. J. Werbos, "시간을 통한 역전파: 그것이 하는 일과 하는 방법," in Proceedings of the IEEE, vol. 78, no. 10, pp. 1550–1560, Oct. 1990, doi 10.1109/5.58337
[^39]: Olazaran Rodriguez, Jose Miguel. ''[https://web.archive.org/web/20221111165150/https://era.ed.ac.uk/bitstream/handle/1842/20075/Olazaran-RodriguezJM_1991redux.pdf?sequence=1&isAllowed=y 역사적 고찰]
[^40]: Alpaydin, Ethem. 기계 학습 입문. MIT Press
[^41]: Parker, D.B.. 학습 논리: 인간 두뇌의 피질을 실리콘에 주조하기. Massachusetts Institute of Technology. (1985)
[^42]: Le Cun, Yann. 학습의 커넥셔니스트 모델. Université Pierre et Marie Curie. (1987)
[^43]: 2024년 노벨 물리학상
[^44]: Pomerleau, Dean A.. ALVINN: 신경망 기반 자율 주행 차량. Morgan-Kaufmann. (1988)
[^45]: Sutton, Richard S.. 강화 학습: 입문. MIT Press
[^46]: Wan, Eric A.. 시계열 예측: 미래 예측과 과거 이해. Addison-Wesley
[^47]: Chang, Franklin. 구문적 존재가 되다.. (2006)
[^48]: Janciauskas, Marius. 제2언어 학습에서의 입력 및 연령 의존적 변이: 커넥셔니스트적 설명
[^49]: 역전파의 힘 해독: 고급 신경망 기법에 대한 심층 분석. (2024년 1월 30일)
[^50]: Fitz, Hartmut. 언어 ERP는 예측 오류 전파를 통한 학습을 반영한다. (2019)
관련 인사이트

공장의 뇌는 어떻게 생겼는가 — 제조운영 AI 아키텍처 해부
지식관리, 업무자동화, 의사결정지원 — 따로 보면 다 있던 것들입니다. 제조 AI의 진짜 차이는 이 셋이 순환하면서 '우리 공장만의 지능'을 만든다는 데 있습니다.

그 30분을 18년 동안 매일 반복했습니다 — 품질팀장이 본 AI Agent
18년차 품질팀장이 매일 아침 30분씩 반복하던 데이터 분석을 AI Agent가 3분 만에 해냈습니다. 챗봇과는 완전히 다른 물건 — 직접 시스템에 접근해서 데이터를 꺼내고 분석하는 AI의 현장 도입기.

ERP 20년, 나는 왜 AI를 얹기로 했나
ERP 20년차 제조IT본부장의 고백: 3,200만 행의 데이터가 잠들어 있었다. ERP를 바꾸지 않고 AI를 얹자, 일주일 걸리던 불량 분석이 수 초로 줄었다.